Accelerating Laguna XS.2 Inference with vLLM, Speculators, and LLM Compressor
As organizations increasingly adopt AI-powered development tools, the need for high-performance agentic models that deliver both accuracy and operational efficiency has become critical. Laguna XS.2 is Poolside's first open-weight model in the Laguna family: a 33B-A3B MoE model built for agentic coding and long-horizon software tasks. As part of the Laguna XS.2 release, Red Hat AI and Poolside collaborated on serving and inference optimization, including first-class vLLM integration, a DFlash speculator checkpoint, and quantized checkpoints built with LLM Compressor. This release represents a significant milestone in production-ready AI deployment, with Laguna XS.2's quantized and speculator checkpoints optimized for speed and efficiency in real-world agentic applications.
Seamless Inference via vLLM Integration
In collaboration with Poolside, Laguna XS.2 was integrated directly into vLLM at launch as a first-class citizen, enabling immediate deployment through standard vLLM APIs.
Optimizing Performance with DFlash Speculative Decoding
To accelerate inference further, the Red Hat team trained a DFlash speculator for Laguna XS.2 using the Speculators library.
The DFlash algorithm is the current state of the art in speculative decoding. The model uses a small 5-layer, 0.6B draft model and hidden state inputs from the target Laguna XS.2 model to predict a block of tokens with a single forward pass. These tokens are then verified by the Laguna XS.2 model with a single pass. This verification step guarantees the same generation quality as using the large model alone; if the tokens are accepted, then they can be produced much more quickly per token than simply producing tokens one at a time using Laguna XS.2 autoregressively. The key is training DFlash to accurately predict tokens that Laguna XS.2 is likely to accept.
This model was trained on 500k samples from Ultrachat 200k SFT and Magpie-Align. Prompts were sampled from each dataset and responses were regenerated from Laguna XS.2, with thinking enabled. The model was then trained for 6 epochs using a cosine scheduler with a maximum learning rate of 6e-4, with a sequence length of 8192, and 3072 block positions were randomly sampled for each sequence.
The result is a 5-layer drafter that can predict 8 tokens out with a single forward pass. When verified with Laguna XS.2, it delivers tokens 2-3x faster with provably no loss in generation quality.
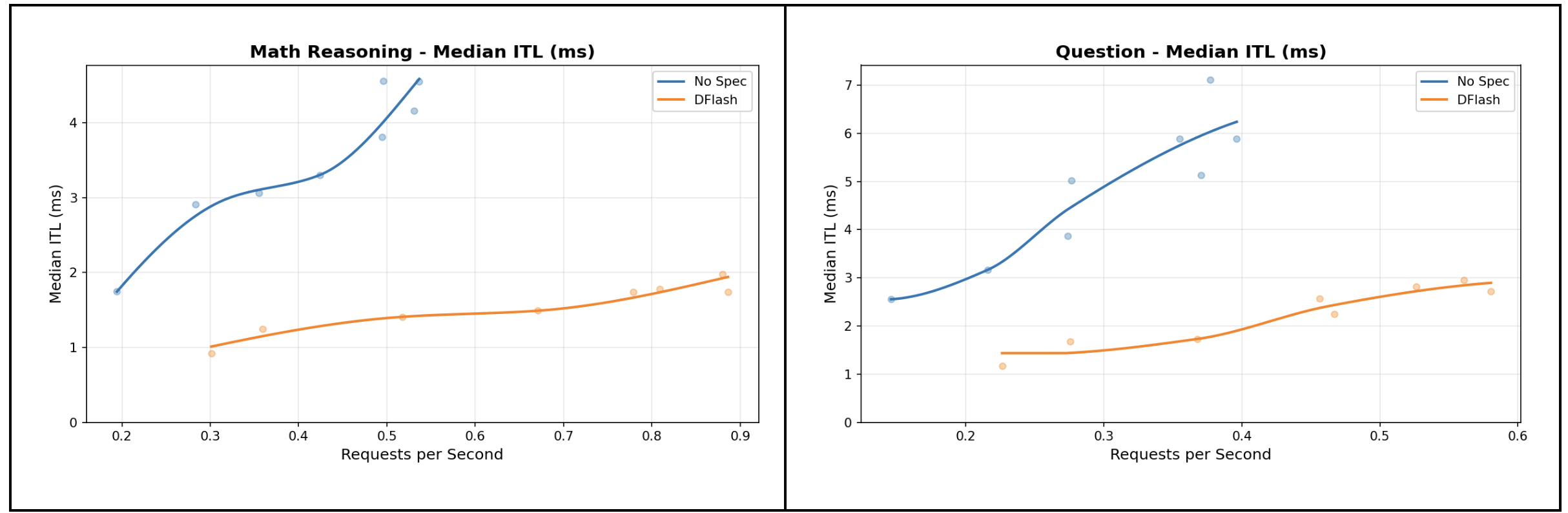
The DFlash algorithm represents the next generation of speculative decoding, moving beyond the Eagle-3 paradigm to provide faster, parallel drafting that significantly reduces inter-token-latency. To test out the speculator yourself, check out the vLLM recipe.
Quantized Checkpoints with LLM Compressor
The Poolside team also released quantized Laguna XS.2 checkpoints using the LLM Compressor library. These checkpoints include FP8, NVFP4, INT4/INT8 variants in the compressed-tensors format to enable efficient deployment while maintaining model quality in vLLM.
LLM Compressor provides a flexible framework for applying various quantization techniques to LLMs. With these checkpoints, developers can choose the Laguna XS.2 variant that best fits their hardware, latency, and memory requirements.
Next Steps
- Explore the Laguna XS.2 models on the Hugging Face Hub
- Optimize your own models with LLM Compressor and Speculators