Accelerating Laguna XS.2 Inference with vLLM, Speculators, and LLM Compressor
·3 min read
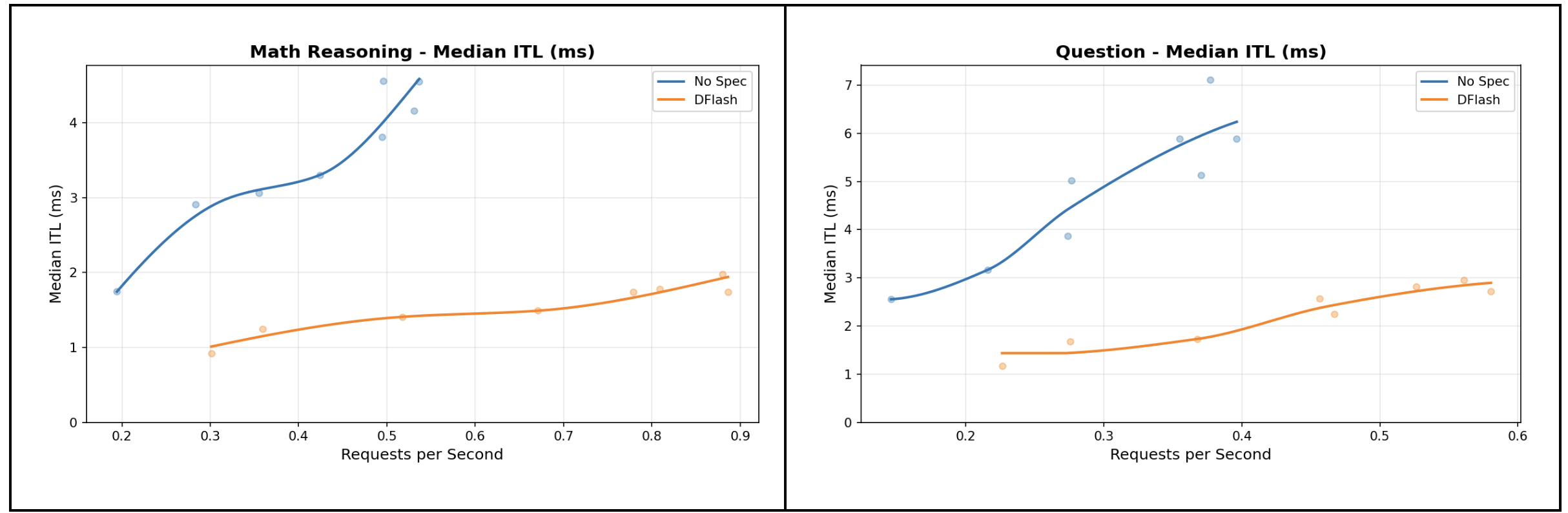
How Laguna XS.2 is served and optimized in vLLM using first-class model integration, a DFlash speculator trained with Speculators, and FP8, NVFP4, INT4, and INT8 checkpoints from LLM Compressor.