A First Comprehensive Study of TurboQuant: Accuracy and Performance
·12 min read
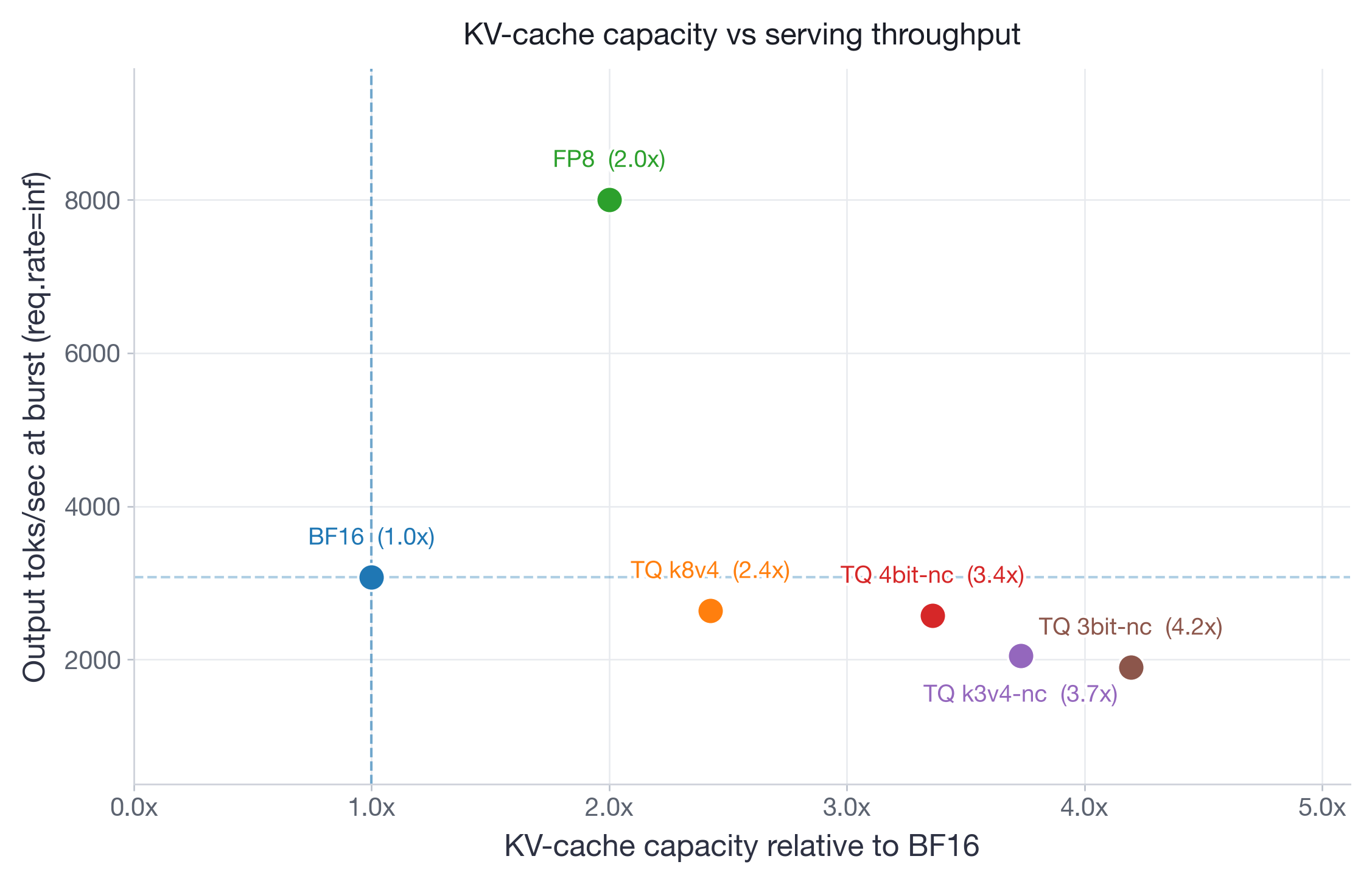
A vLLM study comparing TurboQuant KV-cache quantization with BF16 and FP8 across long-context and reasoning workloads, showing where 4-bit variants help, where accuracy drops, and why FP8 remains the default choice.