Next-Level Inference: Why Your Single-Node vLLM Setup Needs Prefill-Decode Disaggregation
TL;DR: Prefill and decode fight over the same GPUs, causing ITL spikes under load. We show how to disaggregate them on a single 8-GPU MI300X node using AMD's MORI-IO connector — achieving 2.5x higher goodput compared to standard collocated serving on the same 8 GPUs, with stable token generation. Benchmark uses Qwen3-235B-A22B-FP8 at 8 req/s with 2000-token prompts and 1000-token outputs — see Table 3 and Experimental Details for full configuration.
Introduction
In our previous exploration of MoE optimization [1], we walked through distributing a massive model across an 8-GPU AMD Instinct MI300X node using Tensor, Pipeline, Data, and Expert Parallelism. In this blog, we show how Prefill-Decode disaggregation — enabled by AMD's MORI-IO — addresses this bottleneck, delivering higher goodput and more predictable performance without requiring a multi-node cluster.
Your HBM is fully utilized, your compute is well balanced, and your vLLM deployment is running smoothly — until you increase concurrency. Then things start to break down: Inter-Token Latency (ITL) spikes unpredictably. The root cause is simple — prefill and decode are fundamentally different workloads competing for the same GPU resources.
Prefill is compute-bound: it processes the entire prompt in parallel using large GEMMs, with cost scaling directly with input length.
Decode is memory-bandwidth-bound: it generates tokens one at a time, repeatedly loading model weights from HBM with relatively low compute per byte.
When both phases share the same instance, they interfere with each other. Prefill requests can block dozens of ongoing decode streams, leading to visible stuttering, while decode workloads delay the scheduling of new prefills. The result is a system where neither phase runs efficiently nor predictably.
Key Highlights
-
2.5× Higher Goodput on the Same Hardware. Achieves significantly higher SLO-compliant throughput on a single 8-GPU MI300X node by separating prefill and decode.
-
Eliminates ITL Spikes Under Load. Dedicated decode GPUs ensure stable, predictable token generation by removing prefill interference.
-
Single-Node Disaggregation — No Cluster Needed. Implements Prefill-Decode (PD) disaggregation entirely within one node, unlocking unused performance.
-
MORI-IO for Fast KV Cache Transfer. RDMA-based KV movement enables efficient handoff between phases.
-
Flexible Modes with Trade-offs. Write mode delivers best performance (lower TTFT), while read mode offers simpler orchestration — both vastly outperform standard serving.
The Misconception: "Disaggregation is Only for Datacenter Clusters"
When inference engineers hear "Prefill-Decode (PD) Disaggregation," they often picture multi-node datacenter setups — dedicated prefill nodes, dedicated decode nodes, and RDMA fabric tying them together. The natural assumption is: "I only have a single 8-GPU node — this doesn't apply to me."
That assumption leaves significant performance on the table. PD disaggregation can be implemented entirely within a single 8-GPU system, and if you care about meeting strict latency SLOs, it's often the right approach.
The idea is straightforward: separate the two phases into dedicated instances. For example, four GPUs handle prefill while the other four handle decode. Each instance can then be independently sized, parallelized, and scheduled, eliminating the head-of-line blocking that limits monolithic deployments.
The challenge lies in the handoff. The KV cache generated during prefill must be transferred to the decode instance — and this can involve gigabytes of data. If not handled efficiently, the transfer itself can become a new bottleneck, negating the benefits of disaggregation.
AMD addresses this with MORI-IO, an RDMA-based KV cache connector contributed to vLLM [4], built on top of the open-source MORI (Modular RDMA Interface) [5] framework.
Scope: This blog focuses on single-node PD disaggregation, deploying on one box with 8 GPUs, to improve goodput on your existing hardware.
The Architecture: Serving with PD Disaggregation
Splitting your node requires shifting from a monolithic deployment to a lightweight microservice architecture with three components as shown in Table 1 below.
| Component | Role |
|---|---|
| Prefill instance | Processes the input prompt and produces the KV cache (GPUs 0–3) |
| Decode instance | Generates output tokens one by one using the transferred KV cache (GPUs 4–7) |
| Proxy server | Entry point for client requests; routes to prefill first, then decode |
At a high level, both modes transfer the KV cache (prefill output) from the prefill instance to the decode instance, but differ in who initiates the transfer and when:
- Read mode: The proxy waits for prefill to complete, then forwards the KV block locations to decode. Decode pulls the KV data via RDMA before it begins generating.
- Write mode: The proxy dispatches to prefill and decode at the same time. As prefill computes each layer, it pushes the KV data directly into decode's memory — so decode can start generating as soon as prefill finishes.
Request Flow in Detail
MORI-IO supports two transfer modes that differ in who initiates the RDMA transfer and how the proxy orchestrates the two phases. The mode is set by the VLLM_MORIIO_CONNECTOR_READ_MODE environment variable.
Read Mode — Decode Pulls KV Cache
Enable with: export VLLM_MORIIO_CONNECTOR_READ_MODE=1
In read mode, the proxy dispatches to prefill and decode serially: it waits for prefill to complete, extracts the remote block IDs, then forwards them to decode. The decode instance uses those IDs to pull the KV cache from prefill via RDMA. The request flow is illustrated in Figure 1.

Figure 1: Read mode request flow. The proxy dispatches serially — step 3 (prefill response) must complete before step 4 (dispatch to decode).
The time-ordered sequence for a single request:
- Client → Proxy: Client sends an inference request.
- Proxy → Prefill: Proxy routes the prompt to the prefill instance (
max_tokens=1). - Prefill → Proxy (response): Prefill returns
remote_block_idsandremote_engine_ididentifying where the KV cache lives. - Proxy → Decode: Proxy forwards the request to decode, including the remote block IDs.
- Decode pulls KV cache (
WAITING_FOR_REMOTE_KVS): Decode issues an RDMA read against prefill's memory. The scheduler skips the request each step until the transfer completes. - Decode → Prefill (cleanup): Once all KV blocks are transferred, decode notifies prefill to free its blocks.
- Decode → Proxy → Client: Generated tokens stream back via SSE.
Write Mode — Prefill Pushes KV Cache (Default)
Enable with: VLLM_MORIIO_CONNECTOR_READ_MODE unset (or =0)
In write mode, the proxy dispatches to prefill and decode concurrently — without waiting for prefill to finish first. The prefill instance pushes the KV cache layer-by-layer directly into the decode instance's pre-allocated memory as it computes each layer. The request flow is illustrated in Figure 2.

Figure 2: Write mode request flow. The proxy fires both prefill and decode concurrently (step 2); prefill pushes KV layer-by-layer via RDMA WRITE (step 3) while decode waits.
The time-ordered sequence for a single request:
- Client → Proxy: Client sends an inference request.
- Proxy → Prefill AND Proxy → Decode (concurrent): The proxy fires both requests in parallel. The prefill request carries decode's connection details; the decode request carries prefill's connection details. The proxy does not block on the prefill response.
- Prefill pushes KV cache: As each layer is computed,
save_kv_layerissues an RDMA write directly into the decode instance's pre-allocated KV block memory. For chunked prefill, blocks accumulate until the last chunk before the write is initiated. - Decode waits for write completion (
WAITING_FOR_REMOTE_KVS): The decode scheduler pollspop_finished_write_req_idseach step until all blocks are received. - Decode generates: Once all KV blocks arrive, decode immediately moves the request to its ready queue and begins autoregressive generation.
- Decode → Proxy → Client: Generated tokens stream back via SSE.
The key code difference in the proxy is a single conditional:
# examples/online_serving/disaggregated_serving/moriio_toy_proxy_server.py
if TRANSFER_TYPE == "READ":
# Serial: wait for prefill to finish, extract block IDs for decode to pull.
prefill_response = await send_prefill_task
req_data["kv_transfer_params"]["remote_engine_id"] = prefill_response[
"kv_transfer_params"
]["remote_engine_id"]
req_data["kv_transfer_params"]["remote_block_ids"] = prefill_response[
"kv_transfer_params"
]["remote_block_ids"]
# In WRITE mode, execution falls through here immediately —
# no await on send_prefill_task. Both phases are already in flight.
decode_request_task = asyncio.create_task(
start_decode_request(decode_instance_endpoint["request_address"], req_data, request_id)
)In read mode, remote_block_ids must be relayed through the proxy because decode needs to know which specific prefill-side blocks to pull. In write mode, prefill owns the write and pushes directly to decode's addresses — no block IDs need to be relayed.
Read Mode vs. Write Mode: At a Glance
Under the hood, MORI-IO (exposed in vLLM as the MoRIIOConnector) manages the KV-cache handoff. Regardless of transfer mode, before the first RDMA transfer between an instance pair, MORI-IO performs a one-time metadata exchange via ZMQ — sharing KV cache base addresses, block sizes, and per-layer tensor strides. This handshake runs asynchronously in a background thread so it doesn't block the engine loop, and the resulting RDMA session is cached for all subsequent requests.
Both modes share the same handshake and RDMA transport — the differences are entirely at the proxy dispatch layer and the direction of the transfer. Table 2 captures the key distinctions at a glance:
| Property | Read Mode | Write Mode |
|---|---|---|
VLLM_MORIIO_CONNECTOR_READ_MODE | =1 | Unset (or =0) |
| RDMA direction | Decode pulls from prefill | Prefill pushes to decode |
| Proxy dispatch | Serial (await prefill → dispatch decode) | Concurrent (prefill and decode in parallel) |
remote_block_ids relay via proxy | Required | Not required |
| KV cleanup signal | Decode notifies prefill to free blocks after pull | Prefill tracks write completion per request |
Results: 2.5x Higher Goodput
Before diving into configuration details, let's look at what disaggregation actually delivers.
Why Goodput, Not Throughput
Raw throughput alone is misleading — a system can sustain high request rates while silently violating latency targets for most users. We use goodput as the primary metric, following the DistServe methodology [3]:
Goodput = maximum request rate (req/s) such that requests satisfy both TTFT < T_ttft and ITL < T_itl.
This captures both cost (requests per second) and service quality (latency SLO attainment) in a single number. Our SLO targets: TTFT < 1 second and ITL < 50 ms per token. A request counts toward goodput only if both conditions are met.
Headline Result
Figure 3 shows goodput at request rate = 8:
| Metric | Standard (1× TP8) | Standard (2× TP4) | MORI-IO Read (1P+1D) | MORI-IO Write (1P+1D) |
|---|---|---|---|---|
| Requests meeting both SLOs | 26/100 | 30/100 | 70/100 | 73/100 |
| Primary failure mode | ITL spikes (P99 ITL >> 50 ms) | ITL spikes (bimodal: ~30ms and ~150ms) | TTFT exceeds 1s for some requests | TTFT exceeds 1s for some requests |
| Relative goodput | 0.9x | 1x | 2.4x | 2.5x |
Standard serving fails because ITL concentrates in two clusters — the high-latency cluster at ~150ms far exceeds the 50ms threshold. Both disaggregated modes eliminate ITL violations entirely; their remaining failures are TTFT exceedances as request rate climbs. Write mode edges out read mode (73 vs 70) because concurrent proxy dispatch lowers TTFT, keeping more requests below the 1s threshold.
SLO Attainment Across Request Rates
Figure 4 shows SLO attainment across request rates from 0.5 to 10:
- Standard serving (1× TP8): Shows ITL violations from low request rates, dominating across all tested request rates. Achieves 26/100 at rate = 8.
- Standard serving (2× TP4): Degrades sharply — from 100% at rate 0.5 to ~60% at rate 1, collapsing to ~25% by rate 2 where it plateaus. ITL violations saturate early.
- MORI-IO Read (1P+1D): Sustains 100% attainment up to rate ~5, then declines gradually to ~44% at rate 10 as TTFT begins exceeding the threshold.
- MORI-IO Write (1P+1D): Sustains 100% attainment up to rate ~5.5, then declines gradually to ~46% at rate 10 as TTFT begins exceeding the threshold.
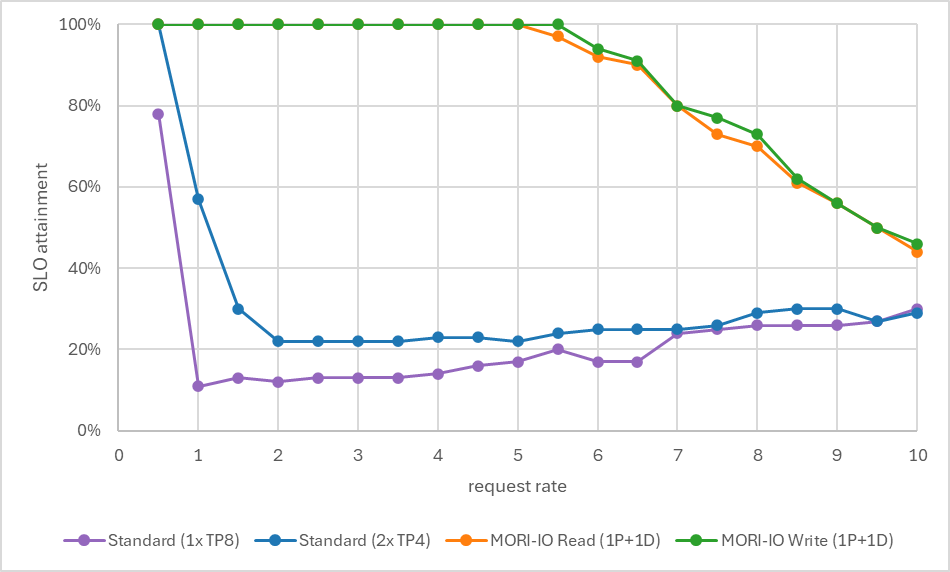
Figure 4: SLO attainment (% of requests meeting both TTFT and ITL targets) across request rates. Both disaggregated modes show higher SLO attainment than all standard serving configurations across all tested request rates.
Understanding the Trade-offs
Why ITL Improves
In a standard deployment, prefill and decode share the same vLLM engine and compete for scheduling within each batch. A single prefill — processing all input tokens in one forward pass — takes significantly longer than a decode step. Every decode request in the same batch waits for that prefill to finish before generating its next token, directly inflating ITL.
With disaggregation, your decode engine runs exclusively decode batches. No compute-intensive prefill jobs interrupt the step cadence, so ITL becomes stable and predictable regardless of how many new requests are entering the system. This benefit is identical in both read mode and write mode — the decode engine is isolated from prefill in either case.
Why TTFT Gets Worse
The flip side: disaggregation adds overhead to the path to first token. In standard serving:
TTFT = queue + prefill_forward_pass + sample_T1 + detokenize + SSE_encode + network
In read mode, two extra steps are inserted (Figure 5):
TTFT = queue(prefill) + prefill_forward_pass
+ [proxy serialization: await prefill, dispatch to decode] <- Overhead 1
+ RDMA transfer (WAITING_FOR_REMOTE_KVS) <- Overhead 2
+ queue(decode) + sample_T1 + detokenize + SSE_encode + network
Figure 5: Read mode timing. Overhead 1 (proxy serialization) and Overhead 2 (RDMA READ) are additive contributors to TTFT.
In write mode (Figure 6):
TTFT ≈ max(
queue(prefill) + prefill_forward_pass + RDMA_write_time,
queue(decode)
) + sample_T1 + detokenize + SSE_encode + network
Figure 6: Write mode timing. RDMA WRITE overlaps with prefill compute, so Overhead 2 does not add to wall-clock TTFT.
Write mode eliminates Overhead 1. Because the proxy dispatches to both instances concurrently, the decode queue wait and prefill compute overlap. The remaining cost — the RDMA transfer itself — is structurally equivalent to the RDMA read in read mode.
Overhead 1: Proxy Serialization (Read Mode Only)
In read mode, the proxy awaits the full prefill response before dispatching to decode. This adds the entire prefill compute time plus a proxy round-trip to client-visible TTFT. In write mode, this block is skipped — the decode request is already in flight before prefill finishes.
# examples/online_serving/disaggregated_serving/moriio_toy_proxy_server.py
if TRANSFER_TYPE == "READ":
# In read mode, prefill and decode are executed serially.
prefill_response = await send_prefill_task
req_data["kv_transfer_params"]["remote_engine_id"] = prefill_response[
"kv_transfer_params"
]["remote_engine_id"]
req_data["kv_transfer_params"]["remote_block_ids"] = prefill_response[
"kv_transfer_params"
]["remote_block_ids"]Overhead 2: RDMA Transfer Wait
Once the decode instance receives the request, it enters the WAITING_FOR_REMOTE_KVS state. The scheduler skips the request every step until the RDMA transfer completes, then immediately moves it to the ready queue for scheduling.
# vllm/v1/request.py
WAITING_FOR_REMOTE_KVS = enum.auto()
# vllm/v1/core/sched/scheduler.py
# KVTransfer: skip request if still waiting for remote kvs.
if request.status == RequestStatus.WAITING_FOR_REMOTE_KVS:
is_ready = self._update_waiting_for_remote_kv(request)
if is_ready:
request.status = RequestStatus.WAITING
else:
logger.debug("%s is still in WAITING_FOR_REMOTE_KVS state.",
request.request_id)
self.waiting.pop_request()
skipped_waiting_requests.prepend_request(request)
continueIn read mode, this wait starts after prefill has already finished. In write mode, this wait starts immediately when the decode request arrives — overlapping with ongoing prefill computation on the other instance.
Bottom line: Disaggregation gives you stable, predictable ITL at the cost of a longer wait for the first token. How much longer depends on the mode. In read mode, TTFT increases by at least one full prefill forward pass (proxy serialization) plus the RDMA transfer time. In write mode, proxy serialization is eliminated — TTFT increases only by the RDMA transfer time, which overlaps with the prefill compute, so the net penalty is smaller. Either way, ITL benefits are identical.
When Should You Use This?
Table 4 summarizes when to prefer each deployment approach.
| Your situation | Recommendation |
|---|---|
| ITL p99 exceeds your SLO under production load | Disaggregate — this is the primary use case |
| TTFT is your binding constraint (e.g., chatbot UX) | Standard serving may be preferable |
| High concurrency with long prompts | Disaggregate — prefill interference is worst here |
| Low request rates with short prompts | Standard serving is sufficient |
How to Set It Up
Now that you've seen the results, here's how to deploy it. You'll configure three components: a prefill instance, a decode instance, and a proxy server. For the full vLLM disaggregated prefill documentation, see [2].
Prefill Instance
The prefill instance acts as the KV producer (kv_role: kv_producer). It processes the input prompt, computes the KV cache, and makes it available for the decode instance to read via RDMA.
vllm serve <model> \
...
--gpu_memory_utilization 0.9 \
--kv-transfer-config '{
"kv_connector": "MoRIIOConnector",
"kv_role": "kv_producer",
"kv_connector_extra_config": {
"proxy_ip": "127.0.0.1",
"proxy_ping_port": "36367",
"http_port": "20005",
"handshake_port": "6301",
"notify_port": "6105"
}
}'On startup, the instance registers itself with the proxy over ZMQ, sending its role, HTTP address, handshake and notify ports, and parallelism configuration. It continues sending periodic registration messages so the proxy can detect unavailability.
Decode Instance
The decode instance acts as the KV consumer (kv_role: kv_consumer). It receives the request from the proxy after prefill completes, then pulls the KV cache via RDMA.
vllm serve <model> \
...
--gpu_memory_utilization 0.9 \
--kv-transfer-config '{
"kv_connector": "MoRIIOConnector",
"kv_role": "kv_consumer",
"kv_connector_extra_config": {
"proxy_ip": "127.0.0.1",
"proxy_ping_port": "36367",
"http_port": "40005",
"handshake_port": "7301",
"notify_port": "7501"
}
}'Proxy Server
The proxy is a lightweight HTTP server that orchestrates the two-phase flow. It listens for instance registrations on the proxy_ping_port via ZMQ and routes each request using round-robin scheduling.
python examples/online_serving/disaggregated_serving/moriio_toy_proxy_server.pyIn READ mode, the proxy waits for the prefill instance to complete, extracts the remote_block_ids from the response, and passes them to the decode instance so it knows exactly which KV blocks to pull.
Port Reference
Each instance uses several ports for different communication channels, summarized in Table 5. Per-rank offsets are applied in MoRIIOConfig (see moriio_common.py):
| Port | Purpose |
|---|---|
proxy_ping_port | ZMQ endpoint where each instance registers with the proxy |
http_port | vLLM HTTP server port; the proxy forwards inference requests here |
handshake_port | One-time metadata exchange: consumer obtains producer's KV cache layout |
notify_port | Per-request sync: prefill signals decode when KV blocks are ready |
Experimental Details
Setup
The environment can be reproduced by building from the provided Dockerfiles — Dockerfile.rocm_base (using MORI commit 2d02c6a9 from ROCm/mori) and Dockerfile.rocm (using vLLM main branch from vllm-project/vllm).
Hardware:
- GPU: 8× AMD Instinct MI300X GPUs (gfx942)
- CPU: 2× AMD EPYC 9654 96-Core Processor
Software stack:
- ROCm Driver: 6.10.5 (AMDGPU)
- Container: rocm/vllm-dev (ROCm 7.0.51831-a3e329ad8)
- vLLM: 0.16.0rc1.dev1+gc46b0cd0a (git sha: c46b0cd0a)
- PyTorch: 2.9.1+git8907517 (ROCm 7.0.51831-a3e329ad8)
- MORI library: commit
c365eaed
Benchmark configuration:
- Model: Qwen/Qwen3-235B-A22B-FP8
- Input sequence length: 2000 tokens
- Output sequence length: 1000 tokens
- Dataset: random
- Workload: 100 total requests
- Request rate: 0.5 to 10 (step 0.5)
Baseline Configurations
The four configurations compared in this blog are described in Table 6.
| Configuration | Description |
|---|---|
| Standard (1× TP8) | Single vLLM instance using all 8× MI300X GPUs (TP=8) with expert parallelism. Handles mixed prefill and decode workloads on one engine. |
| Standard (2× TP4) | Two identical vLLM instances, each using 4× MI300X GPUs (TP=4) with expert parallelism. A round-robin proxy distributes requests evenly. Both instances handle mixed prefill and decode workloads. |
| MORI-IO Read (1P+1D) | One prefill instance (GPU 0–3) and one decode instance (GPU 4–7), each TP=4 with expert parallelism. VLLM_MORIIO_CONNECTOR_READ_MODE=1 on both instances. Proxy dispatches serially: waits for prefill to return remote_block_ids, then forwards to decode. Decode pulls KV cache via RDMA. Prefix caching disabled. |
| MORI-IO Write (1P+1D) | One prefill instance (GPU 0–3) and one decode instance (GPU 4–7), each TP=4 with expert parallelism. KV cache transferred via MORI-IO in write mode. A stateful proxy orchestrates two-phase routing. Prefix caching disabled as required by the MORI-IO connector. |
Why this baseline? Both Standard (2× TP4) and the disaggregated configurations use the same total GPU count (8× MI300X) split into two 4-GPU groups, ensuring a fair apples-to-apples comparison. The only difference is whether each group runs a mixed prefill+decode workload (standard) or a dedicated prefill or decode workload (disaggregated). Standard (1× TP8) is included as an additional reference point using all 8 GPUs in a single engine.
Generalizability note: These results use a Mixture-of-Experts (MoE) model (Qwen3-235B-A22B-FP8). The prefill/decode interference pattern is fundamental to transformer inference and applies to dense models as well. MoE models tend to amplify the effect since expert routing adds variability to per-step compute, making ITL jitter more pronounced.
Conclusions and Way Forward
This post demonstrated that PD disaggregation isn't just a datacenter-scale technique — it delivers measurable gains on a single 8-GPU node. By dedicating GPUs to each phase and using MORI-IO for efficient RDMA-based KV cache transfer, we achieved 2.5× higher goodput and eliminated ITL violations that plague collocated deployments.
What's Next
- Multi-node deployment: In production, prefill and decode instances can span multiple nodes — MORI-IO already uses RDMA over the network fabric, so the same connector works across hosts without code changes.
- Per-phase tuning: With dedicated instances, the prefill instance can be configured for high compute throughput (larger token budgets, chunked prefill) while the decode instance is tuned for low latency (smaller batch sizes, stricter scheduling). This independent knob-turning is impossible in collocated deployments.
Appendix: Reproducible Configurations
To reproduce these results, pre-built nightly images are available at rocm/vllm-dev, or build from source using Dockerfile.rocm_base and Dockerfile.rocm from the vLLM repository (MORI commit 2d02c6a9, vLLM commit c46b0cd0a).
Complete vLLM command-line configurations for all benchmarks are provided below. Each command includes environment variables, parallelism flags, and deployment parameters for Qwen3-235B-A22B-FP8 on AMD Instinct MI300X GPUs.
Standard Serving
# Instance 1 (GPU 0-3)
CUDA_VISIBLE_DEVICES=0,1,2,3 VLLM_ROCM_USE_AITER=1 vllm serve Qwen/Qwen3-235B-A22B-FP8 \
-tp 4 \
--enable-expert-parallel \
--max-model-len 16384 \
--max-num-batched-tokens 8192 \
--distributed-executor-backend mp \
--no-enable-prefix-caching \
--port 8100
# Instance 2 (GPU 4-7)
CUDA_VISIBLE_DEVICES=4,5,6,7 VLLM_ROCM_USE_AITER=1 vllm serve Qwen/Qwen3-235B-A22B-FP8 \
-tp 4 \
--enable-expert-parallel \
--max-model-len 16384 \
--max-num-batched-tokens 8192 \
--distributed-executor-backend mp \
--no-enable-prefix-caching \
--port 8200
# Proxy
cd <path_to>/vllm
python benchmarks/disagg_benchmarks/round_robin_proxy.pyDisaggregated Serving
# Prefill instance (GPU 0-3)
export VLLM_MORIIO_CONNECTOR_READ_MODE=1 # unset for write mode
export VLLM_ROCM_USE_AITER=1
export CUDA_VISIBLE_DEVICES=0,1,2,3
export HIP_VISIBLE_DEVICES=0,1,2,3
export MORI_DISABLE_AUTO_XGMI=1
export MORI_IO_ENABLE_NOTIFICATION=0
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
-tp 4 \
--enable-expert-parallel \
--port 20005 \
--max-num-batched-tokens 4096 \
--distributed-executor-backend mp \
--gpu_memory_utilization 0.9 \
--max-model-len 16384 \
--max_num_seqs 64 \
--no-enable-prefix-caching \
--kv-transfer-config '{
"kv_connector": "MoRIIOConnector",
"kv_role": "kv_producer",
"kv_connector_extra_config": {
"proxy_ip": "127.0.0.1",
"proxy_ping_port": "36367",
"http_port": "20005",
"handshake_port": "6301",
"notify_port": "6105"
}
}'
# Decode instance (GPU 4-7)
export VLLM_MORIIO_CONNECTOR_READ_MODE=1 # unset for write mode
export VLLM_ROCM_USE_AITER=1
export CUDA_VISIBLE_DEVICES=4,5,6,7
export HIP_VISIBLE_DEVICES=4,5,6,7
export MORI_DISABLE_AUTO_XGMI=1
export MORI_IO_ENABLE_NOTIFICATION=0
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
-tp 4 \
--enable-expert-parallel \
--port 40005 \
--no-enable-prefix-caching \
--max-num-batched-tokens 4096 \
--distributed-executor-backend mp \
--gpu_memory_utilization 0.9 \
--max-model-len 16384 \
--max_num_seqs 64 \
--kv-transfer-config '{
"kv_connector": "MoRIIOConnector",
"kv_role": "kv_consumer",
"kv_connector_extra_config": {
"proxy_ip": "127.0.0.1",
"http_port": "40005",
"proxy_ping_port": "36367",
"handshake_port": "7301",
"notify_port": "7501"
}
}'
# Proxy
cd <path_to>/vllm
python examples/online_serving/disaggregated_serving/moriio_toy_proxy_server.pyAcknowledgements
We would like to thank the many talented people who have contributed to this collaboration:
AMD: Hongxia Yang, Gilbert Lei, Mingzhi Liu, Niko Ma, Tian Di, Randall Smith, Feiyue Zhai, Peng Sun, and the MORI team.
Embedded LLM: Pin Siang Tan, Jun Kang Chow, Ye Hur Cheong, Vensen Mu, Jeff Aw, Tun Jian Tan and the Embedded LLM team.
References
- AMD and Embedded LLM, "The vLLM MoE Playbook: A Practical Guide to TP, DP, PP and Expert Parallelism" https://rocm.blogs.amd.com/software-tools-optimization/vllm-moe-guide/README.html
- vLLM Disaggregated Prefill Documentation https://docs.vllm.ai/en/latest/features/disagg_prefill/
- DistServe: Maximizing Goodput in LLM Serving https://haoailab.com/blogs/distserve/
- MORI-IO Connector PR #29304 https://github.com/vllm-project/vllm/pull/29304
- MORI (Modular RDMA Interface) https://github.com/ROCm/mori
Disclaimer
Testing at Mar. 12, 2026, measuring inference goodput on AMD Instinct MI300X platform.
Hardware Configuration
- MI300X: AMD EPYC 9654 96-Core Processor server with 8× AMD Instinct MI300X (192GB, 750W) GPUs, NPS1 (1 NUMA per socket), 2.2TiB (24 DIMMs, 4800 MT/s memory, 96 GiB/DIMM)
Software Configuration
Ubuntu 22.04 LTS with Linux kernel 5.15.0-153-generic, ROCm Driver 6.10.5 (AMDGPU), ROCm 7.0.51831-a3e329ad8, PyTorch 2.9.1+git8907517, vLLM 0.16.0rc1.dev1+gc46b0cd0a, MORI library commit c365eaed
Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations.