EAGLE-3 Speculative Decoding on AMD Instinct GPUs: Training and Serving with vLLM and AMD Quark
·13 min read
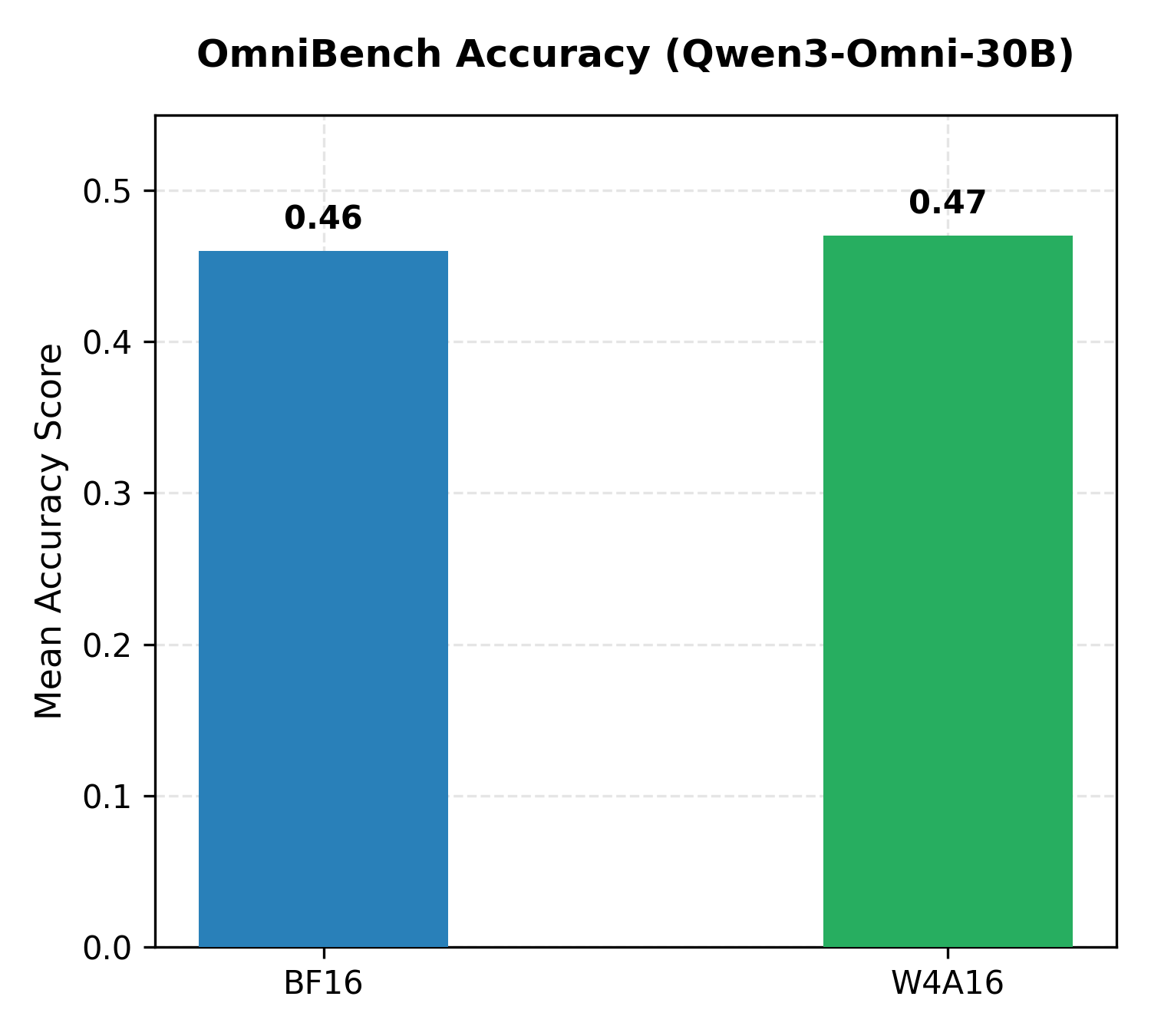
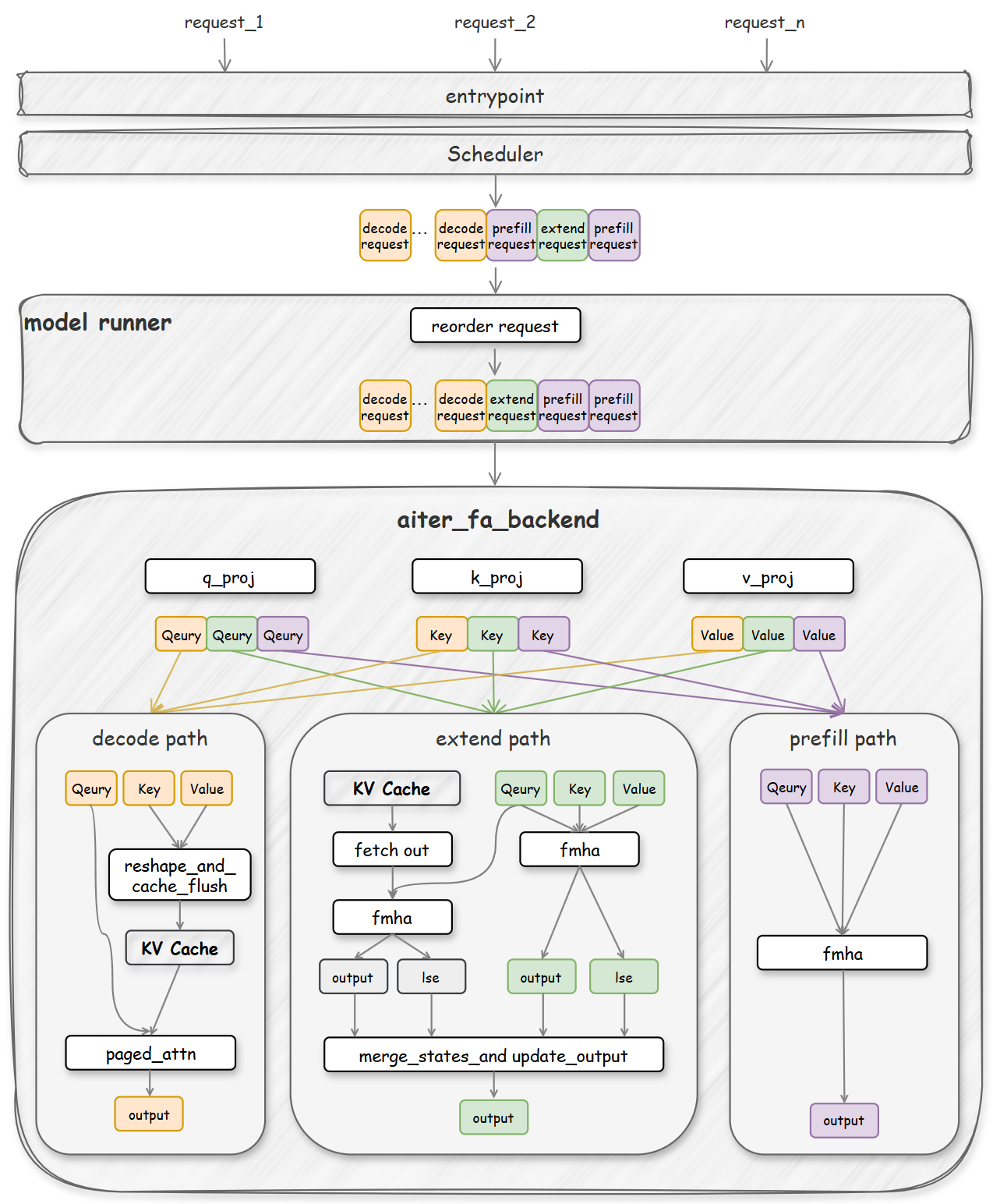
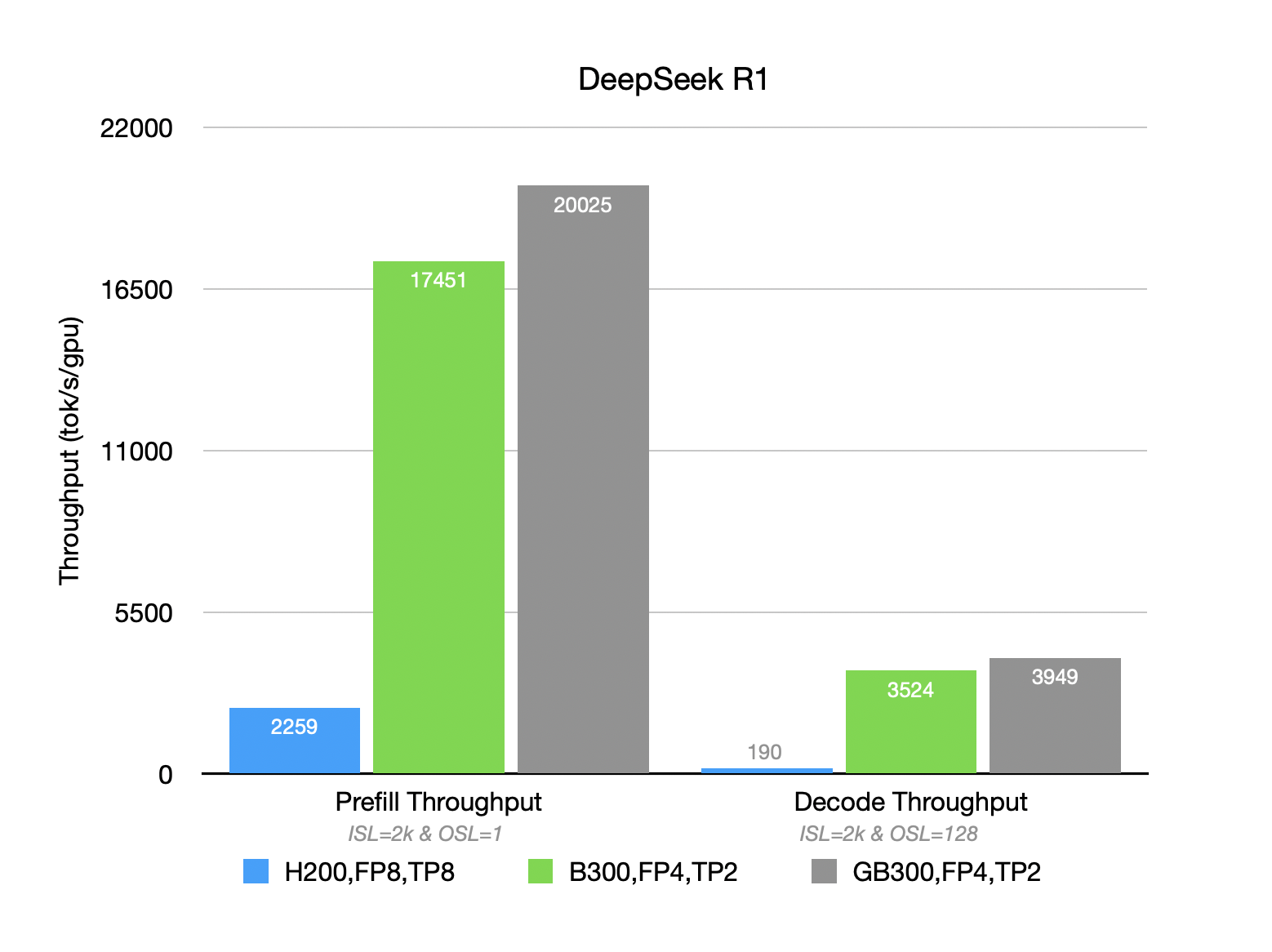
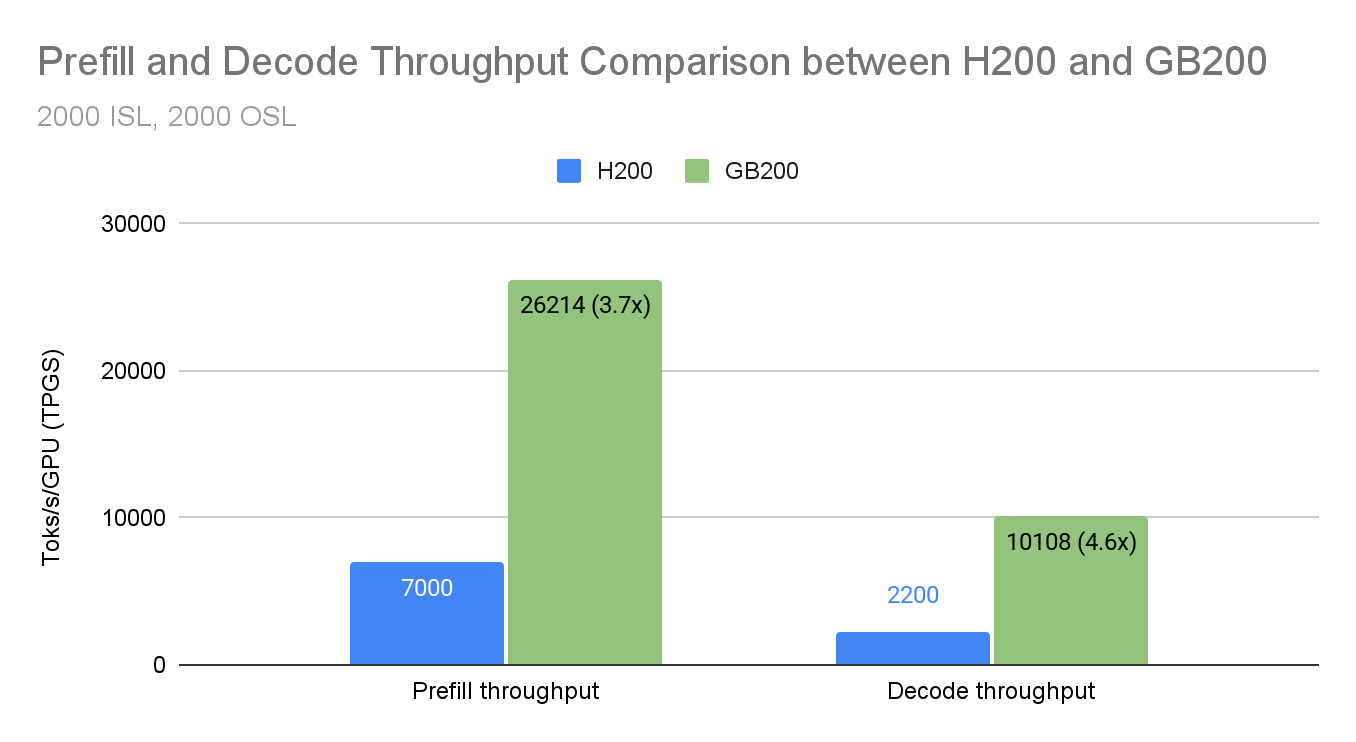
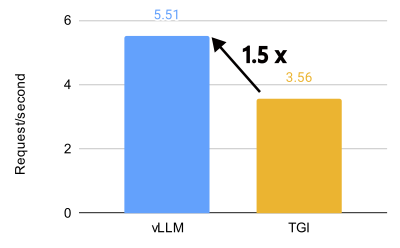
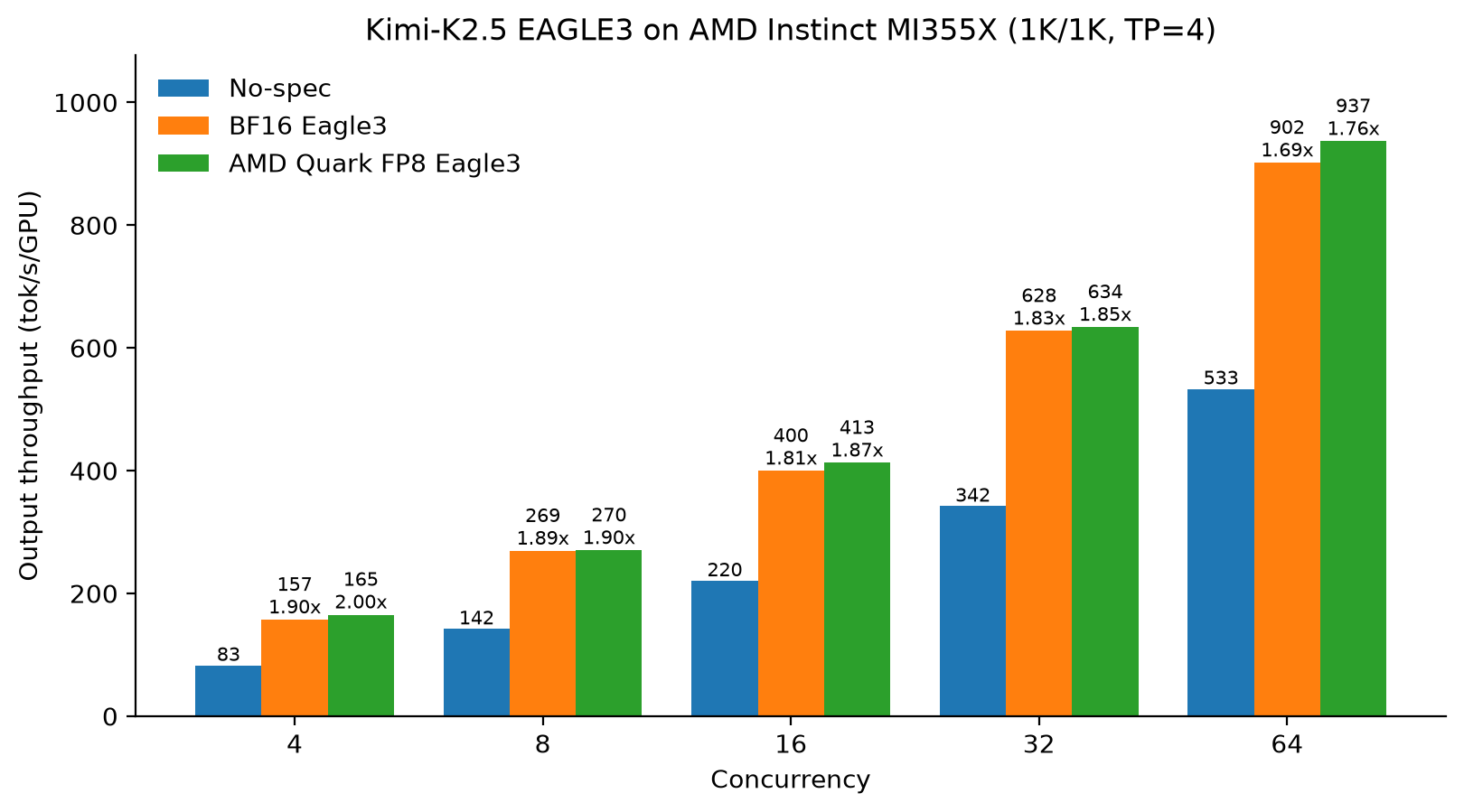
How AMD Quark trains, quantizes, and serves EAGLE-3 speculative-decoding drafts with vLLM on AMD Instinct GPUs, delivering up to 2.00x throughput gains for Kimi-K2.5 and 1.79x for MiniMax-M2.5.