Announcing vime: A Simple, Stable, and Efficient RL Framework for LLMs
We are excited to introduce vime, an LLM post-training framework within the vLLM ecosystem. Built on slime's training stack and data-generation design, vime connects Megatron and vLLM into a single RL pipeline so distributed training and inference can run reliably under one unified architecture.
slime has proven itself as a strong engineering paradigm for RL post-training: open, lightweight, and efficient. vime brings the vLLM ecosystem to slime, pairing slime's training stack with vLLM's inference strengths into a simple, stable, and efficient main pipeline—delivering stable train-inference alignment, flexible deployment modes, and full-stack GPU support.
Our Vision
RL frameworks with both battle-tested credibility and open-source DNA have always been rare. slime, validated on models like GLM, stands out as a representative: open, lightweight, concise, and efficient. Yet it does not natively integrate with the vLLM backend. vLLM, meanwhile, is the most active inference engine in the community, combining cutting-edge techniques with a multi-platform ecosystem and rapid iteration.
vime's mission is to connect slime's training design with vLLM's inference strengths into one simple, stable, and efficient pipeline. Developers should not have to trade off between a single hardware stack, training stability, and inference performance.
Positioning
The vLLM community supports a broad set of LLM post-training frameworks, including (in alphabetical order) NeMo RL, OpenRLHF, verl, and others. We built vime to seamlessly bring slime's proven training paradigm into the vLLM ecosystem, offering a production-ready bridge that aligns both projects' rapid release cycles.
We hope that users with different needs can find the right vLLM-ecosystem choice for their workflows. The vLLM community will continue to support vLLM integrations across the broader post-training ecosystem.
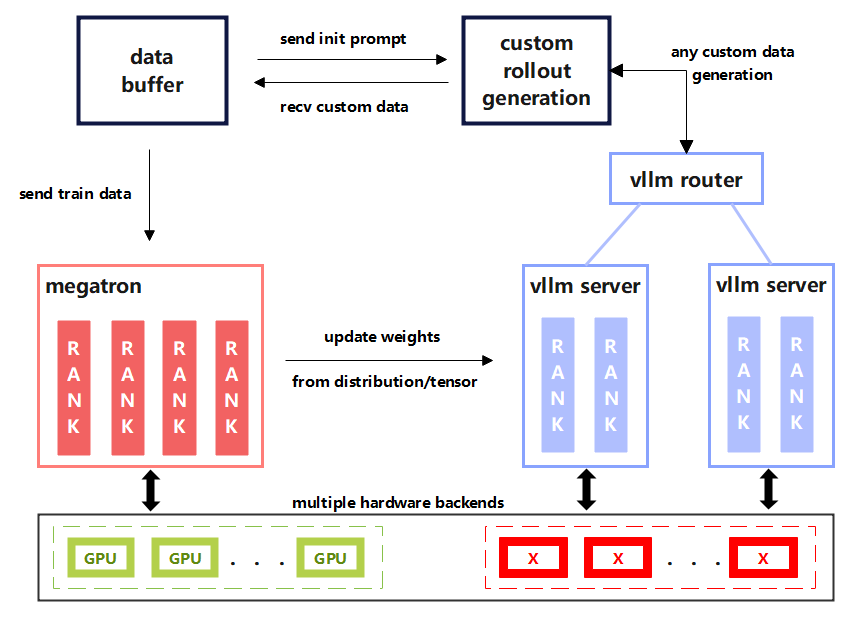
Architecture Overview
vime adopts slime's three-stage, decoupled train-inference design, with the key difference being that the rollout backend is replaced by vLLM:
- Training (Megatron): The main training loop, responsible for parameter updates and synchronizing weights to the rollout side.
- Rollout (vLLM + Router): Inference sampling, producing training samples with reward or verifier signals.
- Data Buffer: Connects the training and rollout sides, managing prompt injection and custom rollout logic.
Key Capabilities
- Easy to use: The parameter system inherits slime and Megatron conventions, with vLLM-side arguments passed through using the
--vllm-prefix. The default rollout entry point isvime.rollout.vllm_rollout. - Stable train-inference alignment: Across typical Dense and MoE scenarios,
train_rollout_logprob_abs_diffstays within a controllable range over long runs. For MoE, R3 (routing replay) further reduces train-inference mismatch. - Algorithm and model coverage: RL algorithms such as GRPO and PPO, plus models including Qwen3 Dense/MoE and GLM-4.5, ship with end-to-end examples and CI-verified paths.
- Multi-hardware support: At the framework level, training resources, rollout resources, and cluster topology are abstracted uniformly, making it easier to reuse the same RL pipeline across different hardware backends as support evolves with the vLLM ecosystem.
Validation and Benchmarks
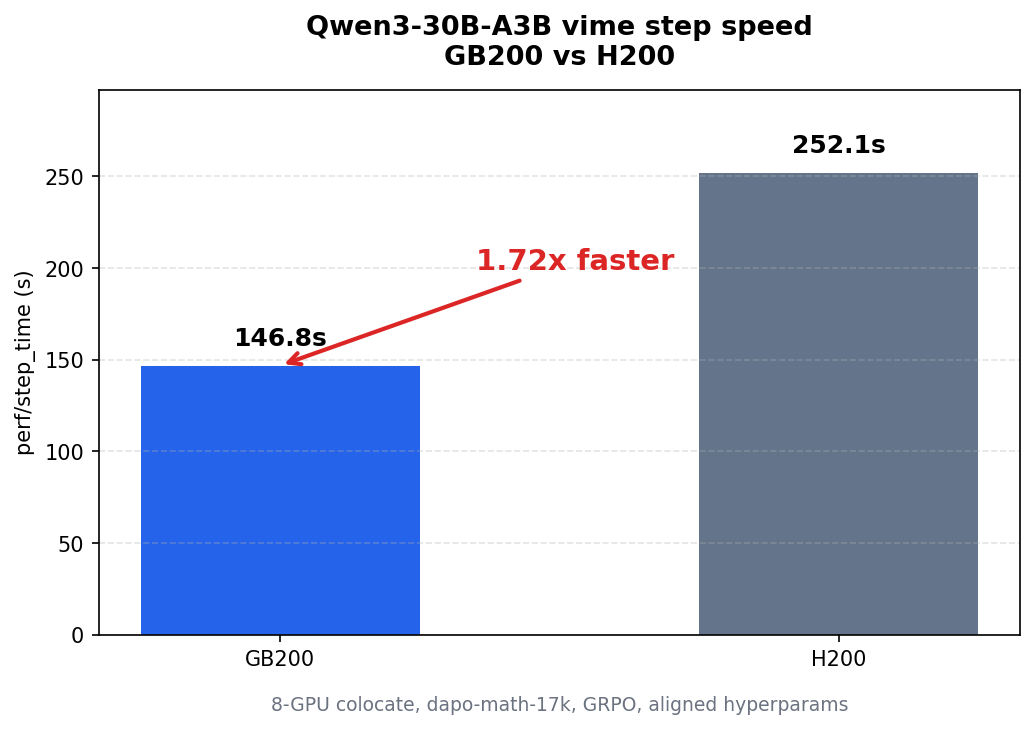
For Qwen3-30B-A3B with 8-GPU colocate, dapo-math-17k, and GRPO, GB200 mean step time is about 147 seconds, while H200 mean step time is about 252 seconds. Under the same framework, GB200 end-to-end step speed is about 1.72x that of H200.
We also validated train-inference consistency and end-to-end functionality on representative workloads across hardware.
Qwen3-4B on A100
For Qwen3-4B on A100 with GRPO, 4 training + 4 inference non-colocate, and gsm8k, vime's train_rollout_logprob_abs_diff stays stable around 0.011 throughout training. The baseline drifts continuously to around 0.77 as training progresses, while vime delivers more stable train-inference alignment.
Qwen3-30B-A3B MoE with R3
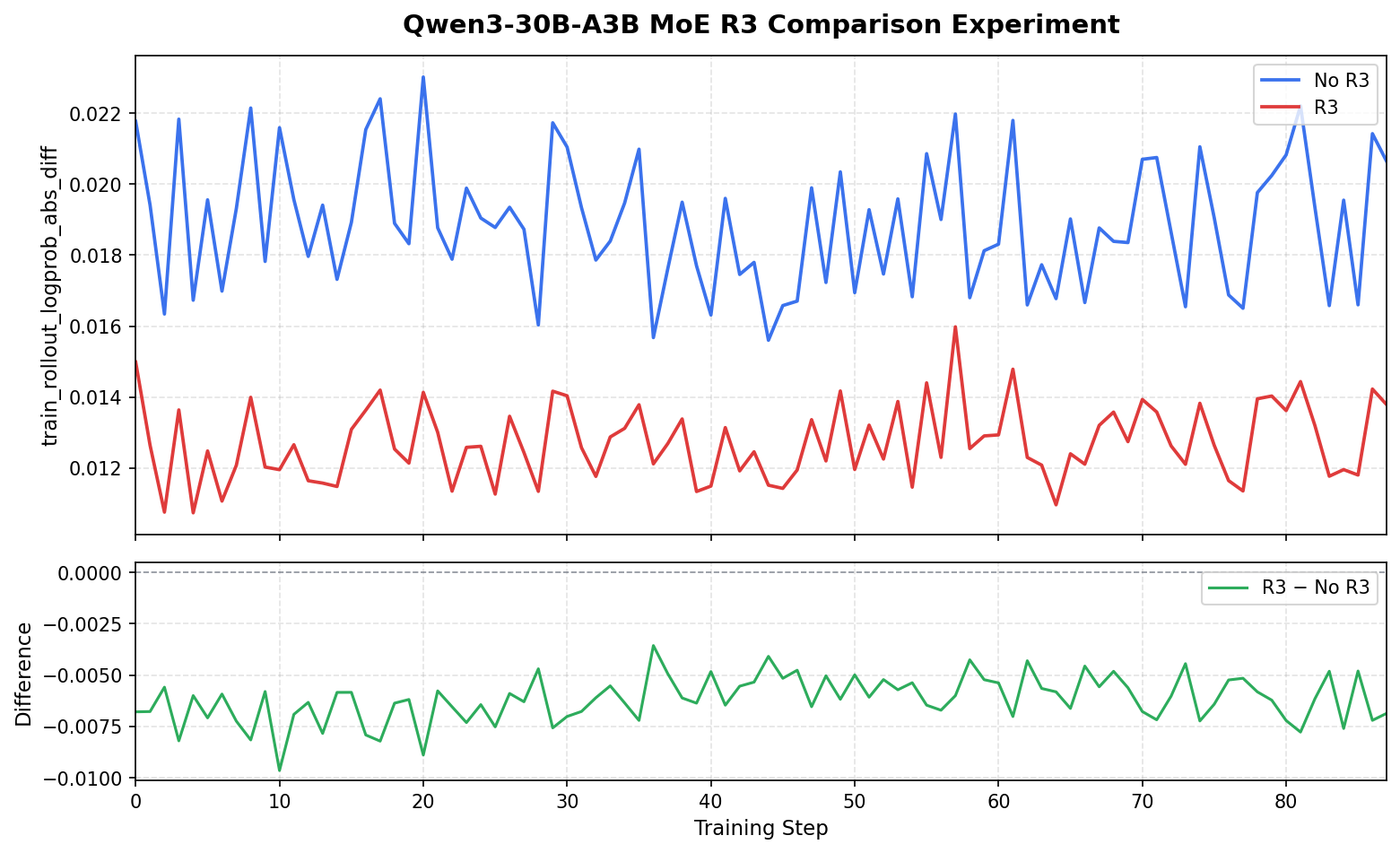
For Qwen3-30B-A3B MoE on A100 with 4 training GPUs, 4 inference GPUs, dapo-math-17k, and EP=4, enabling vime's R3 routing replay reduces the logprob diff from roughly 0.019 to roughly 0.013, markedly reducing MoE train-inference mismatch.
Qwen3-30B-A3B MoE on GB200
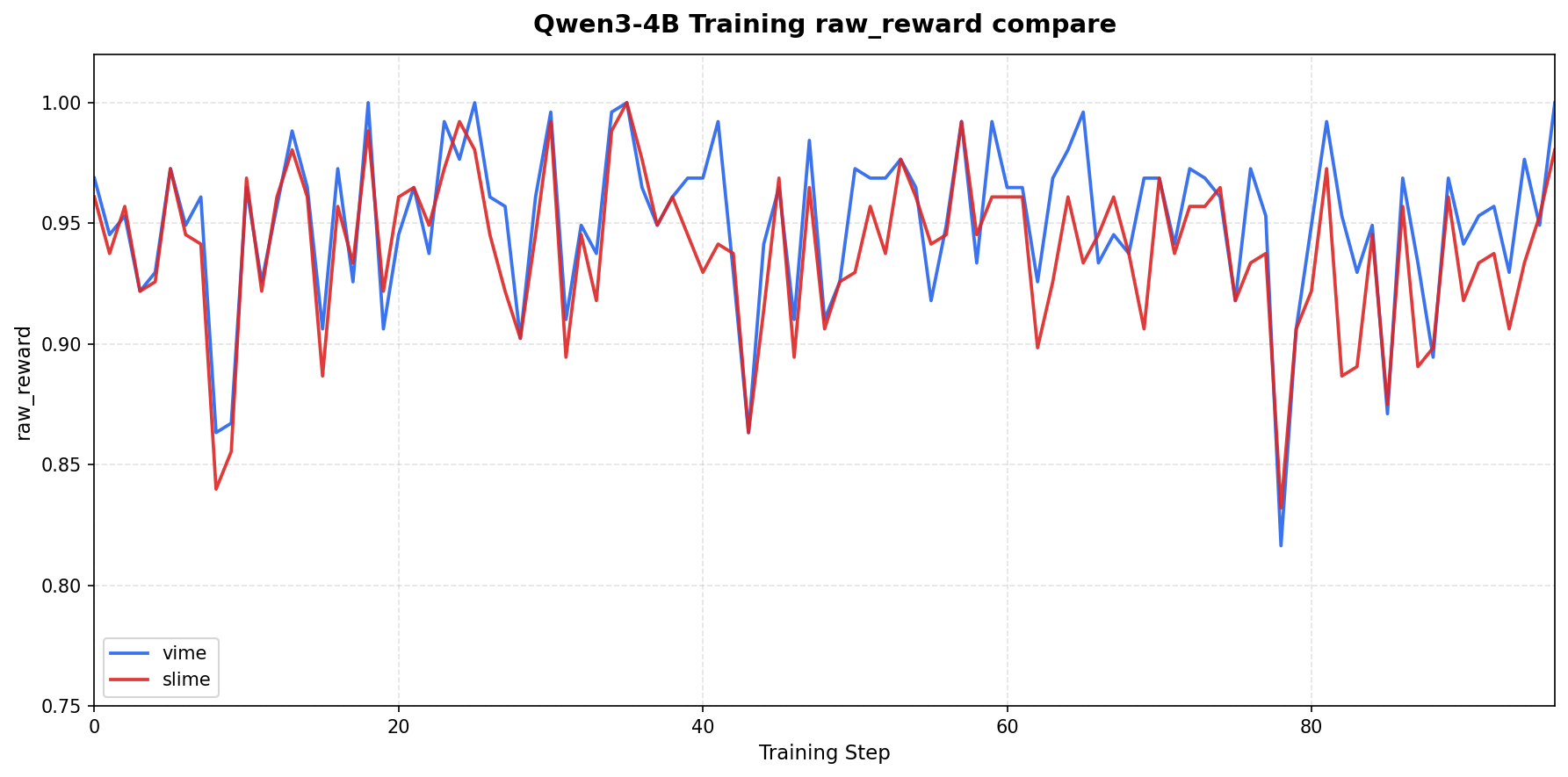
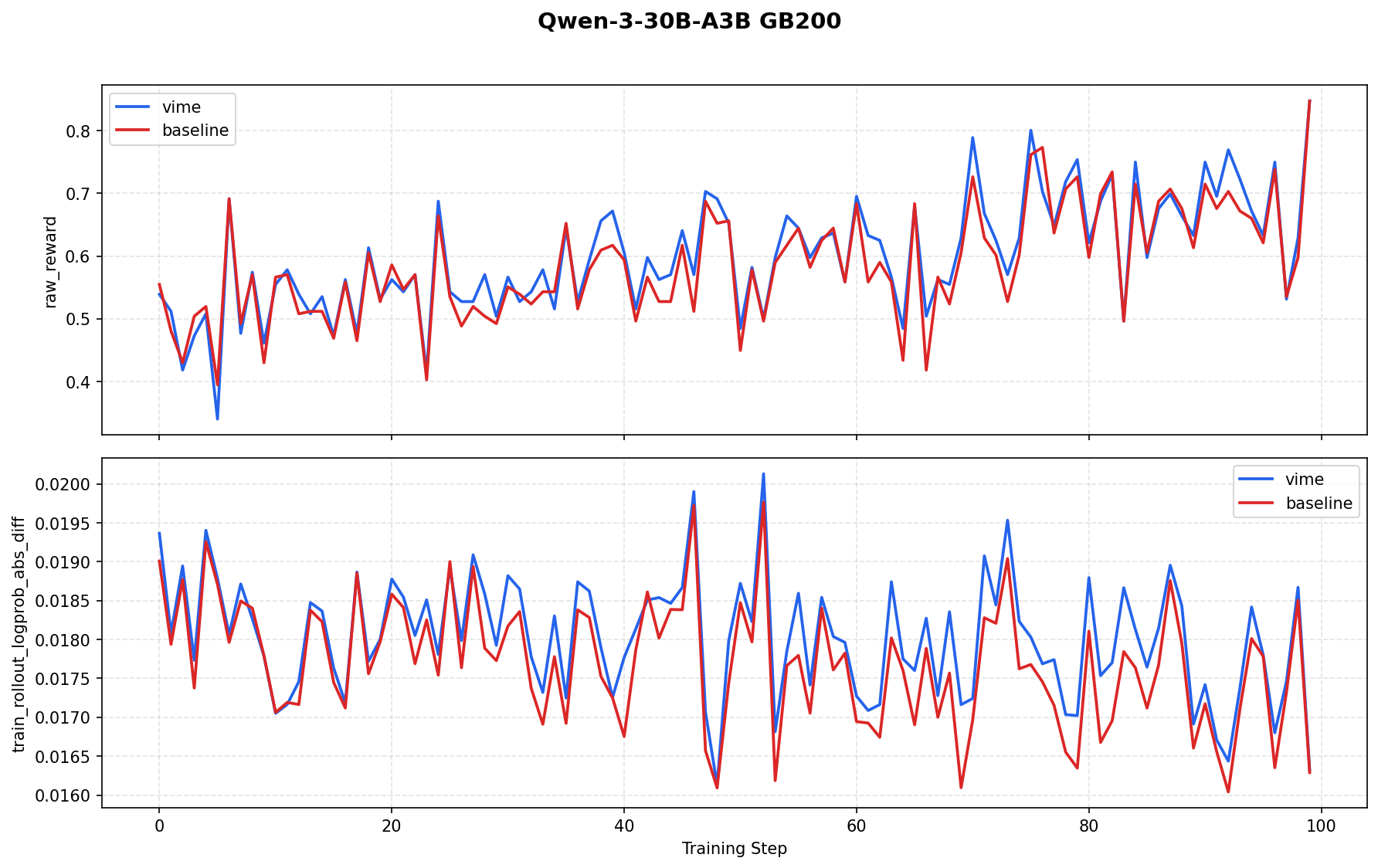
For Qwen3-30B-A3B MoE on GB200 with 8-GPU colocate and dapo-math-17k, vime and the baseline have closely aligned raw_reward curves. Both keep train_rollout_logprob_abs_diff stable around 0.018, with no sustained baseline-side drift.
GLM-4.5-Air on GB200
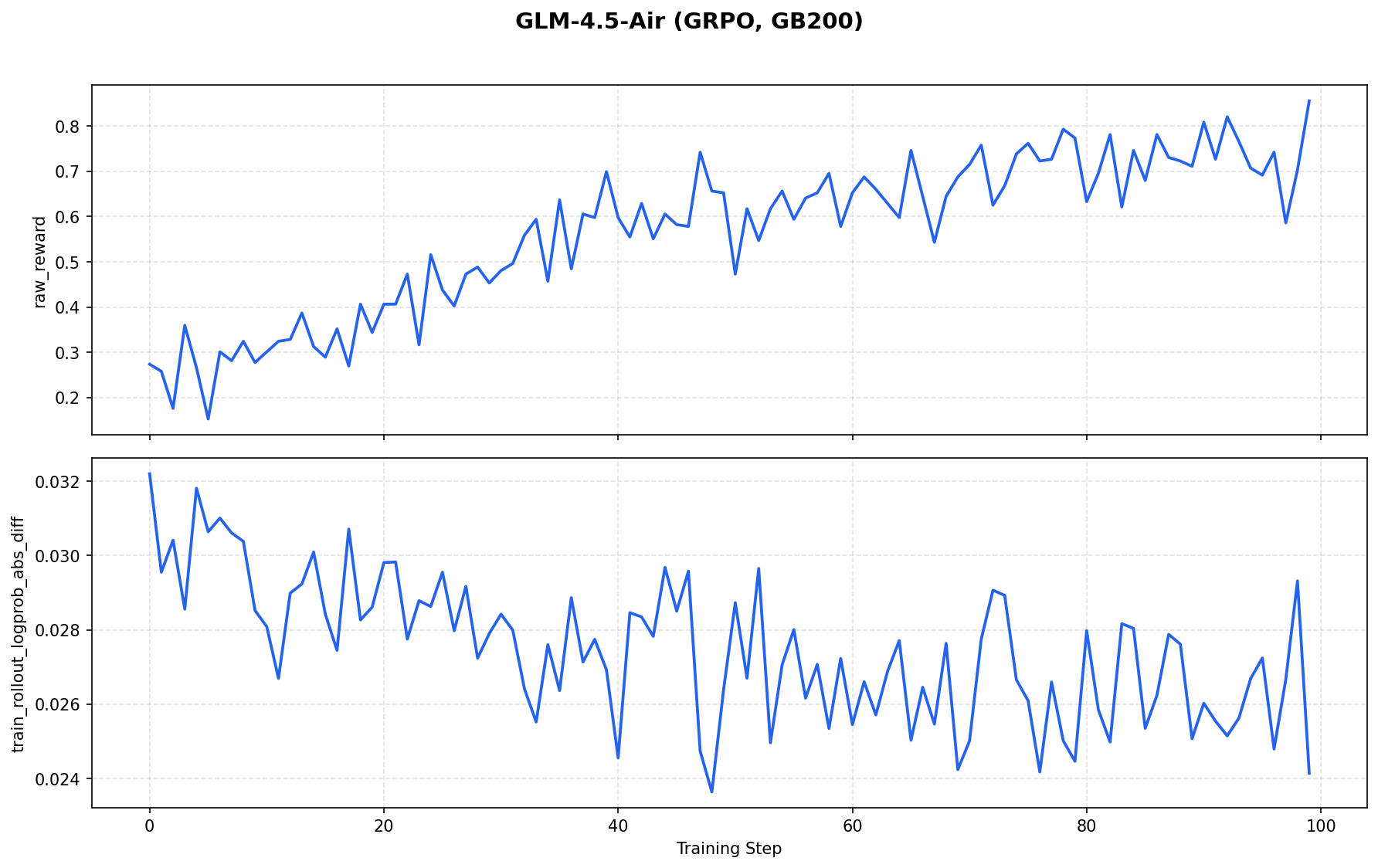
For GLM-4.5-Air on GB200 with GRPO, 8-GPU colocate, and dapo-math-17k, raw_reward trends upward over 100 steps with a mean of about 0.56. train_rollout_logprob_abs_diff stays in the 0.02-0.03 range, with a mean of about 0.028, indicating solid train-inference alignment.
Roadmap
vime is still evolving rapidly, with a roadmap focused on three areas:
- Deeper vLLM integration: Continuously adopting new vLLM capabilities such as Router, PD disaggregation, FP8, and multi-model serving.
- Multi-hardware expansion: Extending backends along vLLM's hardware plugin system so vime runs efficiently on more accelerators and cluster configurations.
- Training efficiency and algorithms: Fully asynchronous pipelines, train-inference mismatch correction, Agentic RL for multi-turn tool calling and multi-agent settings, and fast follow-up on new architectures such as MoE and VLM.
Quick Start
The getting-started path is similar to slime: configure Megatron training resources and vLLM rollout resources, prepare checkpoints and data, then launch train.py or train_async.py.
- Docs: Quick Start
- Examples: The
scripts/andexamples/directories cover scenarios such as Qwen3-4B, Qwen3-30B-A3B MoE, and GLM-4.5-Air.
Join the Community
vime is maintained by the vLLM community, open-sourced under Apache 2.0, and built on the shoulders of projects like slime, Megatron-LM, and vLLM.
- Code and docs: github.com/vllm-project/vime
- Contributing: Issues and PRs are welcome. Pre-commit keeps the code style consistent.
- Feedback: Share your experience, performance data, and feature suggestions on GitHub.
A simple architecture, stable behavior, and efficient performance: vime aims to pave the main pipeline for RL post-training for more developers. Join us and help bring this pipeline to more scenarios.
Acknowledgments
Contributors: Ao Shen, kaiyuan, princepride, Dakai An, knlnguyen1802, gcanlin, SamitHuang, and Meihan-chen.
We are grateful to the maintainers of the slime, Megatron-LM, and vLLM projects for their pioneering work. We would also like to thank Kaichao You, Roger Wang, Hongsheng Liu, and Xiyuan Wang for their support of and contributions to organizing the vime project.