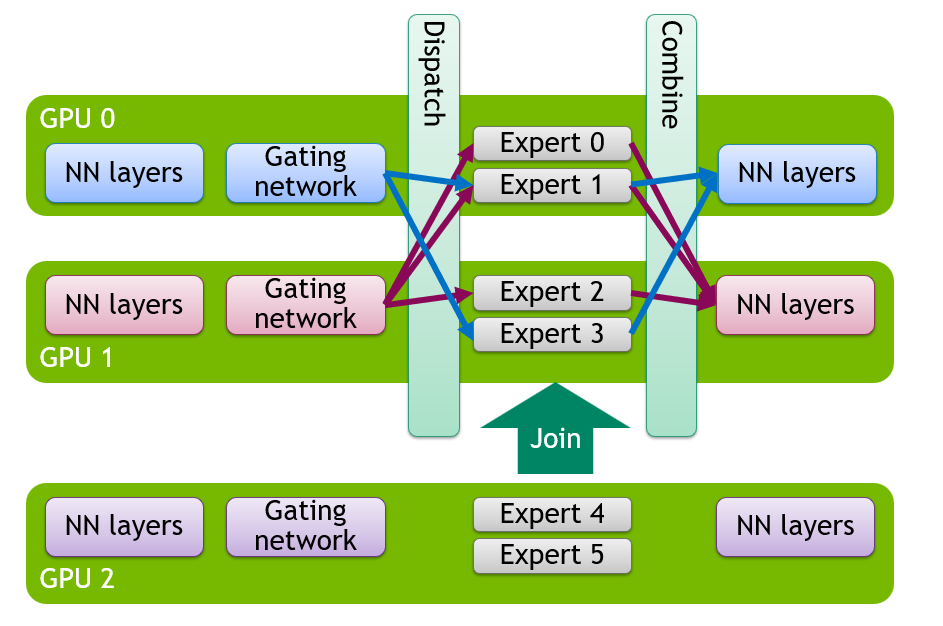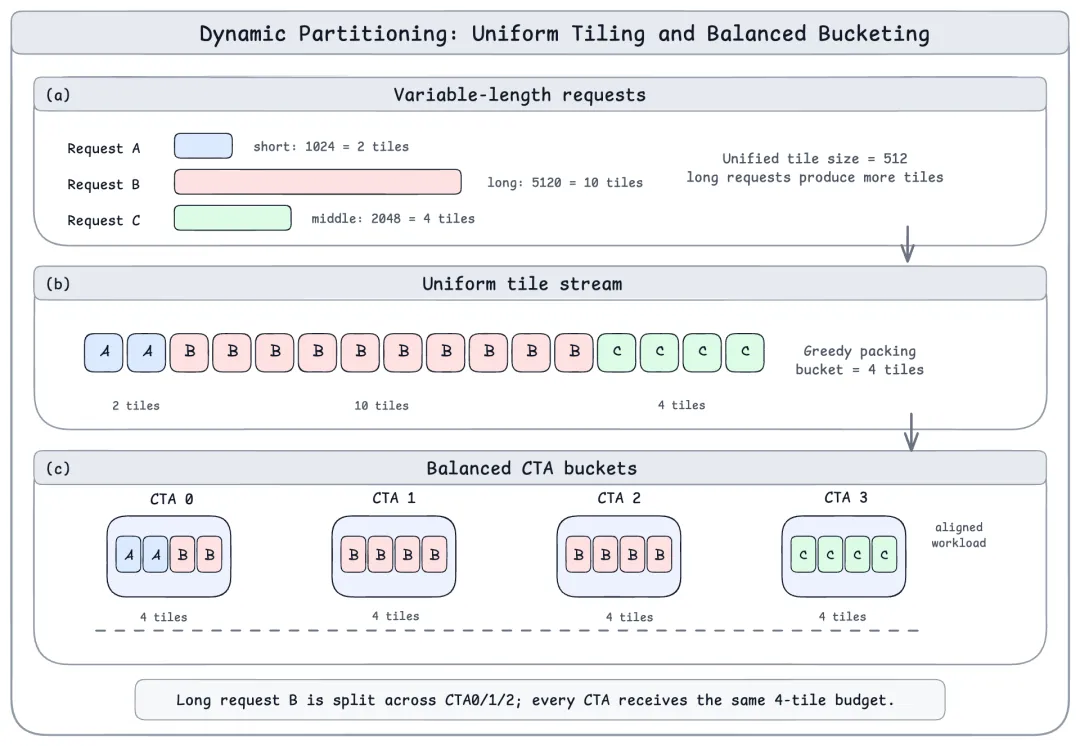
vLLM × HPC-Ops: High-Performance Attention and MoE Backends from Tencent Hunyuan
·12 min read
How HPC-Ops integrates Hopper-optimized attention and FP8 MoE backends into vLLM for Tencent Hunyuan Hy3, improving mixed-length decode, MoE latency, TTFT, and TPOT on NVIDIA H20.