Fast & Efficient LLM Inference with vLLM: A New Course with DeepLearning.AI

We're excited to announce, with Red Hat and Andrew Ng's DeepLearning.AI, a hands-on course that walks through LLM fundamentals and the full optimize, deploy, and benchmark AI deployment lifecycle using vLLM and it's ecosystem of tools. It's called Fast & Efficient LLM Inference with vLLM, and it's available now!
"Deploying open-source LLMs efficiently, for many users, with low latency and reasonable cost, is challenging. This course shows you how." — Andrew Ng
How the Course Came Together
Earlier this year, we connected with the DeepLearning.AI team about building a course focused on LLM inference optimization. Since the vLLM ecosystem has grown to include not just the serving engine itself, but tools for model compression (LLM Compressor) and deployment benchmarking (GuideLLM), we saw an opportunity to show how each of these piece together when deploying models at scale.
Collaborating with Andrew Ng and his team in Mountain View, we shaped the materials around the workflow that many deployments follow: compress the model to fit your hardware, serve it efficiently with vLLM, then benchmark to understand where you stand on the speed-cost-accuracy tradeoff. There's also a good amount of foundational concepts around inference & memory before the code examples start that really help learners understand why optimizations like continuous batching, PagedAttention, and prefix caching help.
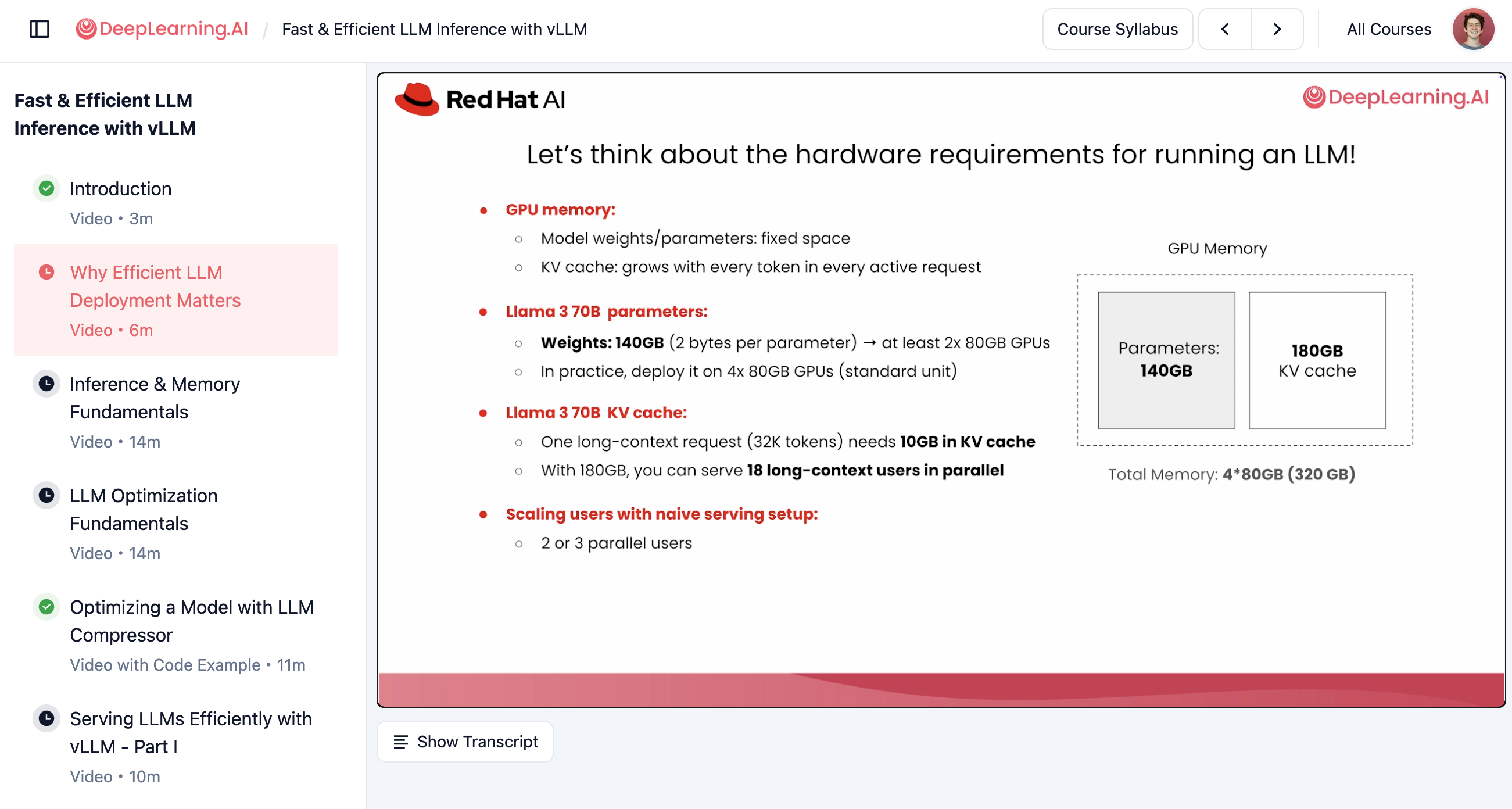
The course covers hardware requirements, memory hierarchy, and optimization techniques before diving into hands-on labs.
What We Put Into It
A lot of the effort went into visualization. We wanted learners to really understand what's happening behind inference, as well as KV Cache and the GPU Memory hierarchy.
We broke down the transformer architecture at inference time, for example how tokens flow through the model, what computations happen at each layer, and where the bottlenecks actually live. We also visualized the KV cache: what it looks like in GPU memory, how it grows with each token generated, and why serving multiple concurrent users creates immense memory pressure.
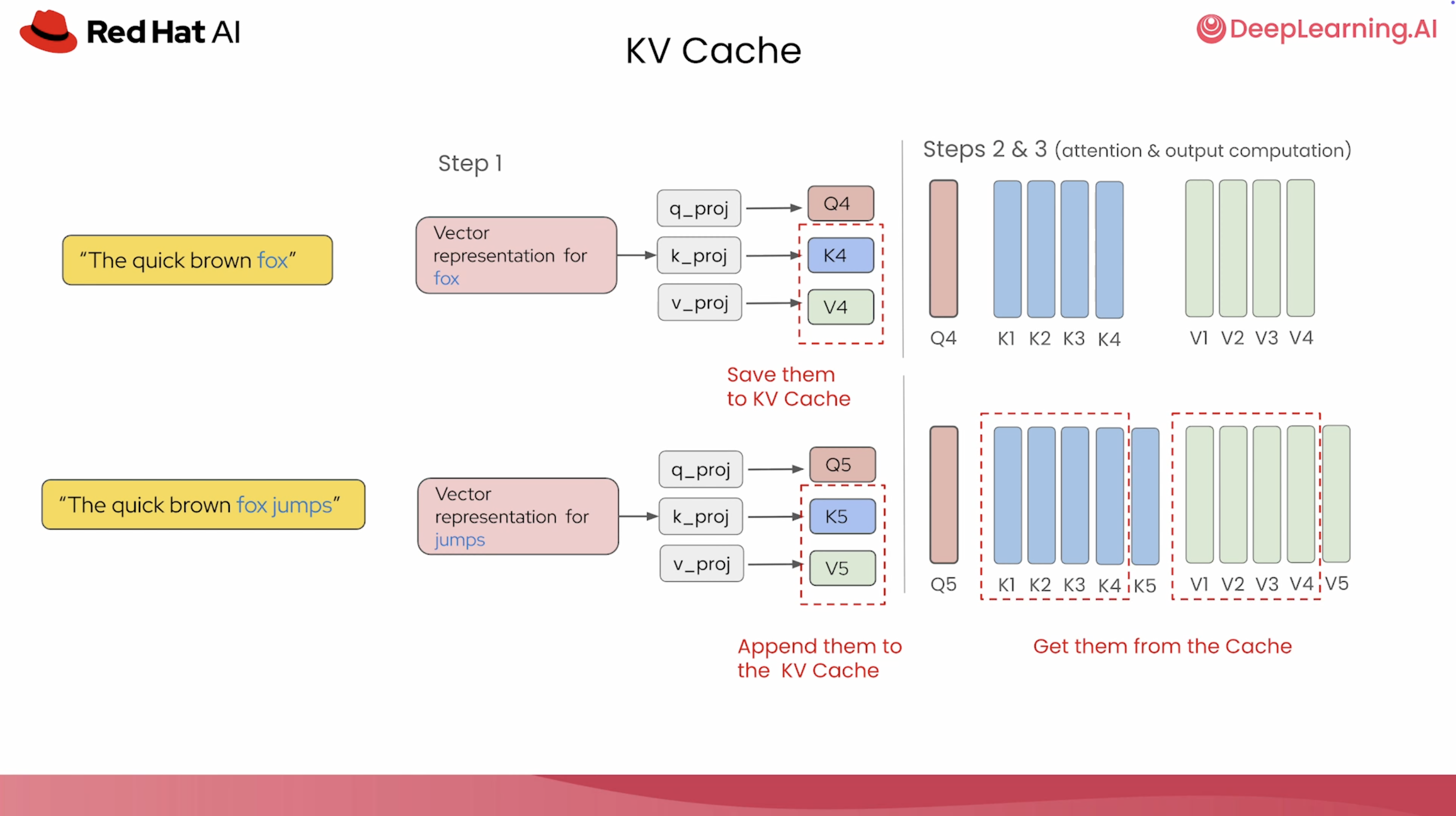
Visualizing how the KV cache grows during autoregressive generation in the course.
For quantization, we built visual explanations of what happens when you move from a model's default released weights at FP16 to INT8 or INT4, including the benefits and tradeoffs.
Breaking down weight-only vs. weight-and-activation quantization and the GPU memory hierarchy.
What's in the Course
The course is mainly split into three stages, where each has a hands-on lab in a JupyterLab environment where learners work with actual models and an running vLLM server:
Compress
You take a full-precision Qwen model and quantize it using LLM Compressor. You compare model size before and after, then measure perplexity to quantify the accuracy tradeoff. This lab gives you a good feel for quantization techniques and how you can reduce GPU memory requirements when deploying LLMs.
Quantizing a Qwen model with LLM Compressor in the course lab.
Serve
You learn how to deploy a model with vLLM and interact with it through the OpenAI-compatible API. You watch continuous batching and more through vLLM's metrics, seeing how memory utilization changes as concurrent requests come in, and how prefix caching avoids redundant computation when requests share a system prompt.
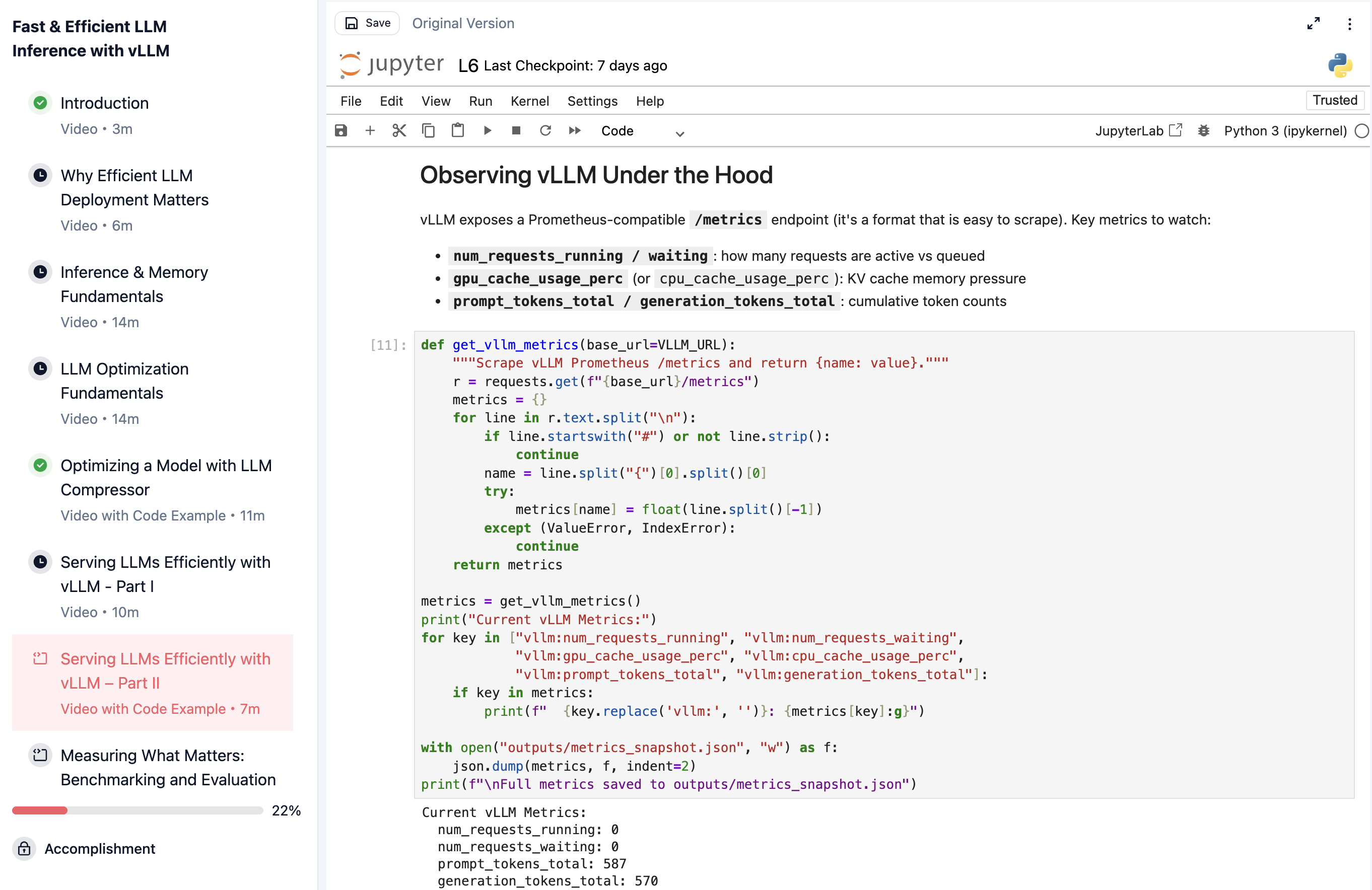
Watching vLLM's serving metrics live as concurrent requests hit the server.
Benchmark
You simulate realistic traffic patterns with GuideLLM, measuring latency and throughput under load. Then you evaluate model quality with lm-eval to confirm the compressed model still meets your accuracy requirements. By the end, you've run the full load/accuracy analysis on a real model and understand the tradeoffs well enough to make informed deployment decisions.
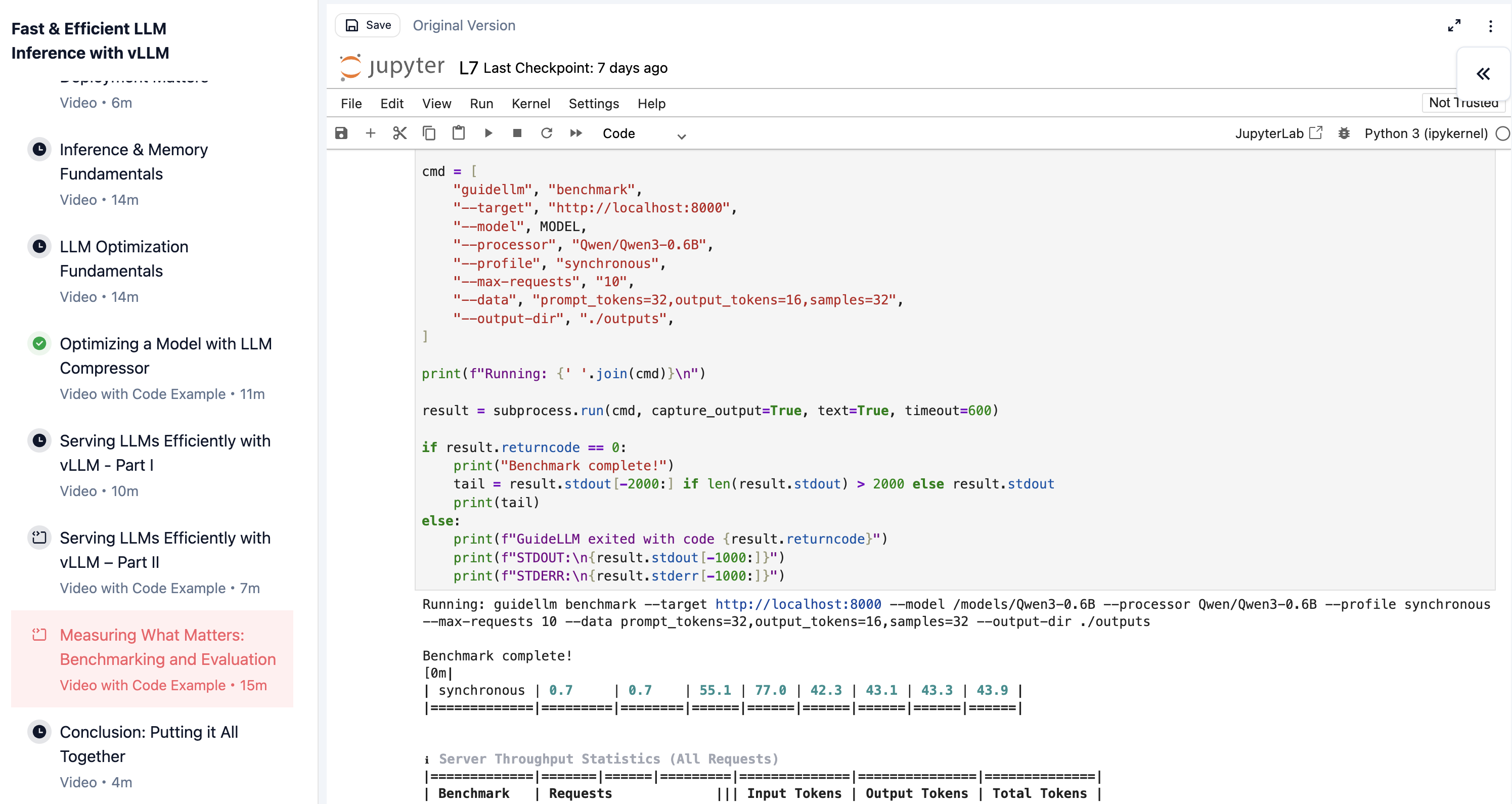
Running GuideLLM to benchmark a vLLM deployment under simulated traffic in the course lab.
Course Details
- Course: Fast & Efficient LLM Inference with vLLM
- Instructor: Cedric Clyburn, Senior Developer Advocate at Red Hat
- Duration: ~1.5 hours, 9 video lessons, 3 hands-on code labs
- Level: Intermediate (assumes familiarity with Python and basic LLM concepts)
The course is free on DeepLearning.AI, and is useful if you've been running models locally or at scale and want to understand what's happening under the surface. Or, if you've heard of vLLM and want to get hands-on! You'll get experience with deploying open-source models and we hope this is a useful resource.
Acknowledgments
This course was a team effort. From Red Hat: Saša Zelenović, Michael Goin, and Sawyer Bowerman contributed to the course design, technical content, and lab development. From DeepLearning.AI: Hawraa Salami helped shape the curriculum and production. And thanks to Andrew Ng for the collaboration and making space for open-source inference tooling in the DeepLearning.AI catalog. We hope you enjoy the course!