Model Runner V2: A Modular and Faster Core for vLLM
We are excited to announce Model Runner V2 (MRV2), a ground-up re-implementation of the vLLM model runner. MRV2 delivers a cleaner, more modular, and more efficient execution core—with no API changes. The goal is simple: better code and better performance.
Like the vLLM V1 release last year, this is an architectural upgrade driven by hard-earned lessons from vLLM's large user base and feedback from the community. We revisited persistent batching, async scheduling, input preparation, and sampling, then rebuilt the model runner around three core principles:
- Be modular. Isolate model-specific logic from the common execution path.
- Be GPU-native. Move bookkeeping off the CPU and onto the GPU.
- Be async-first. Treat overlapped CPU/GPU execution as a design constraint, not a retrofit.
MRV2 is not yet feature-complete, but you can try it today:
export VLLM_USE_V2_MODEL_RUNNER=1We plan to make MRV2 the default in the near future.
Why Model Runner V2?
Since vLLM V1 shipped last year, the model runner has accumulated significant technical debt as features and optimizations were added incrementally. Many of those changes were useful in isolation, but the implementation grew harder to reason about over time—especially once async scheduling and speculative decoding became central to the execution model.
In practice, this led to several recurring issues:
- Tangled persistent batch state. Persistent state was tightly coupled to per-step model inputs, making request insertions, removals, and reordering more complex than necessary.
- Fragile async execution. Async scheduling was retrofitted onto the V1 runner, so many features required unnatural and unreasonably complex logic to coexist with it.
- CPU-bound bookkeeping. Input preparation and sampling relied on many small CPU-side operations, leaving performance on the table as GPUs kept getting faster.
- Difficult extensibility. The runner as a whole became harder to understand and extend cleanly as new models and features arrived.
MRV2 addresses these issues by rethinking the model runner with cleaner state ownership and more explicit abstractions.
What's New in Model Runner V2?
1. A Better Persistent Batch Design and GPU-Native Input Preparation
vLLM performs substantial bookkeeping for batching, paged attention, sampling parameters, and more. Historically, much of this work was implemented as many small CPU-side operations.
To reduce that overhead, vLLM V1 introduced persistent batching: because consecutive batches are usually similar, it is much cheaper to update cached state incrementally than to rebuild large tensors from scratch every step. However, the V1 design used persistent state directly as model and sampler inputs, which created awkward layout constraints and complicated bookkeeping.
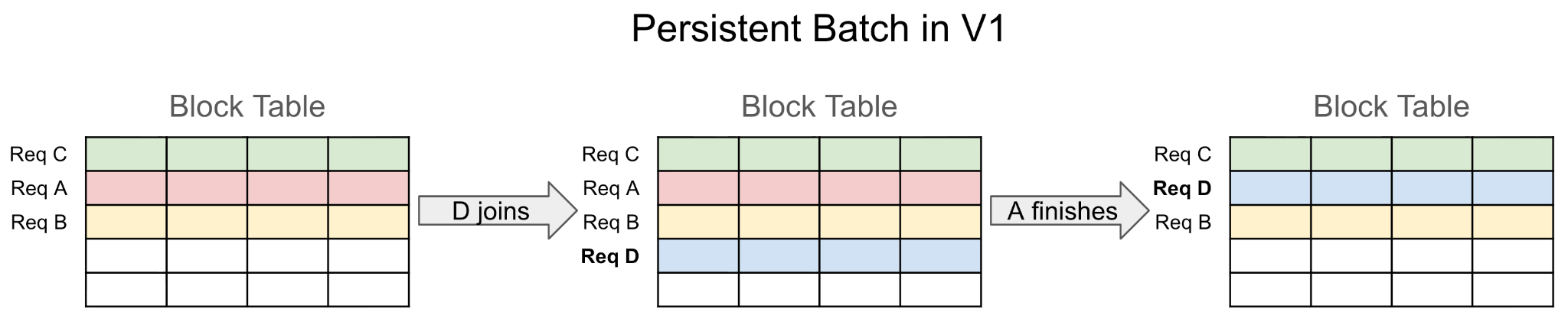
MRV2 decouples persistent request state from per-step input tensors. Each live request gets a stable row in a fixed-size state table for its active lifetime. At each step, the runner gathers the step-specific inputs from that persistent state according to the current request ordering. This preserves the performance benefit of incremental updates while removing a large amount of state-management complexity. It also eliminates redundant backup state such as CachedRequestState, since active requests no longer depend on fragile tensor-wide reordering.
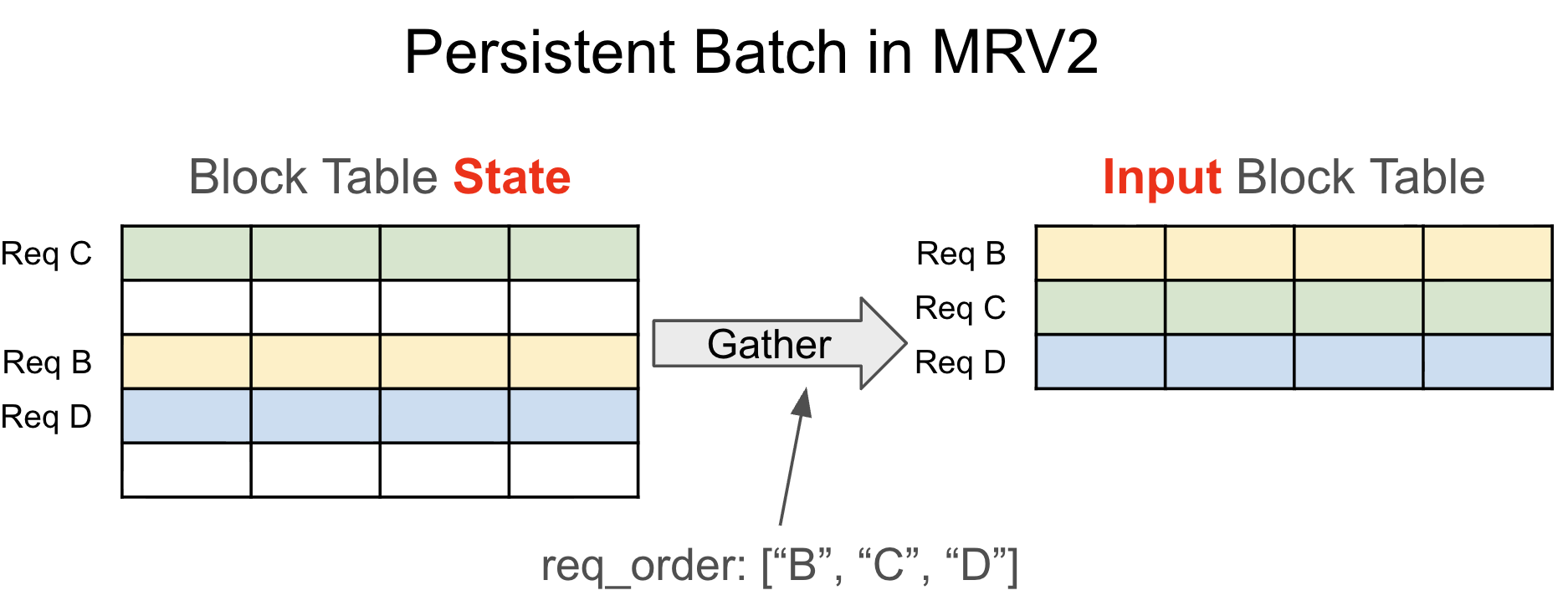
MRV2 also moves input preparation to the GPU using Triton kernels. Request state is largely kept on the device, and tensors such as input_ids, positions, query_start_loc, and seq_lens are now built directly on the GPU. This provides three concrete benefits:
- Lower CPU overhead by avoiding a large amount of Python and CPU tensor manipulation.
- Lower code complexity by removing the constraints imposed by CPU-side tensor operations.
- Better async and speculative decoding compatibility, since GPU-resident preparation can directly consume device-side results without synchronization (see next section).
2. Async-First Design
Async scheduling is now fundamental to vLLM. The scheduler and worker prepare step N+1 while the GPU executes step N, overlapping host work and device work to maximize utilization. While this was already supported in vLLM V1, it was largely a retrofit rather than a first-class design constraint.
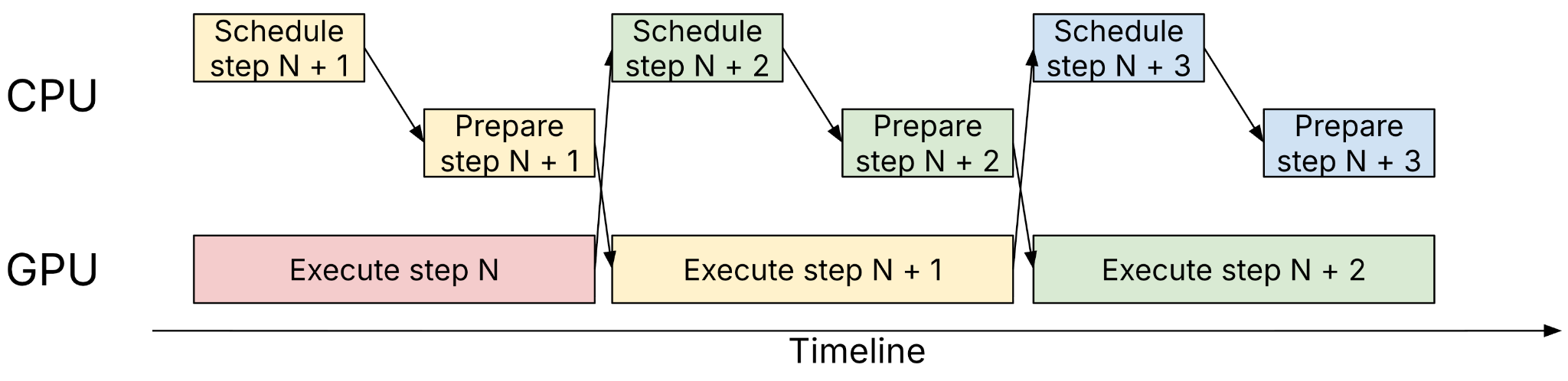
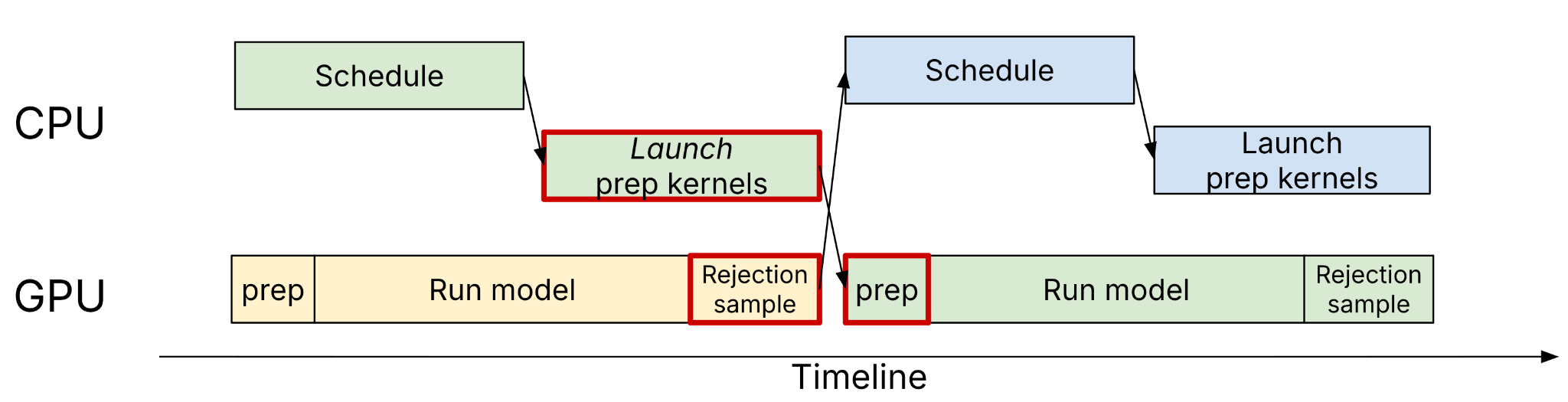
MRV2 treats async execution as a core assumption and aims for zero synchronization between CPU and GPU across all supported model and feature combinations.
Importantly, MRV2 naturally enables async scheduling and speculative decoding together—a combination that was difficult to support cleanly in V1. Because MRV2's input preparation runs on the device, the preparation kernels can directly consume rejection sampling results produced by the GPU. Outputs from each step are transferred asynchronously to the CPU in a separate CUDA stream, fully decoupled from the main computation stream. The same design extends to speculative decoding with structured outputs as well.
3. A Triton-Native Sampler
MRV2 reworks sampling with optimized Triton kernels for better control over memory usage and numerics. Specific improvements include:
- Gumbel-Max sampling kernel that avoids explicit softmax materialization and uses stateless in-kernel RNG.
- More efficient top-k logprobs by finding top-k logits first and computing logprobs only for the selected candidates.
- More memory-efficient prompt logprobs through finer-grained chunking, including chunking within a single prompt.
- Better speculative decoding compatibility by using indirection (
idx_mapping) inside kernels rather than expanding request state to match every logits vector.
Together, these changes reduce peak memory usage and make it easier to support rich combinations of sampling parameters.
4. Stronger Modularization
vLLM needs to support a wide range of model architectures, and the existing model runner accumulated considerable complexity as a result. MRV2 addresses this with a new abstraction: ModelState.
class ModelState(ABC):
def add_request(self, ...):
def remove_request(self, ...):
def get_mm_embeddings(self, ...):
def prepare_inputs(self, ...):
def prepare_attn(self, ...):
def prepare_dummy_inputs(self, ...):
...ModelState defines the interface for model-specific logic—multimodal embeddings, extra model inputs, attention metadata, CUDA graph capture—so the main runner can stay focused on the common path. This directly addresses a common complaint from both users and contributors: vLLM supports so many models that the shared code can feel convoluted, especially for developers who only care about one model family such as DeepSeek, Qwen, Kimi, or a private internal model.
In addition, MRV2 breaks the runner into smaller files with clearer responsibilities. The existing runner (gpu_model_runner.py) had grown into a single file exceeding 6,700 lines; the largest file in MRV2 is now under 1,300 lines.
Performance
MRV2 is not just a cleanup project. It already delivers measurable wins.
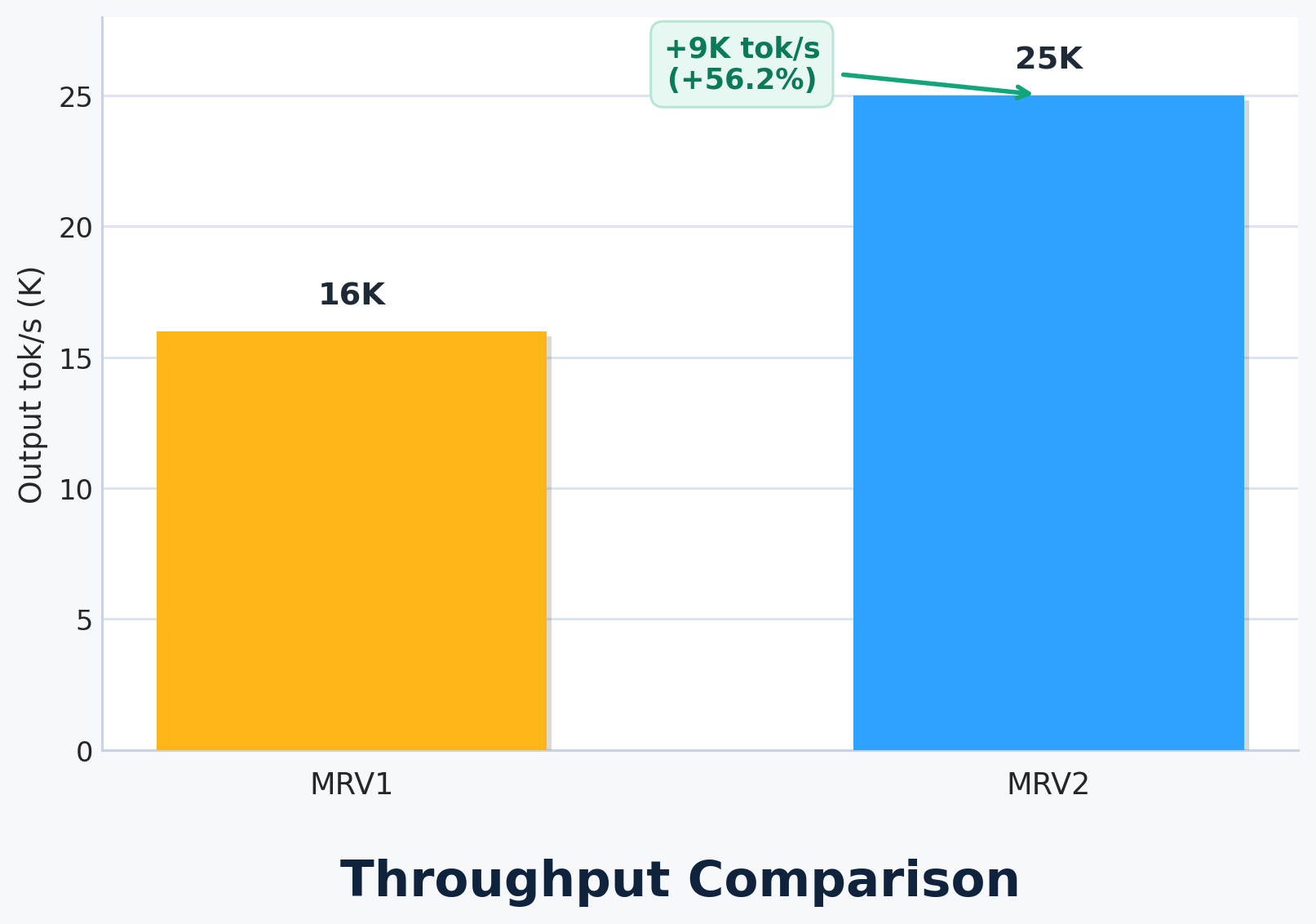
We stress-tested MRV2 by running a very small model (Qwen3-0.6B) on a powerful GPU (1×GB200), intentionally choosing a small model so that host-side overhead would be proportionally large. In this setup, MRV2 delivered a 56% throughput increase by offloading input preparation to GPU.
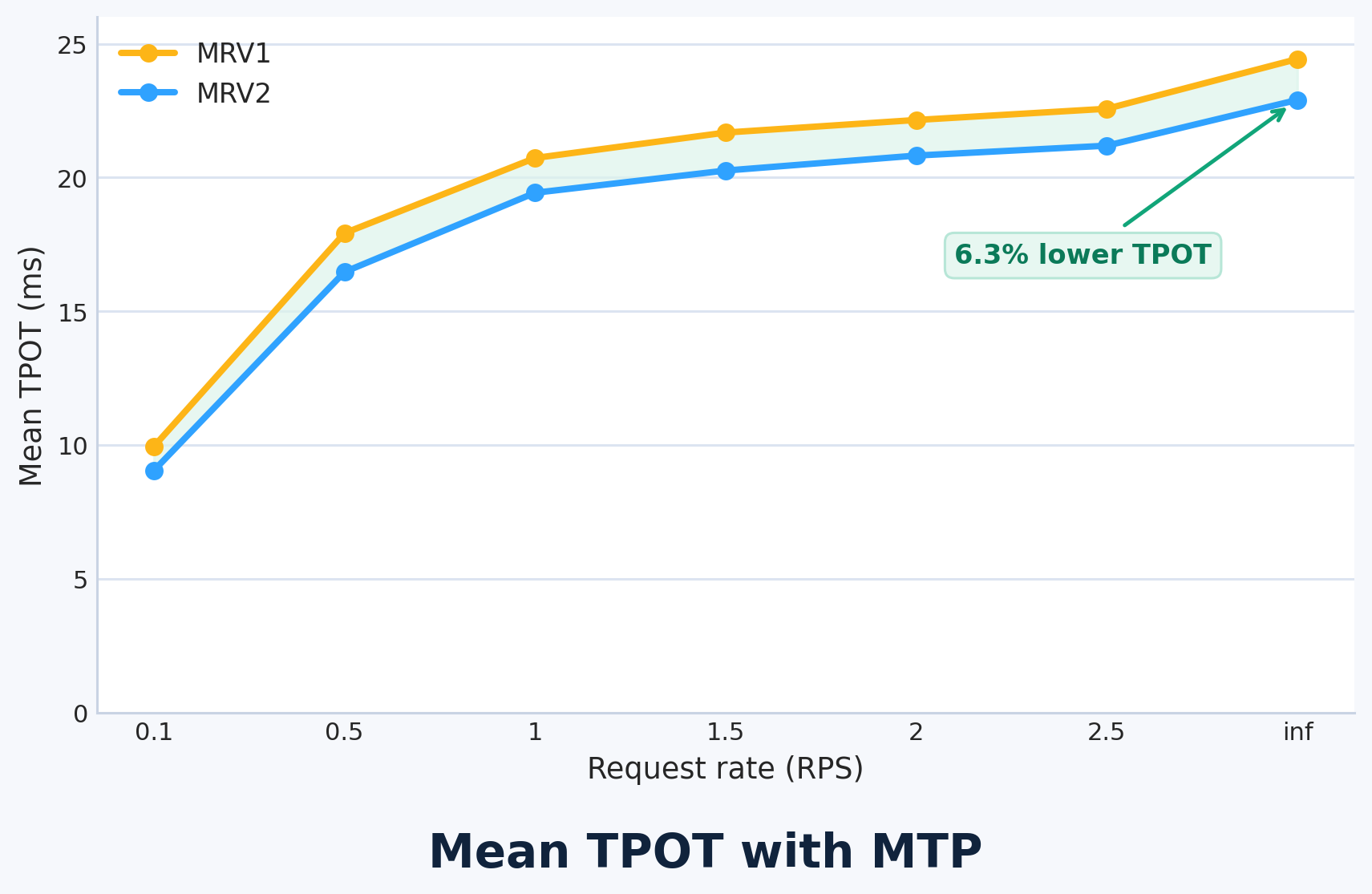
We also measured gains for speculative decoding: 6.3% lower TPOT on 4×GB200 with GLM-4.7-FP8 and MTP=1. The improvement comes from MRV2's zero-synchronization design, which completely eliminates CPU–GPU sync points when speculative decoding is enabled.
We expect this architectural foundation to matter even more as serving stacks continue to combine async scheduling, speculative decoding, multimodal preprocessing, and increasingly heterogeneous model state.
Limitations and Current Status
MRV2 is still experimental and under active development. The design is significantly cleaner and early results are strong, but MRV2 is not yet feature-complete. As of v0.18.0, the following features are not supported:
- Linear attention models (Qwen3.5, Nemotron 3 Super)
- Spec decoding methods other than Eagle/Eagle3/MTP
- EPLB and DBO
- Logits processors
- LoRA
For a full list, refer to the second page of the design doc.
We are holding MRV2 to a higher quality bar: when a V1 feature is brought into MRV2, we want to reconsider it from first principles rather than copy over complexity mechanically. For this reason, it may take longer than usual to land changes that touch MRV2.
Getting Started
- Install the latest vLLM build.
- Set
export VLLM_USE_V2_MODEL_RUNNER=1. - Use the existing vLLM APIs as usual—Python API or
vllm serve.
There are no user-facing API changes required.
Acknowledgments
Woosuk Kwon, Nick Hill, Giancarlo Delfin, Santino Ramos (Inferact), Wentao Ye, Zhanqiu Hu, Lucas Wilkinson (Red Hat), Haoran Zhu (Alibaba)