Run Highly Efficient and Accurate Multi-Agent AI with NVIDIA Nemotron 3 Super Using vLLM
We are excited to support the newly released NVIDIA Nemotron 3 Super model on vLLM.
Nemotron 3 Super, part of the Nemotron 3 family of open models, is optimized for complex multi-agent applications. Agentic AI systems today rely on multiple models to plan, reason, and execute complex, multi-step tasks. These models must possess both the necessary depth for solving intricate technical challenges and the efficiency required for continuous operation at scale.
Nemotron 3 Super is an open, hybrid Mixture-of-Experts (MoE) model featuring 120 billion parameters, yet it activates only 12 billion at inference. This design achieves high compute efficiency and leading accuracy, particularly for complex multi-agent applications. It addresses two major challenges in large-scale agent systems:
- The "Context Explosion" Problem: Multi-agent systems often generate excessive tokens due to re-sending history, tool outputs, and reasoning steps. Nemotron 3 Super resolves this with a massive 1 million token context window, providing agents with long-term memory and significantly reducing goal drift.
- The "Thinking Tax": Running reasoning-intensive agents can be costly and slow with conventional massive models. The hybrid MoE architecture provides up to 4x higher throughput, tackling this tax by allowing complex agents to run without high latency and cost on every sub-task.
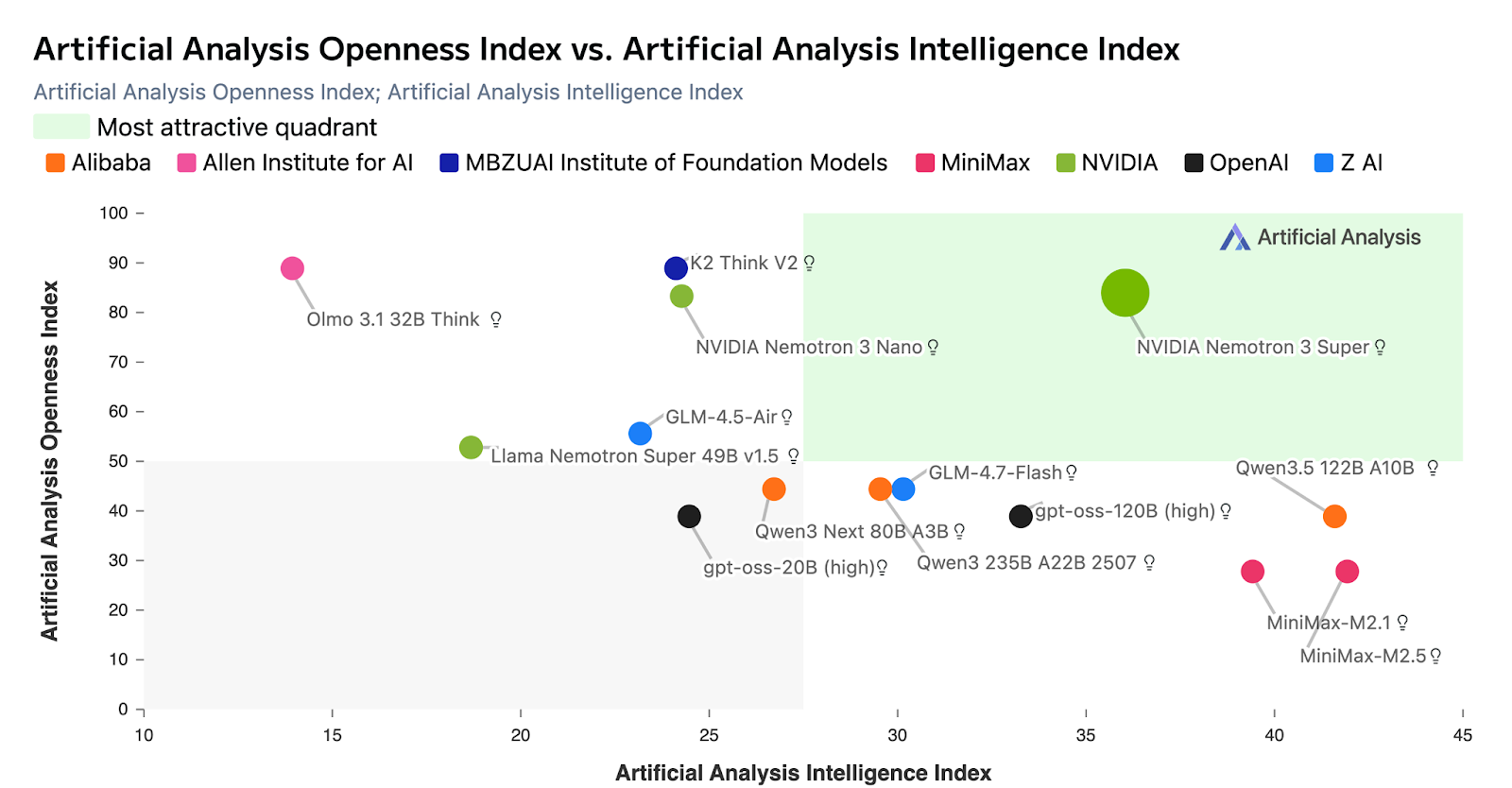
Figure 1: Artificial Analysis chart showing Nemotron 3 Super leading on intelligence vs. openness comparing popular open models
As you can see in the chart above, Nemotron 3 Super leads on the Artificial Analysis Openness index. When compared to other open models, Nemotron is fully open with open-weights, datasets, and recipes so developers can easily customize, optimize, and deploy on their infrastructure for maximum privacy and security.
In this blog post, we'll share how to get started with Nemotron 3 Super using vLLM for inference to unlock high-efficiency, high-accuracy multi-agent AI at scale.
About Nemotron 3 Super
- Architecture: Mixture of Experts (MoE) with Hybrid Transformer-Mamba Architecture
- Highest throughput efficiency in its size category and up to 5x higher throughput compared to previous Nemotron Super model
- Multi-Token Prediction (MTP): By predicting several future tokens simultaneously in a single forward pass, MTP drastically accelerates the generation of long-form text
- Supports Thinking Budget for optimal accuracy with minimum reasoning token generation
Key Specs:
- Accuracy: Leading accuracy on Artificial Analysis Intelligence Index in its size category; up to 2x higher accuracy compared to previous Nemotron Super model
- Latent MoE enables calling 4 experts for the inference cost of only one
- Model size: 120B total parameters, 12B active parameters
- Context length: up to 1M
- Model I/O: Text in, text out
- Supported GPUs: B200, H100, DGX Spark, RTX 6000
Get started:
- Download model weights from Hugging Face - BF16, FP8 and NVFP4
- Run with vLLM for inference
- Read technical report for more details
Run optimized inference with vLLM
Nemotron 3 Super achieves accelerated inference and serves more requests on the same GPU with BF16, FP8, and NVFP4 precision support. NVFP4 on Blackwell delivers 4x higher throughput compared to FP8 on H100 while maintaining accuracy. Follow these instructions to get started:
Install vLLM
pip install vllm==0.17.1Serve the model
You can serve Nemotron 3 Super via an OpenAI-compatible API. The command below is configured for a 4x H100 setup. If your hardware differs, adjust the parallelism flags and related settings for your environment. Refer to the cookbooks for detailed instructions for FP8 and NVFP4.
# BF16
vllm serve nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 \
--kv-cache-dtype fp8 \
--tensor-parallel-size 4 \
--trust-remote-code \
--served-model-name nemotron \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3Once the server is up and running, you can prompt the model using the below code snippet:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
# Simple chat completion
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Give me 3 bullet points about vLLM"}
],
temperature=0.7,
max_tokens=256,
)
print("Reasoning:", resp.choices[0].message.reasoning_content,
"\nContent:", resp.choices[0].message.content)For an easier setup with vLLM, refer to our getting started cookbook, available here or use NVIDIA Brev launchable.
Highest efficiency with leading accuracy for multi-agent applications
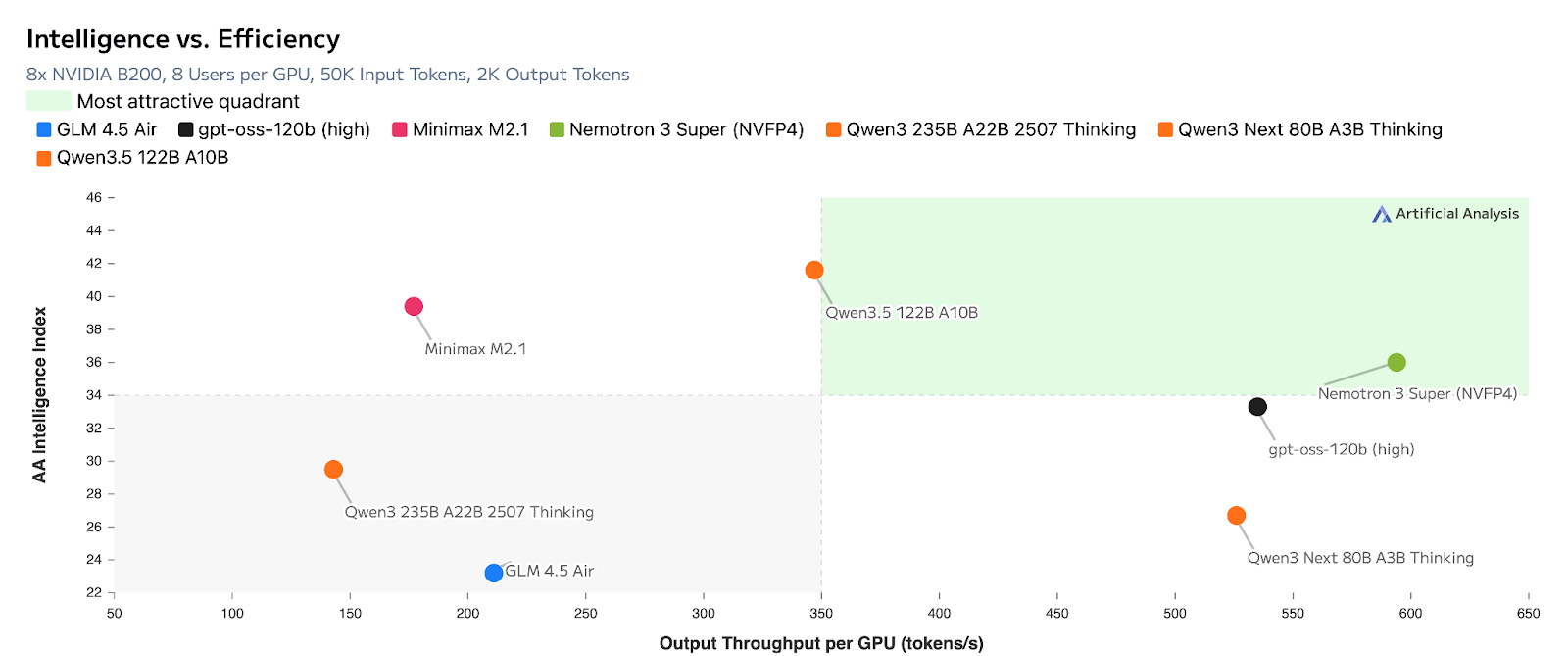
Figure 2: Artificial Analysis chart showing Nemotron 3 Super leading on intelligence vs. efficiency when compared to popular open models of similar size
As you can see in the chart above, the model achieves leading accuracy with higher efficiency on Artificial Analysis benchmarks, making it a strong choice for multi-agent systems that need both efficiency and capability.
Get started
Nemotron 3 Super helps you build scalable, cost-efficient multi-agent AI with high accuracy. With open weights, datasets, and recipes, you get full transparency and the flexibility to fine-tune and deploy on your own infrastructure, from workstation to cloud.
Ready to run multi-agent AI at scale?
- Download Nemotron 3 Super model weights from Hugging Face - BF16, FP8 and NVFP4
- Run with vLLM for inference using the cookbook and through Brev launchable
- Read the Nemotron 3 Super technical report
Stay up to date on NVIDIA Nemotron by subscribing to NVIDIA news and following NVIDIA AI on LinkedIn, X, YouTube, and the Nemotron channel on Discord.
Acknowledgement
Thanks to everyone who contributed to bringing Nemotron 3 Super to vLLM.
- NVIDIA: Nirmal Kumar Juluru, Anusha Pant
- vLLM team and community: Roger Wang, Michael Goin, Thomas Parnell, Kevin Luu, Robert Shaw, Tyler Michael Smith