vLLM Triton Attention Backend Deep Dive
·10 min read
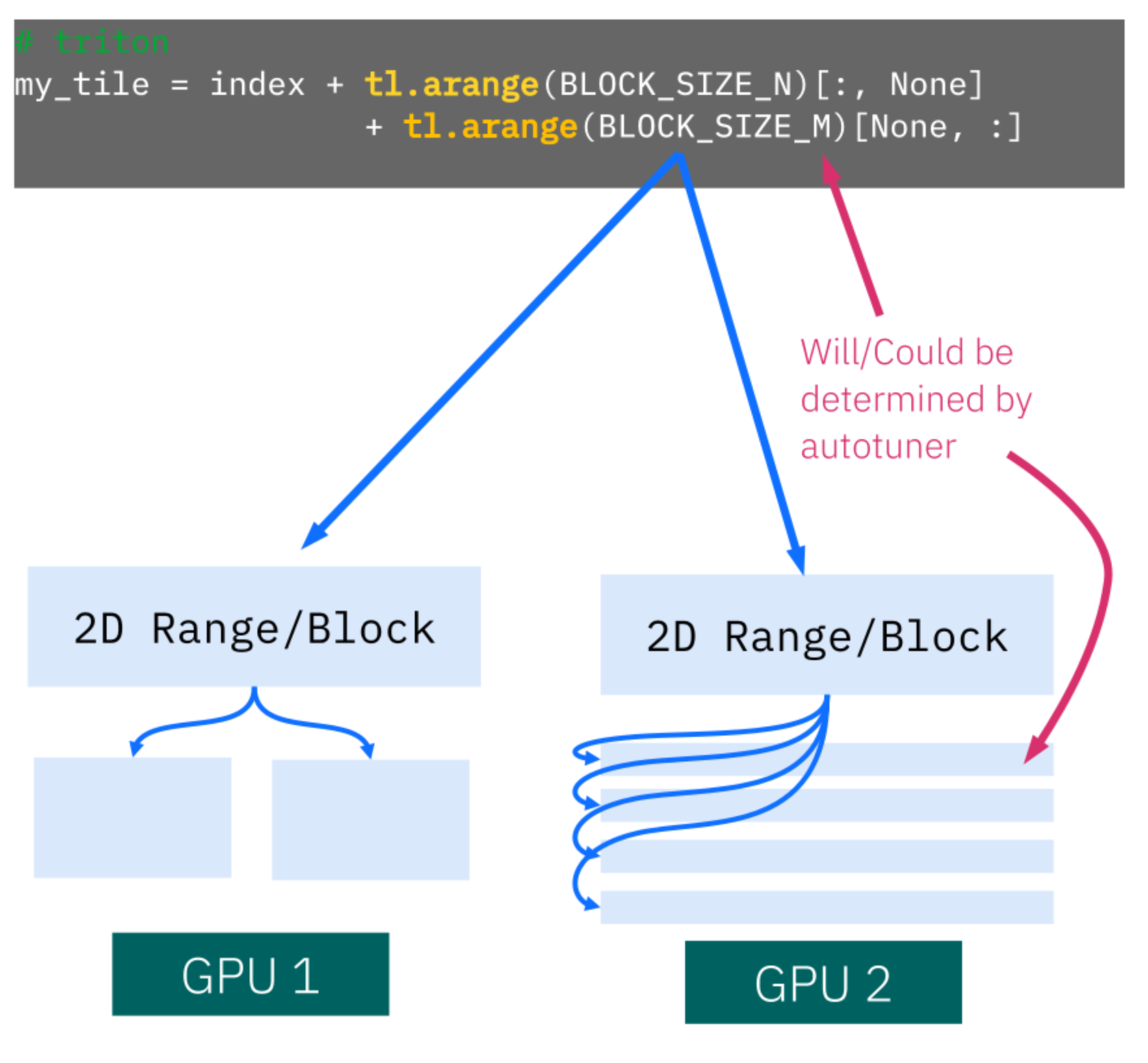
A technical walkthrough of the vLLM Triton attention backend, covering performance-portable paged attention kernels, backend selection, autotuning, CUDA graph behavior, benchmarks, and NVIDIA, AMD, and Intel support.