TML Inkling on vLLM: Day-0 Support with Optimized Performance
·8 min read
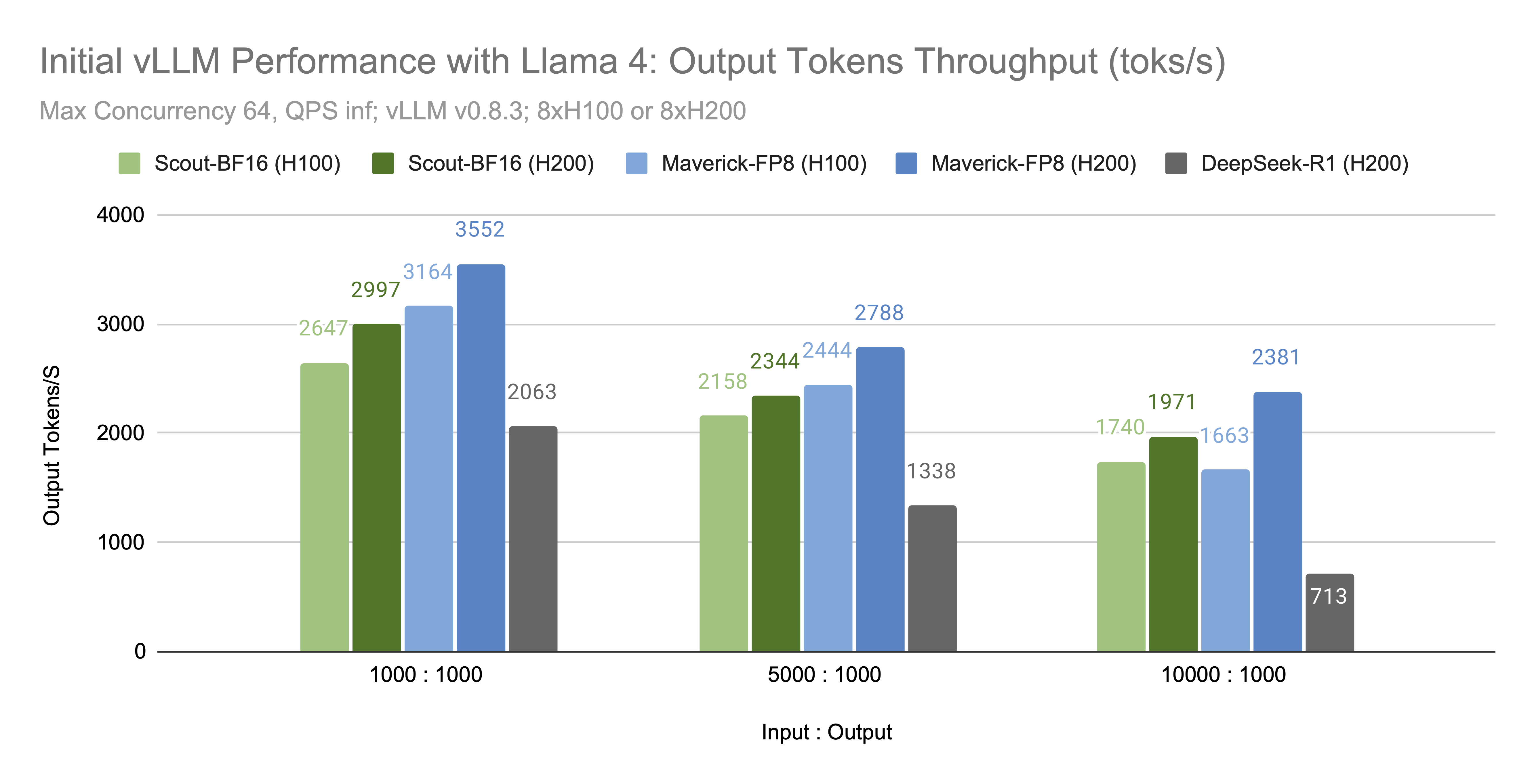
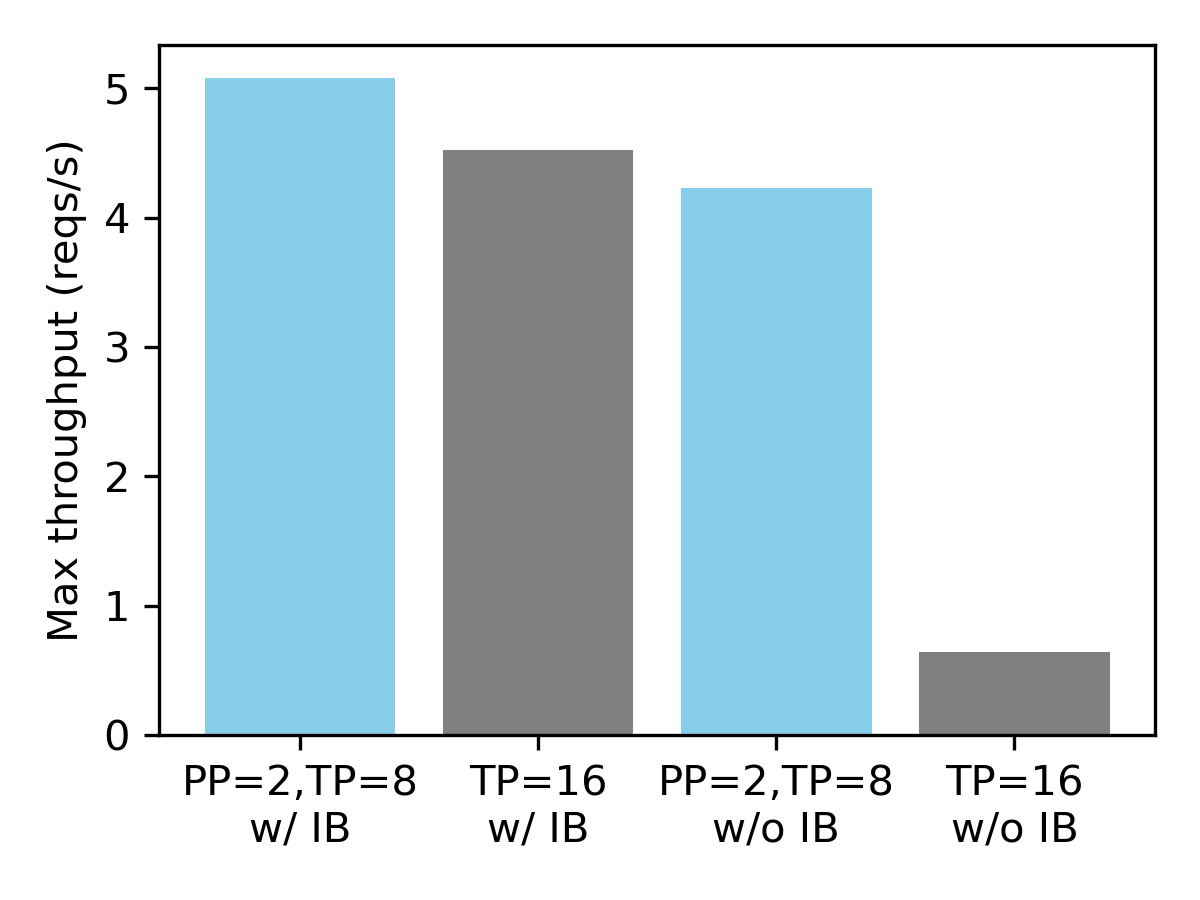
vLLM brings day-0 support to TML Inkling, a 1T-parameter multimodal model, with MTP, long-context serving, parallelism, and up to 380 tokens per second per user on NVIDIA GB200 GPUs.