Announcing VeRL-Omni: Easy, Fast, and Stable RL Training for Diffusion and Omni-Modality Models
We are excited to announce the pre-release of VeRL-Omni, a general reinforcement learning (RL) post-training framework focused on multimodal generative models, built on top of verl and vllm-omni.
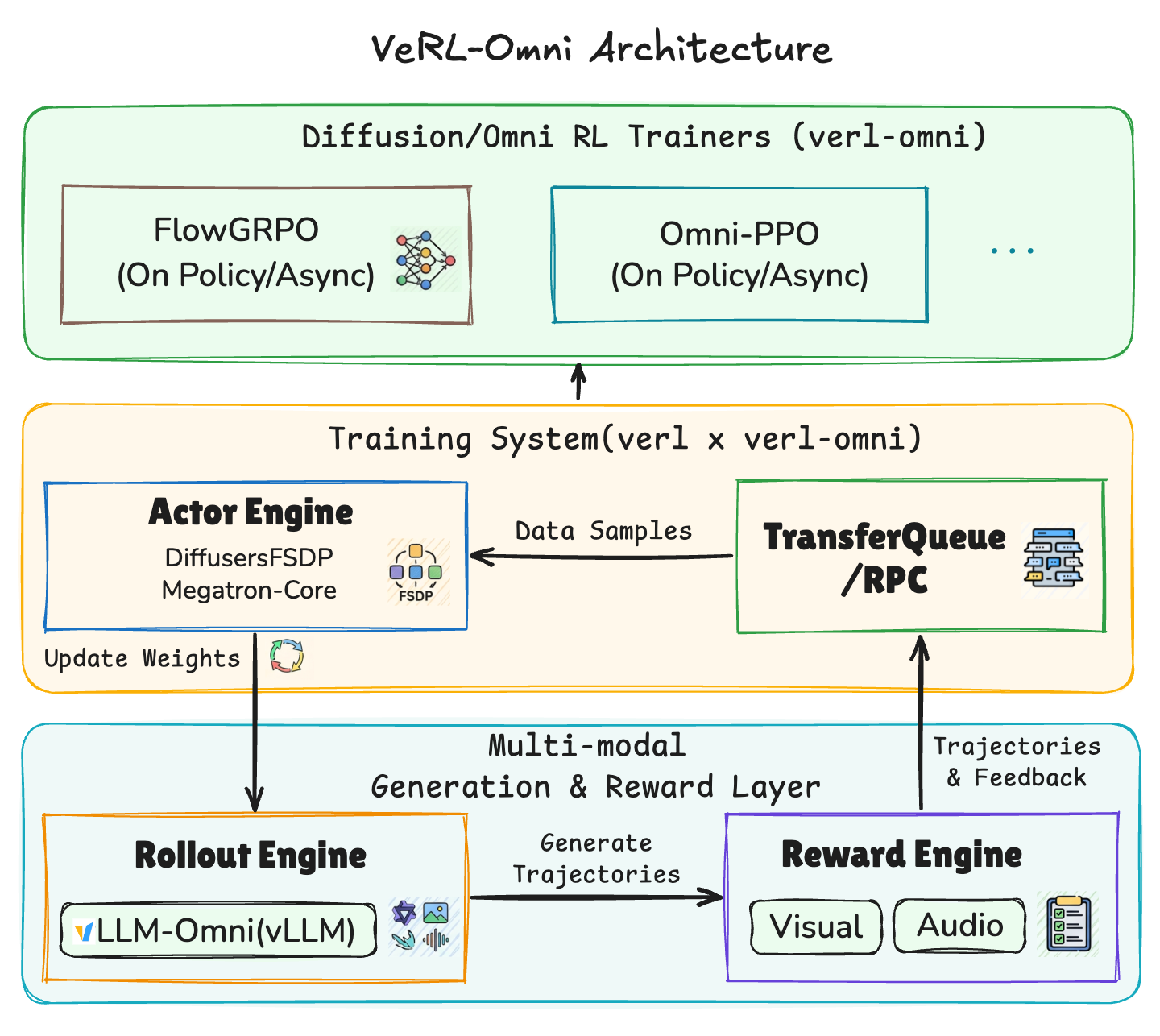
Why VeRL-Omni?
RL has become a powerful method for aligning large generative models with human preferences and downstream task rewards. While the LLM RL stack has evolved rapidly over the past year, multimodal generative RL, covering diffusion and omni-modality models for image/video/audio understanding and generation, faces critical needs:
- Diffusion and omni-modality extension: Extending verl's exceptional flexibility and performance to the world of multi-modal and non-autoregressive RL training, covering diffusion transformer backbones (Qwen-Image), mixed AR-DiT architectures (Qwen-Omni), and unified understanding & generation models (BAGEL, HunyuanImage3.0).
- Heterogeneous rollout pipelines: Rollouts are denoising trajectories in a continuous latent space rather than token sequences, and a single rollout may invoke multiple heterogeneous model components and multi-stage pipelines (e.g., text encoder → DiT → VAE).
- Complex workload scheduling: Orchestrating complex multi-modal RL training workflows, where reward functions are themselves multimodal models (VLM judges, OCR scorers, etc.) and multi-modal generation rollouts have higher memory peaks compared to text generation.
Key Features
- Efficient multimodal rollout: We integrate vLLM-Omni for its high-throughput async serving for multimodal generation while maintaining accuracy on par with diffusers. VeRL-Omni works with vLLM-Omni to continuously optimize rollout efficiency via step-wise continuous batching, embedding caching, etc.
- Flexible reward engine: Spanning rule-based rewards and model-based rewards (e.g. VLM-as-judge for OCR). vLLM is integrated for efficient VLM and LLM reward model inference. Reward computation is overlapped with ongoing rollout and training processes to reduce end-to-end latency.
- Modular training backends: Provide various trainers (DiffusersFSDP/Megatron/VeOmni) with built-in optimization for diffusion and omni-modal models, allowing easy integration of different parallelism strategies (FSDP/USP/TP).
- Broad hardware compatibility: Supports both NVIDIA GPUs and Ascend NPUs, allowing flexible deployment across diverse hardware backends.
- E2E training recipes and benchmarks: Provided with reference performance results, which can achieve high training throughput thanks to the above features.
Algorithm and Model Support
| Model | Architecture | Modality | Algorithm | Status |
|---|---|---|---|---|
| Qwen-Image | DiT | Text → Image | FlowGRPO, MixGRPO, GRPO-Guard | Released |
| BAGEL | Unified understand + gen | Text + Image | FlowGRPO | PR ready |
| Qwen3-Omni-Thinker | AR | Text / Image / Video / Audio | GSPO | PR ready |
| Wan2.2 | DiT | Text → Video | DanceGRPO | WIP |
| SD3.5 | DiT | Text → Image | DPO | WIP |
| HunyuanImage-3.0 | Unified understand + gen | Text + Image | MixGRPO, SRPO | Planned |
Getting Started
Installation
Check out our Installation Doc for details.
Training diffusion models
Check out our examples directory for specific scripts to launch different RL algorithm trainers for image/audio/video understanding and generation tasks. You can track the training performance and results via wandb.
Demo: Qwen-Image FlowGRPO Post-training
In the flowgrpo example, we train Qwen-Image with the OCR reward task. The reward model is Qwen3-VL-8B-Instruct, scoring generated images by reading the rendered text and comparing it against the dataset ground truth.
Algorithm Review
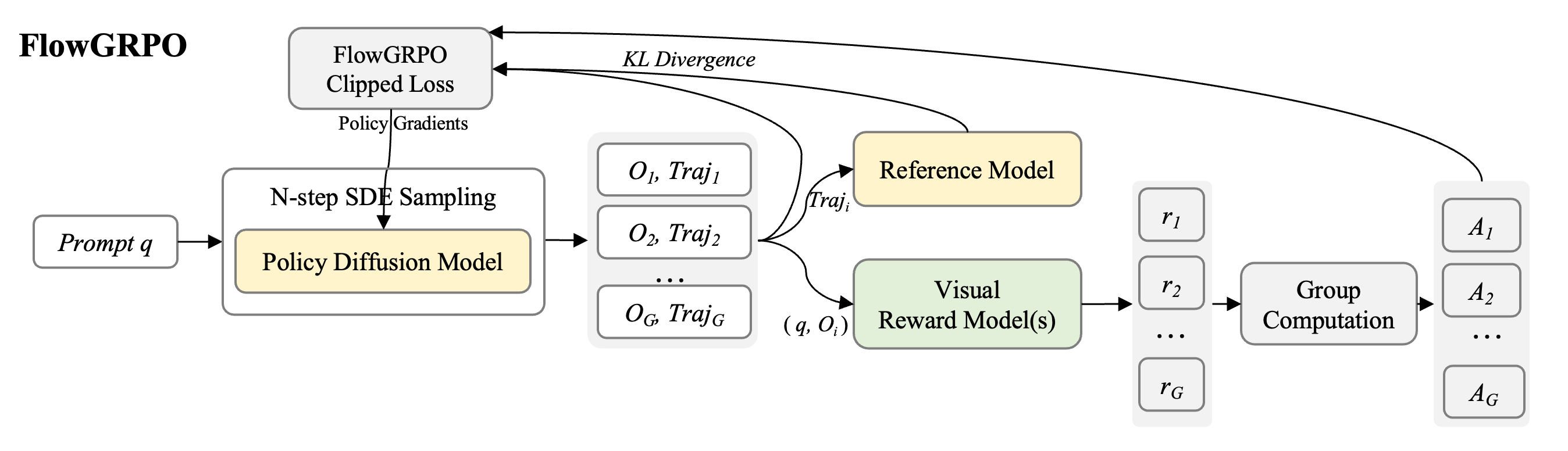
FlowGRPO Demonstration
FlowGRPO is an online policy method for flow-matching models. It employs multi-step SDE sampling with a diffusion policy model to enable effective RL exploration, and adopts model-based rewards to assess generation quality. The training workflow mainly consists of four key stages:
- Rollout Generation: The diffusion policy model generates sample rollouts, collecting trajectories of log probabilities and generated images.
- Reward Model Scoring: The reward model scores each generated sample, allowing the computation of trajectory advantages.
- Policy Optimization: The policy is updated using a FlowGRPO CLIP-style loss, optimizing for higher reward using the computed advantages.
- Weight Synchronization: Periodically, the latest policy weights from the trainer are synchronized to the rollout workers, ensuring that generated samples reflect the most recent policy.
LoRA fine-tuning
The training throughput on NVIDIA H800 GPUs is as follows.
| Mode | # GPUs | Actor | Rollout | Async Reward | Throughput (images/GPU/s) | Time per Step (s) |
|---|---|---|---|---|---|---|
| FlowGRPO colocated training | 4 | 4 | 4 | 0 (sync) | 0.305 | 420 |
| FlowGRPO w/ async reward | 5 | 4 | 4 | 1 (async) | 0.280 | 360 |
Moving the reward model to its own dedicated GPU reduces wall-clock time per step by ~14% by overlapping reward evaluation with policy training.
Full-model fine-tuning
We have also validated non-CFG full-model Qwen-Image OCR training on 4 × NVIDIA H200 GPUs, reaching 0.510 images/GPU/s at ~250 s/step.
As shown below, the text rendering quality of the generated images is largely enhanced in 120 training steps.
| Prompt | Training Step 0 | Training Step 120 |
|---|---|---|
| A wooden trail marker in a dense forest with "Hidden Trail" carved into the wood, surrounded by moss and foliage. |  |
 |
| A birthday card interior with "Make A Wish" in cursive handwriting, surrounded by sparkling candles and colorful confetti. |  |
 |
Below are reward and training curves from our reference runs. Both the critic reward and validation reward converge stably during training.
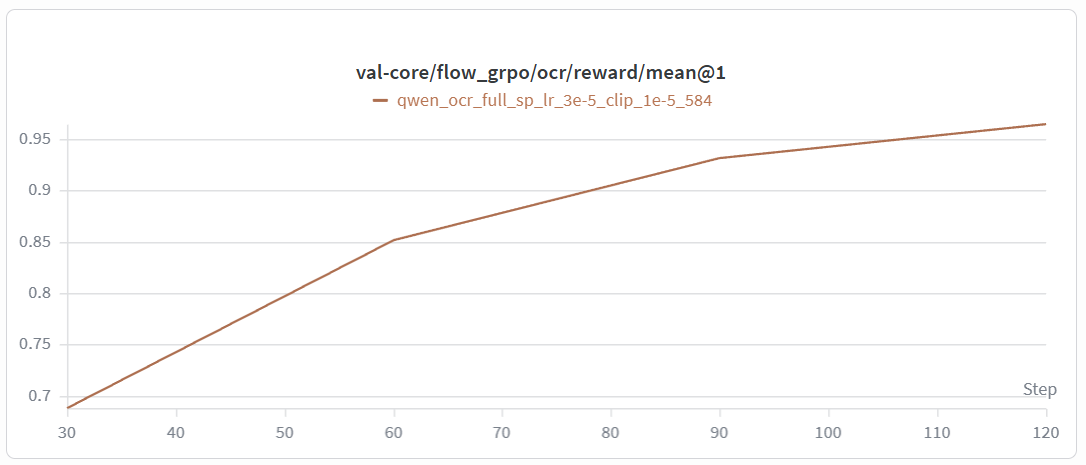 validation reward increases stably |
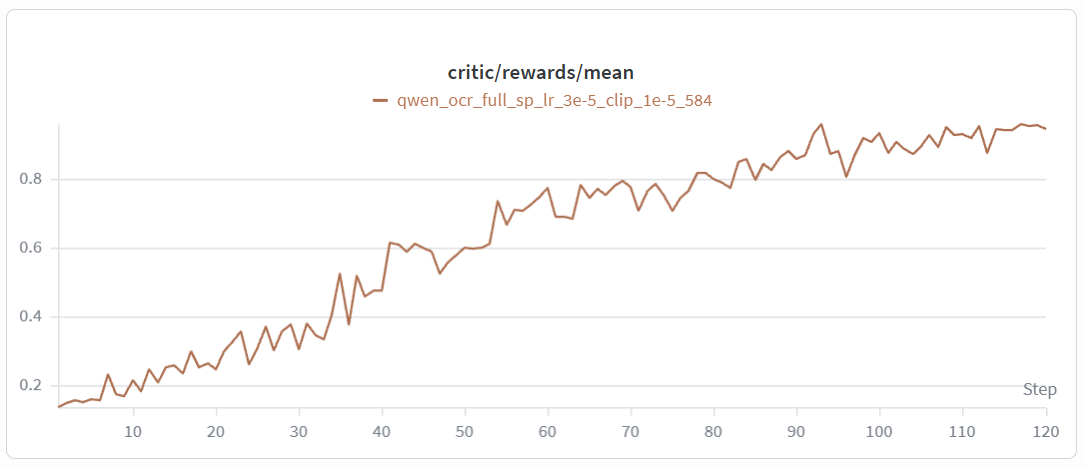 rollout reward mean increases (low start expected for non-CFG rollout) |
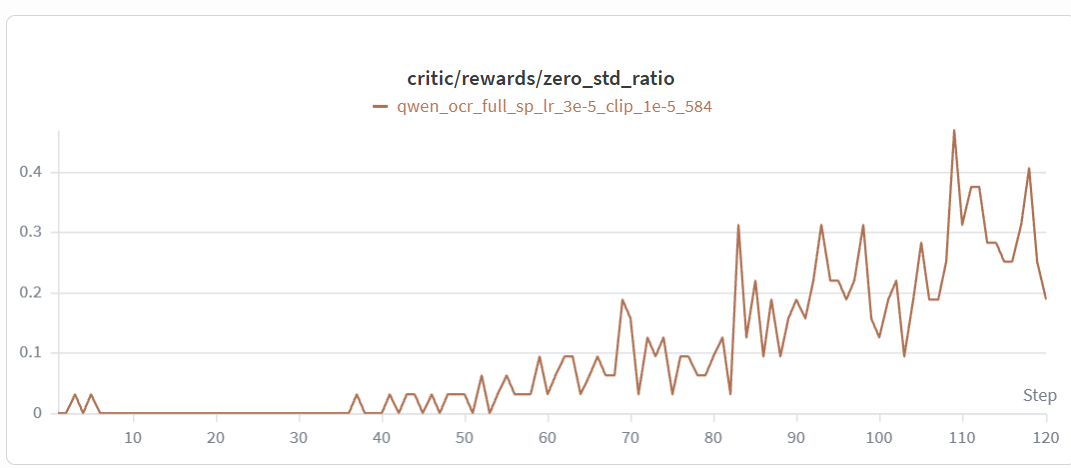 zero-std ratio climbs only after reward saturates |
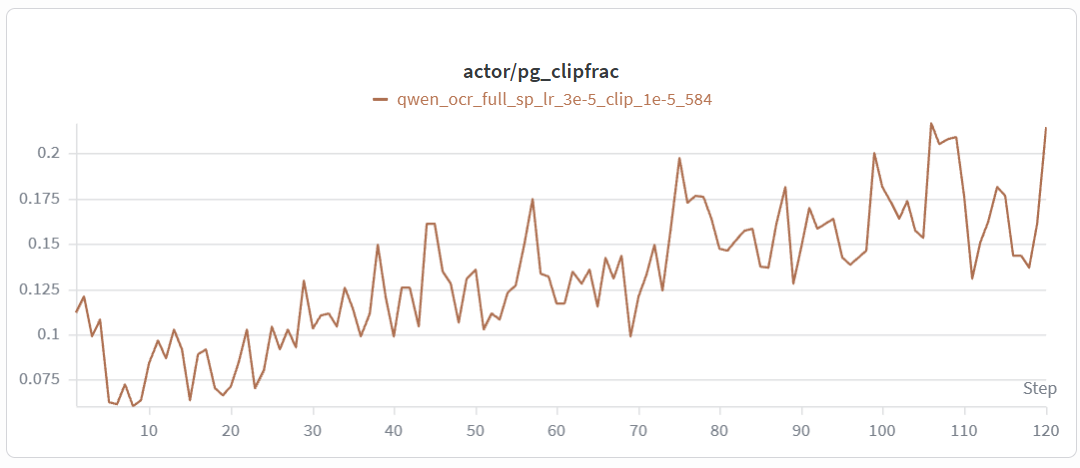 clip ratio stays in healthy range |
For a detailed overview of training metrics, please see our Training Metrics documentation.
Future Roadmap
VeRL-Omni is actively evolving and currently in pre-release, with a stable core diffusion RL stack. Our roadmap is focused on expanding model and algorithm support, and pushing the boundaries of efficient multi-modal RL training.
- Model Support Extension: Support a wide range of open-source diffusion and omni-modal models as they emerge, covering image/video/audio generation tasks and unified understanding & generation tasks.
- Algorithm Support Extension: Integrate stable and advanced RL algorithms as they are proposed, such as DiffusionNFT.
- Fully Asynchronous RL: End-to-end async pipelines across actor, rollout, and reward, beyond the current async-reward setup, in order to improve the training throughput and GPU/NPU utilization.
- Co-optimization with vLLM-Omni: Generation rollout accounts for a large portion of training time. We expect to further accelerate multimodal rollout by closely integrating with vLLM-Omni, leveraging advanced techniques such as parallelism, quantization, batching, and optimized request scheduling.
- Efficient Omni-modal Trainer: Besides DiffusersFSDPTrainer, we expect to release more highly-optimized trainer engines for omni-modality and diffusion models, based on Megatron-core and VeOmni.
- Broader hardware support: Continuing to harden the Ascend NPU path and welcoming additional hardware backends through the hardware plugin system.
Join the Community
This is just the beginning for diffusion and omni-modal RL post-training. We are actively developing support for more architectures and algorithms, and invite the community to help shape the future of VeRL-Omni.
- Code: github.com/verl-project/verl-omni
- Docs: verl-omni.readthedocs.io
- Contribution Guideline: see
CONTRIBUTING.md - Weekly Meeting: Join us every Tuesday at 11:00AM (GMT+8:00) to discuss roadmap and features. Join here
Let's build the future of omni-modal RL together!