Beyond One Model: Fusion in vLLM Semantic Router
Single-model serving is no longer the ceiling for production AI systems. Modern applications often have a portfolio: fast models, cheap models, private models, reasoning models, provider APIs, and local vLLM backends. The hard part is deciding when one model is enough, and when a request should become a coordinated model system.
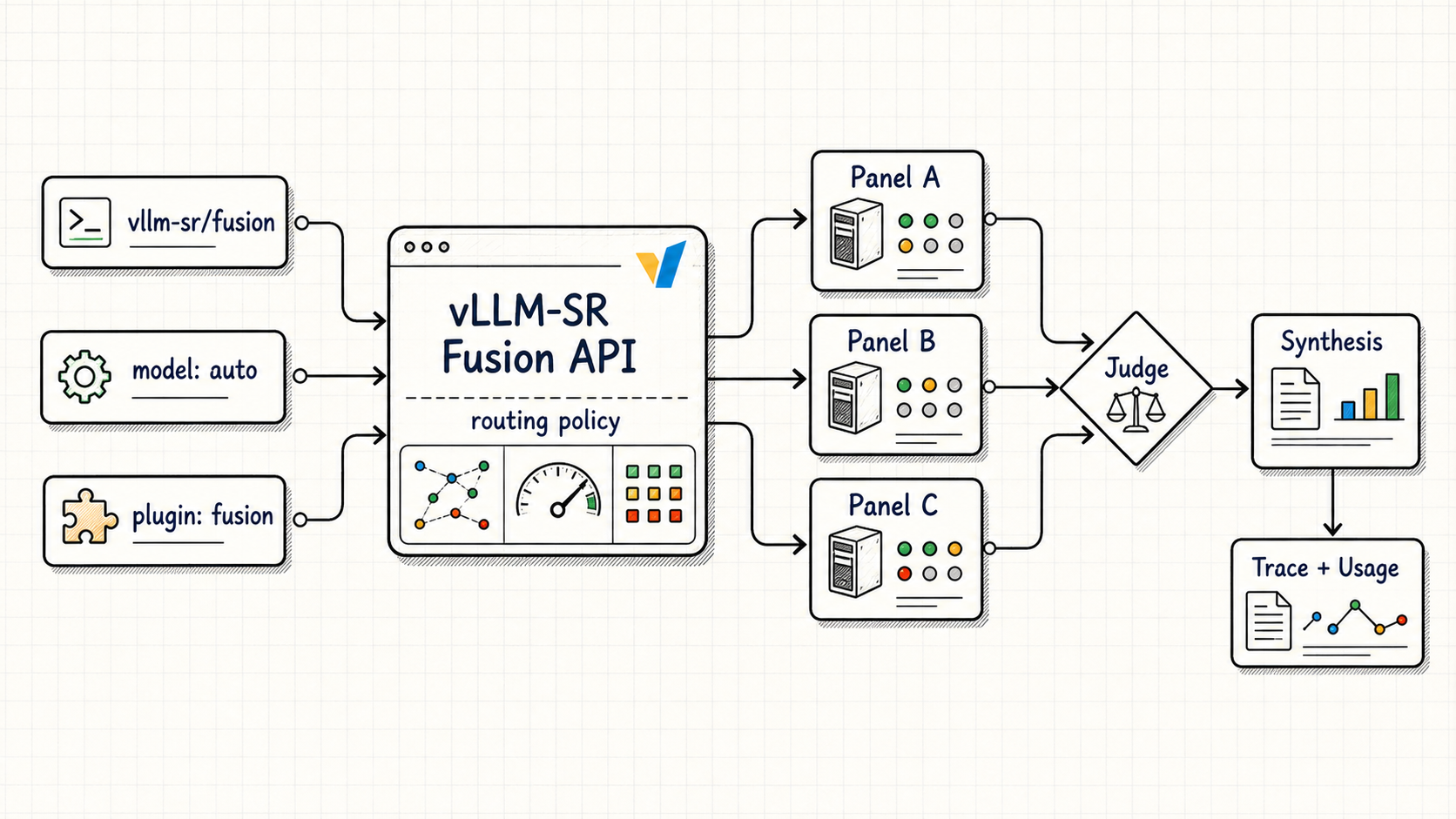
Fusion is the next vLLM Semantic Router primitive for that world. It lets a route run a panel of models, ask a judge model to analyze agreement and gaps, and synthesize one user-facing answer while keeping policy, configuration, and traces inside the router.
OpenRouter's Fusion launch is a useful signal for why this matters now: model panels are becoming a live serving pattern, not just an offline research idea. This post is not about cloning a hosted endpoint. It is about making Fusion a programmable, observable vLLM-SR primitive for Mixture-of-Models serving.
The vLLM-SR Thesis
For years, the default serving question was simple:
Which single model should serve this request?
That question is still useful, but it is no longer enough. Production systems now need policies that can:
- route simple requests to fast low-cost models
- escalate difficult requests to stronger specialists
- preserve session continuity when model switching would hurt context
- apply privacy, safety, and tenant policy before model execution
- fan out to several models when disagreement is valuable
- record the decision path so operators can debug and improve it
This is the core vLLM-SR view: model quality is not only a property of a checkpoint. It is also a property of the serving system around that checkpoint.
The Mixture-of-Models on AMD GPUs work introduced that router-centered view for vLLM-SR: capture signals, select models, coordinate heterogeneous backends, and expose the route. ReMoM extended the same direction into multi-round model collaboration. Fusion adds a more direct panel-judge-synthesis pattern for requests where multiple independent passes are worth the latency.
What Fusion Adds
Fusion is not the whole Mixture-of-Models story. It is one algorithm in the router's toolbox.
In vLLM-SR, Fusion is part of routing policy rather than a fixed global endpoint:
- Signals describe the request: domain, complexity, context, safety, feedback, or other evidence.
- Decisions choose whether this request deserves a normal route or a Fusion route.
- Fusion-only entry with
model: "vllm-sr/fusion"narrows matching to Fusion-capable decisions, so the request still gets intelligent routing without silently falling back to a single-model route. - Panel models produce independent candidate answers.
- A judge model extracts consensus, contradictions, partial coverage, unique insights, and blind spots.
- A synthesis call returns one user-facing answer.
- The trace records which models participated and what happened.
That last point is important. A hosted model slug hides most of this. vLLM-SR makes the panel, judge, policy, and trace explicit, so operators can choose where Fusion belongs instead of paying for it on every request.
Why the OpenRouter Result Is a Useful Signal
OpenRouter's launch is worth discussing because it gives a public proof point for the same systems idea. On DRACO, a deep research benchmark built around hard open-ended tasks, OpenRouter reported that fused panels outperformed individual models.
These are OpenRouter's numbers, not a vLLM-SR benchmark. We read them as external evidence that model composition deserves to be a first-class serving primitive:
| Configuration reported by OpenRouter | Score |
|---|---|
| Fusion: Fable 5 + GPT-5.5, synthesized by Opus 4.8 | 69.0% |
| Fusion: Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro, synthesized by Opus 4.8 | 68.3% |
| Fusion: Opus 4.8 + Opus 4.8, synthesized by Opus 4.8 | 65.5% |
| Solo Claude Fable 5 | 65.3% |
| Fusion: Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro, synthesized by Opus 4.8 | 64.7% |
| Solo DeepSeek V4 Pro | 60.3% |
| Solo Kimi K2.6 | 53.7% |
| Solo Gemini 3 Flash | 43.1% |
The most interesting row for vLLM-SR is the budget panel. It suggests that independent model diversity can recover quality that a single cheaper model lacks. That is exactly the kind of tradeoff a router should control.
How Fusion Works in vLLM-SR
The implementation is designed around one principle: Fusion should be a routing algorithm, not a global model setting.
The global runtime config only registers which model slugs should trigger direct Fusion execution. The actual panel, judge, error policy, templates, and runtime knobs live on the matched routing decision, because those choices are workload-specific. A research route may want three diverse providers. A code-review route may want two local specialists and one stronger synthesis model. A privacy-sensitive route may keep the whole panel on self-hosted vLLM backends.
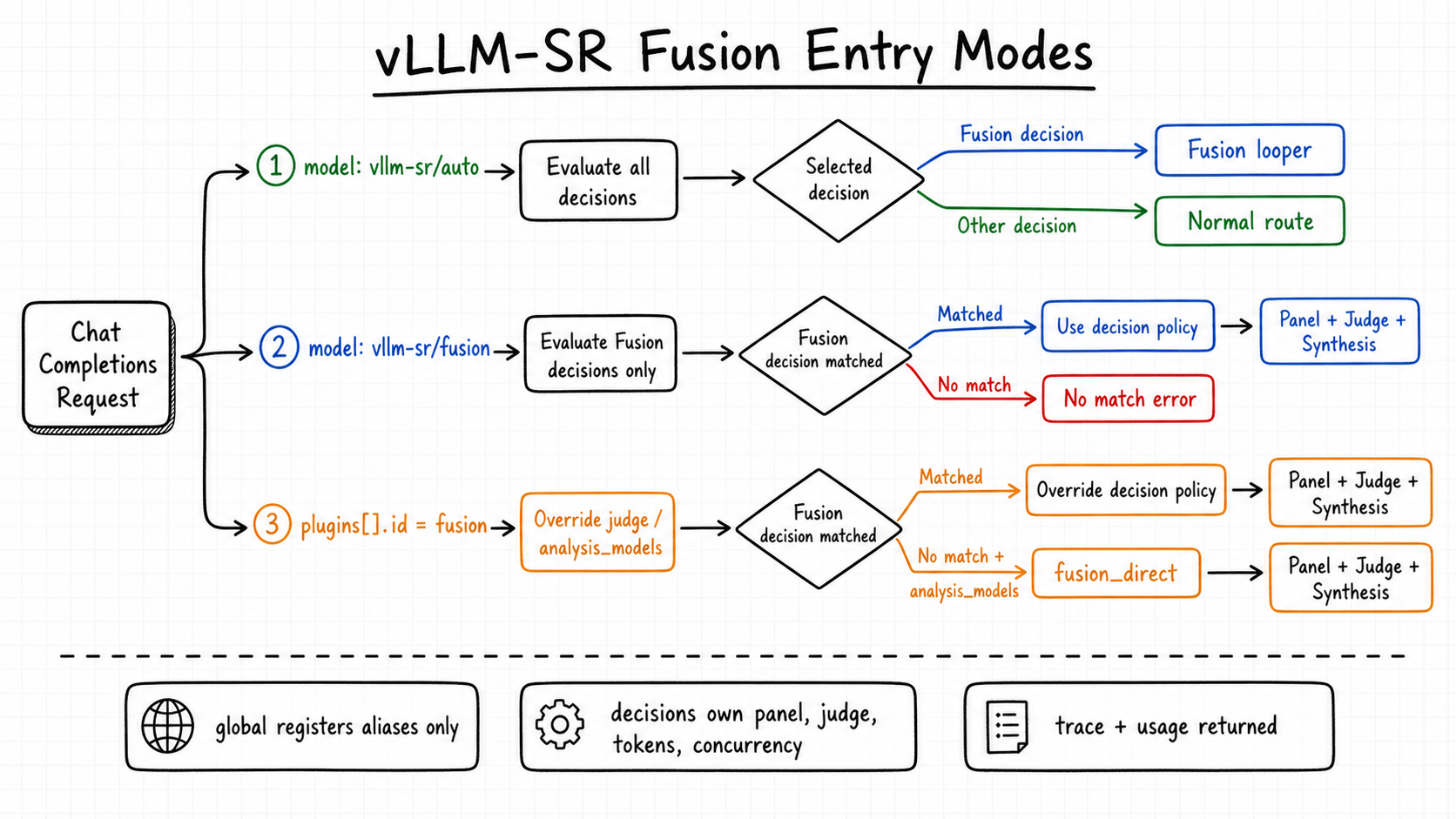
vLLM-SR supports three ways to enter the same algorithm:
| Entry path | How vLLM-SR handles it |
|---|---|
model: "vllm-sr/auto" | Runs full vLLM-SR signal and decision policy. Fusion executes only if the selected decision uses algorithm.type: fusion; otherwise the matched non-Fusion route runs normally. Legacy aliases such as auto and MoM remain supported. |
model: "vllm-sr/fusion" | Runs the same signal extraction, but limits decision matching to Fusion-capable decisions. If no Fusion decision matches, vLLM-SR returns a clear no-match error unless the request provides a panel override. |
plugins: [{ "id": "fusion", ... }] | Overrides judge, panel, and selected runtime knobs for one request. If no Fusion decision matches and analysis_models is provided, vLLM-SR builds a request-scoped fusion_direct execution. |
Once a request reaches the Fusion looper, execution is explicit and observable:
- Resolve policy. vLLM-SR merges decision-level Fusion config, decision model refs, and request-level plugin overrides.
- Protect the router. Registered Fusion slugs cannot be used as judge or panel models, so a Fusion request cannot recursively call Fusion.
- Run the panel. Analysis models execute concurrently, bounded by
max_concurrent. - Handle failures by policy.
on_error: skipallows partial panels;on_error: failmakes provider failure visible immediately. - Analyze disagreement. The judge model produces structured analysis over consensus, contradictions, partial coverage, unique insights, and blind spots.
- Synthesize or call a tool. The final judge/synthesis call returns one assistant response, or an OpenAI-compatible
tool_callsresponse when the client supplied tools. - Return trace and accounting. The response can include Fusion trace data, intermediate panel outputs, failed model records, and aggregated token usage across panel, judge, and synthesis calls.
That last item is part of the router value. A caller receives an OpenAI-compatible response, while the operator still gets the system-level view: which decision fired, which models participated, how many iterations ran, what failed, and how much token usage the whole multi-model execution consumed.
This release focuses on the serving primitive: policy-controlled panels, explicit stage contracts, provider interoperability, and traceable execution. The quality question deserves its own larger public eval comparing Fusion, single-model baselines, and frontier panels across shared tasks.
Fusion Is a Decision, Not a Default
Fusion is useful because some requests benefit from independent model perspectives. It is expensive because it adds panel calls, judge analysis, synthesis, and usually more latency. The production question is not only "can we fuse models?" It is "when is Fusion worth it?"
That is where vLLM-SR matters. model: "vllm-sr/auto" lets the router decide whether a request should use Fusion at all. Simple prompts can stay on a fast single-model route. Hard research, ambiguous analysis, high-stakes synthesis, or tasks where disagreement is valuable can match a Fusion decision. The same signal-decision layer can also encode domain, tenant, privacy, cost, session, or safety policy before the router pays the latency cost.
model: "vllm-sr/fusion" is the explicit path for clients that want Fusion-only routing. It still uses vLLM-SR signals and decisions, but narrows matching to Fusion-capable decisions so it does not silently fall back to an ordinary single-model route. Request-level Fusion plugins are the override path for clients that need to supply a panel for one call.
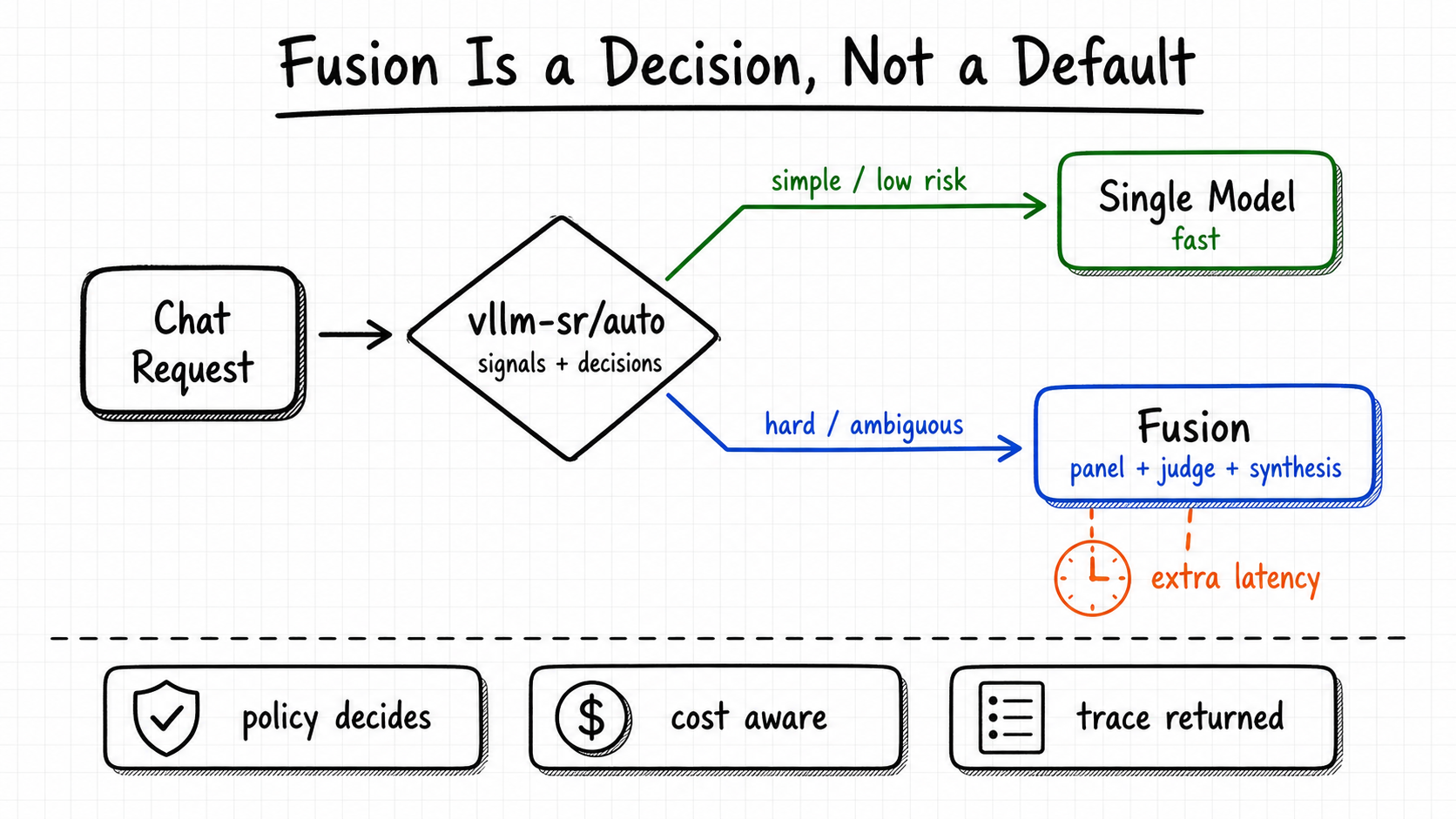
That gives operators a more useful control plane than a single hosted Fusion slug:
| Production question | vLLM-SR control |
|---|---|
| Should this request use Fusion? | vllm-sr/auto with signals and decisions |
| Which Fusion policy should apply? | Fusion-capable decisions with priorities and rules |
| Which models should participate? | Per-decision judge and panel config |
| How should latency and failures be handled? | max_concurrent, on_error, and optional token policy |
| Where can models run? | Local vLLM backends, private endpoints, and public providers |
| How do operators debug the route? | Decision metadata, Fusion trace, failures, and aggregated usage |
After the Decision: Traceable Fusion
Once a request reaches a Fusion decision, vLLM-SR runs a small multi-model workflow with explicit stage boundaries. The panel stage returns independent candidate answers. The judge stage turns those candidates into structured analysis. The final stage consumes that analysis to produce one assistant answer, or a tool call when the client provided tools.
The stage contract keeps the system inspectable. If a panel model fails, on_error: skip can continue with partial evidence while recording the failed model, or on_error: fail can stop immediately. If the structured judge output cannot be parsed, vLLM-SR preserves the raw analysis and marks the parse failure instead of hiding it. The final response can include the Fusion trace, intermediate panel outputs, failed-model records, and total token usage across the whole run.
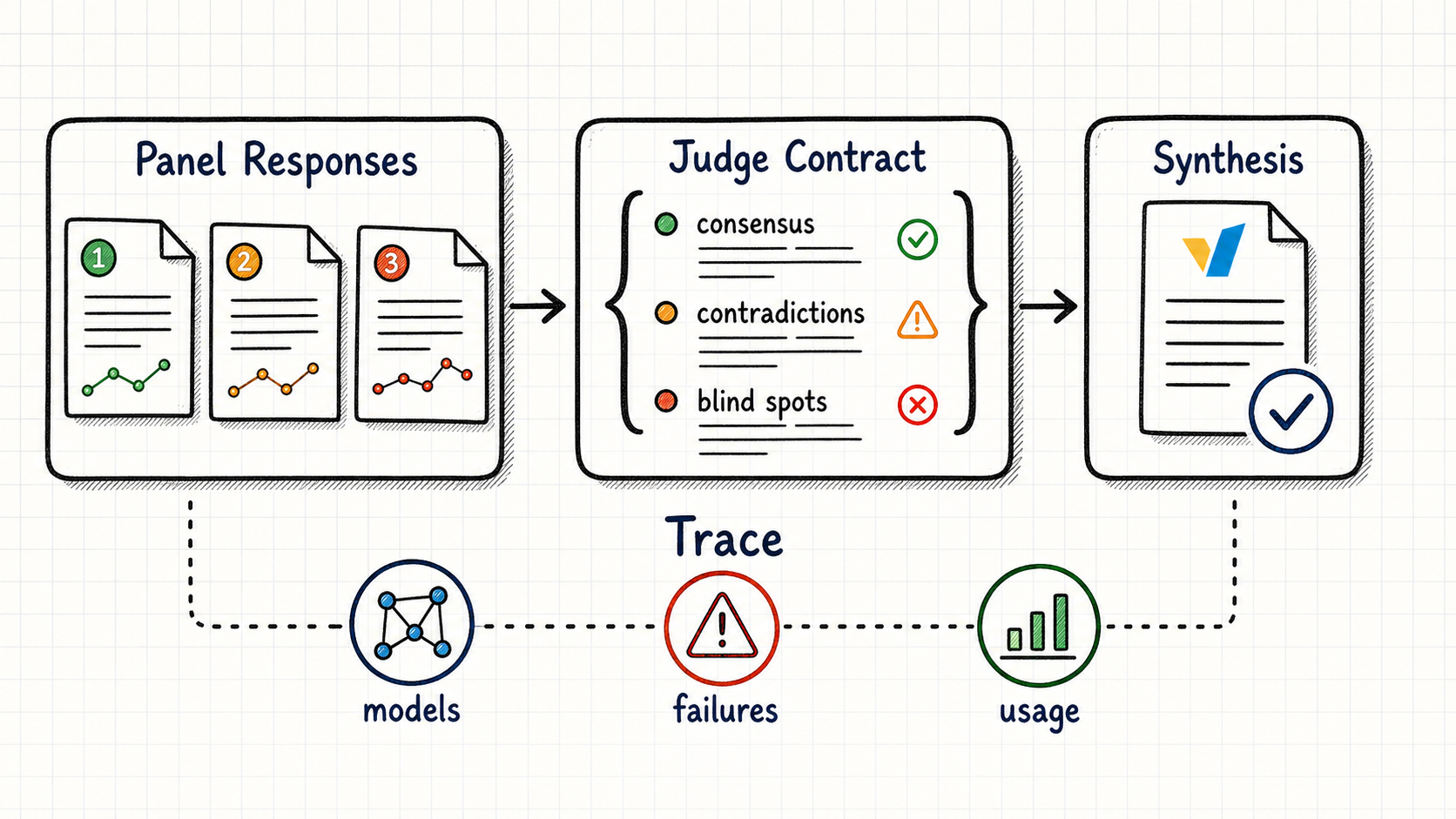
This is how Fusion becomes more than a feature. It becomes one implementation of a programmable Mixture-of-Models control plane.
Try It with vLLM-SR
Let the Router Decide
Use vllm-sr/auto when you want the router to choose among all configured decisions:
{
"model": "vllm-sr/auto",
"messages": [
{
"role": "user",
"content": "What are the strongest arguments for and against carbon taxes?"
}
]
}If the matched decision uses algorithm.type: fusion, the request enters Fusion. If the matched decision is a normal route, vLLM-SR uses the normal selected model path.
Request Fusion Explicitly
Use vllm-sr/fusion when the client explicitly wants Fusion-only routing. This still runs signal extraction, but only Fusion-capable decisions are eligible:
{
"model": "vllm-sr/fusion",
"messages": [
{
"role": "user",
"content": "What are the strongest arguments for and against carbon taxes?"
}
]
}Override the Panel for One Request
The request can also customize the panel. This override is request-scoped; it does not move judge or panel defaults into global config:
{
"model": "vllm-sr/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}Use Fusion in Agent Loops
For agentic applications, keep using the same OpenAI-compatible tool loop. Fusion gives tool-call authority only to the final judge. Panel models and the structured judge-analysis call run text-only: they see the conversation history, including prior tool results, but they do not receive tools or tool_choice.
{
"model": "vllm-sr/fusion",
"messages": [
{
"role": "user",
"content": "Find the latest benchmark result and explain whether it changes our launch plan."
}
],
"tools": [{
"type": "function",
"function": {
"name": "web_search",
"parameters": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
}],
"tool_choice": "auto"
}In that request, the panel produces independent text analysis, the judge compares the panel, and only the final judge can answer directly or return standard OpenAI-compatible tool_calls. Non-streaming clients receive the regular Chat Completions JSON shape; streaming clients receive tool-call SSE chunks with finish_reason: "tool_calls". Tool results appended by the client are preserved in the next Fusion turn, so multi-round agent loops continue to work.
Configure Entrypoints and Decisions
The global config registers API entry aliases only:
global:
router:
auto_model_names:
- vllm-sr/auto
- auto
- MoMFusion slugs are registered under the looper integration:
global:
integrations:
looper:
fusion:
model_names:
- vllm-sr/fusionThe per-decision config owns the route semantics, judge, panel, and runtime knobs:
routing:
decisions:
- name: deep-research-fusion
description: Use model diversity for research prompts with high synthesis risk.
rules:
operator: AND
conditions:
- type: domain
name: research
- type: complexity
name: needs_reasoning:hard
algorithm:
type: fusion
fusion:
model: google/gemini-3-flash-preview
analysis_models:
- google/gemini-3-flash-preview
- moonshotai/kimi-k2.6
- deepseek/deepseek-v4-pro
max_concurrent: 3
on_error: skipThat separation is deliberate. global is route-independent runtime state. The judge, panel, optional token budget, concurrency, and route semantics belong to the decision.
Operators can opt in to the OpenRouter-style alias when they want compatibility with existing clients:
global:
integrations:
looper:
fusion:
model_names:
- vllm-sr/fusion
- openrouter/fusionBy default, vLLM-SR registers only vllm-sr/fusion.
What Comes Next
OpenRouter's DRACO result is a strong signal that model panels deserve serious evaluation. Our next step is to make that kind of evaluation reproducible for vLLM-SR and Mixture-of-Models systems:
- run larger public evals beyond smoke coverage
- compare Fusion, ReMoM, AutoMix, Router-R1, and single-model baselines
- study budget panels against frontier-model panels
- expose trace-level diagnostics for disagreement, missing coverage, and judge behavior
- let routing policy decide when the extra latency is justified
The direction is clear. The best answer will not always come from the largest model. Increasingly, it will come from the best model system, and vLLM-SR is where that system should be programmable.