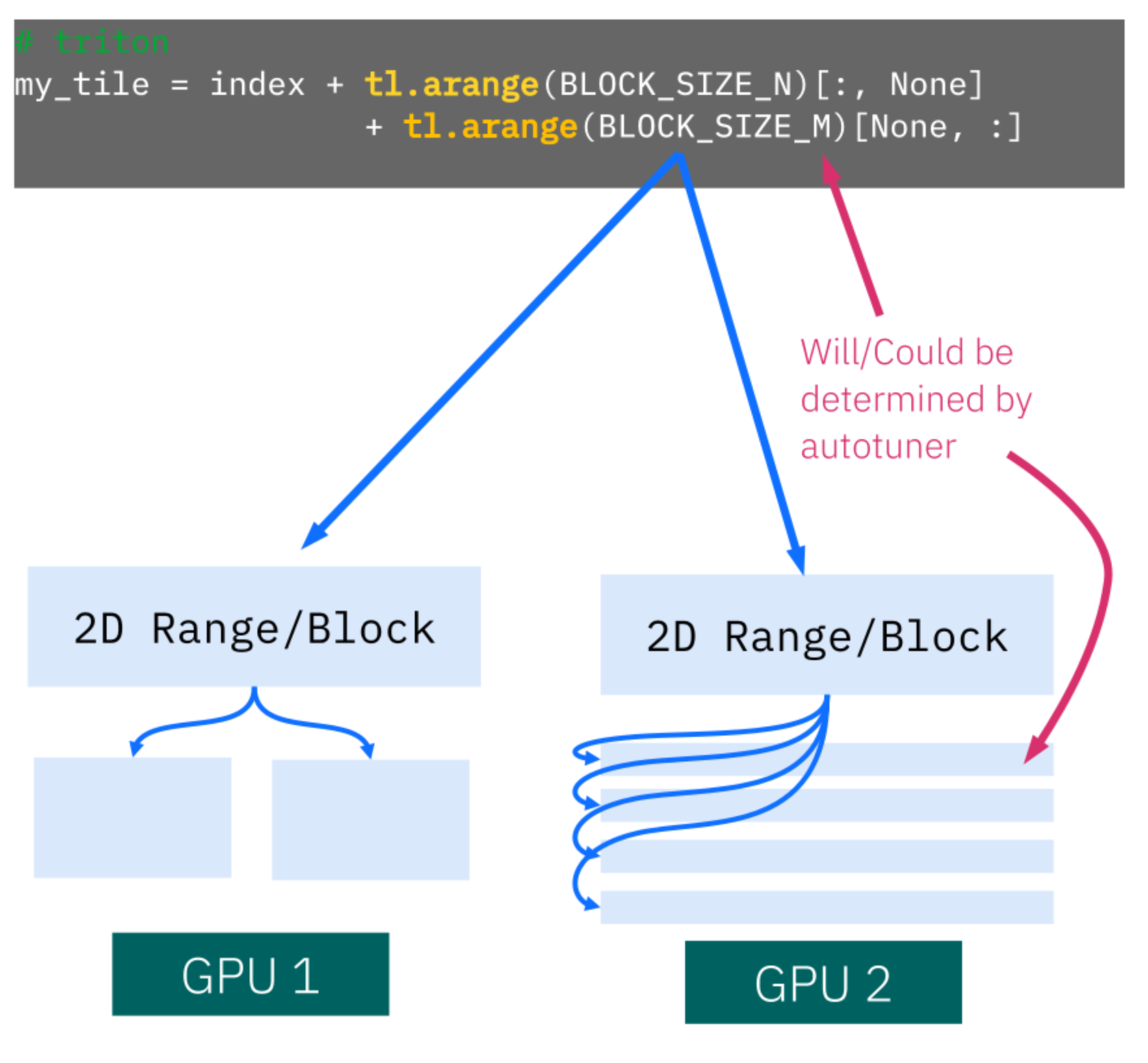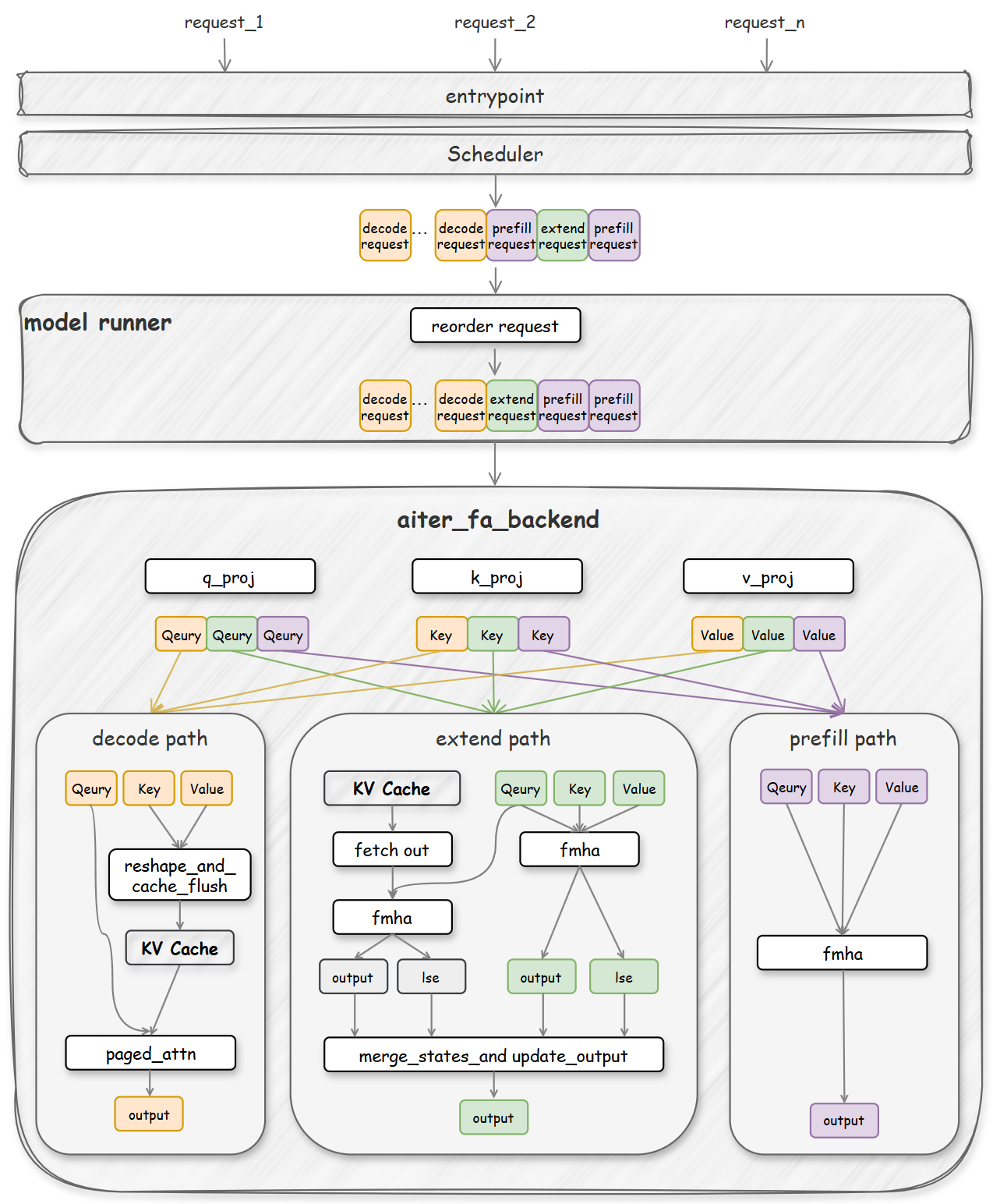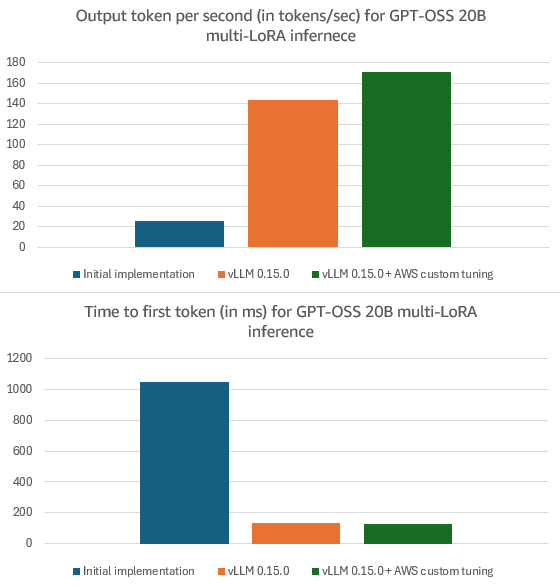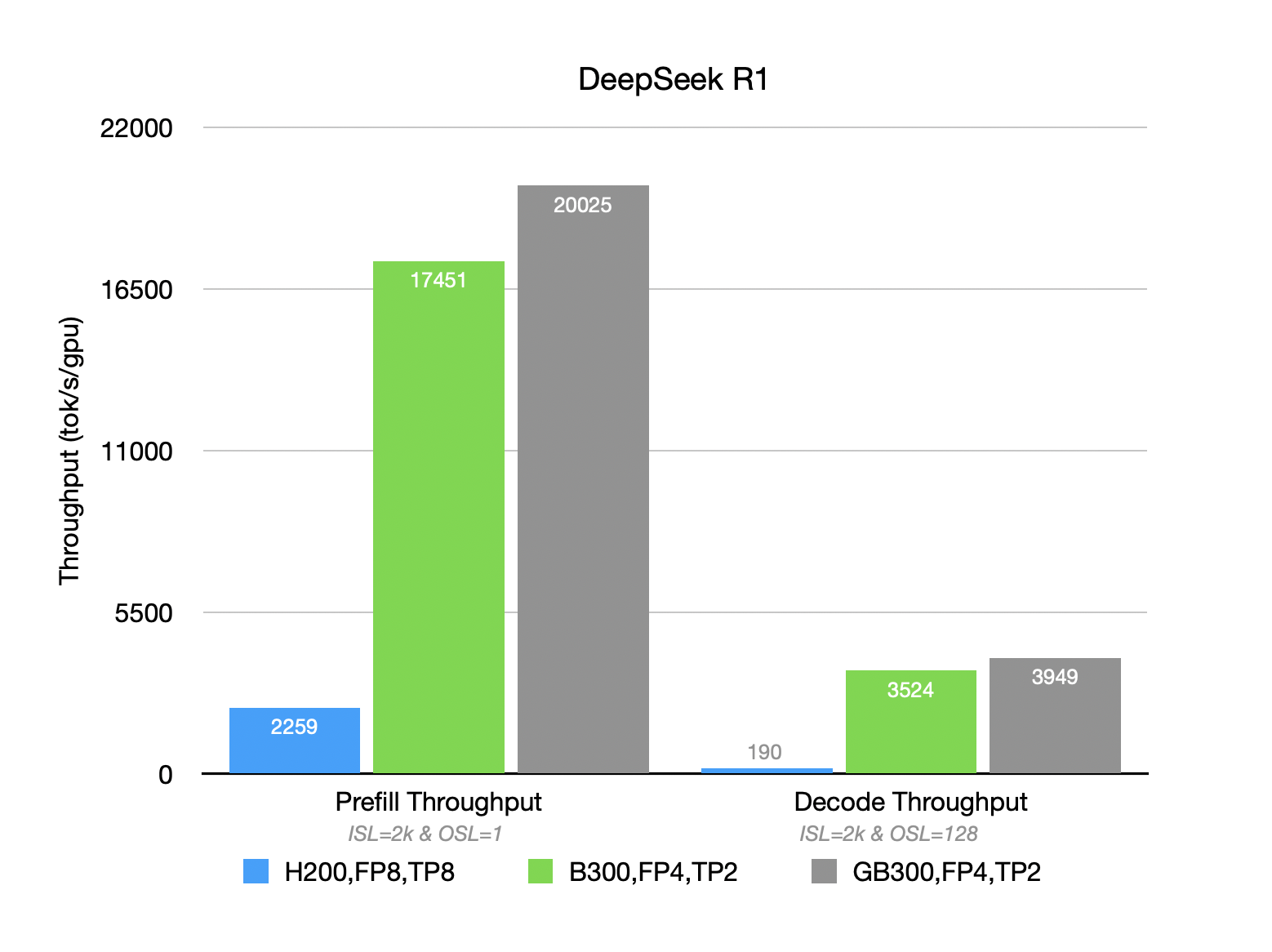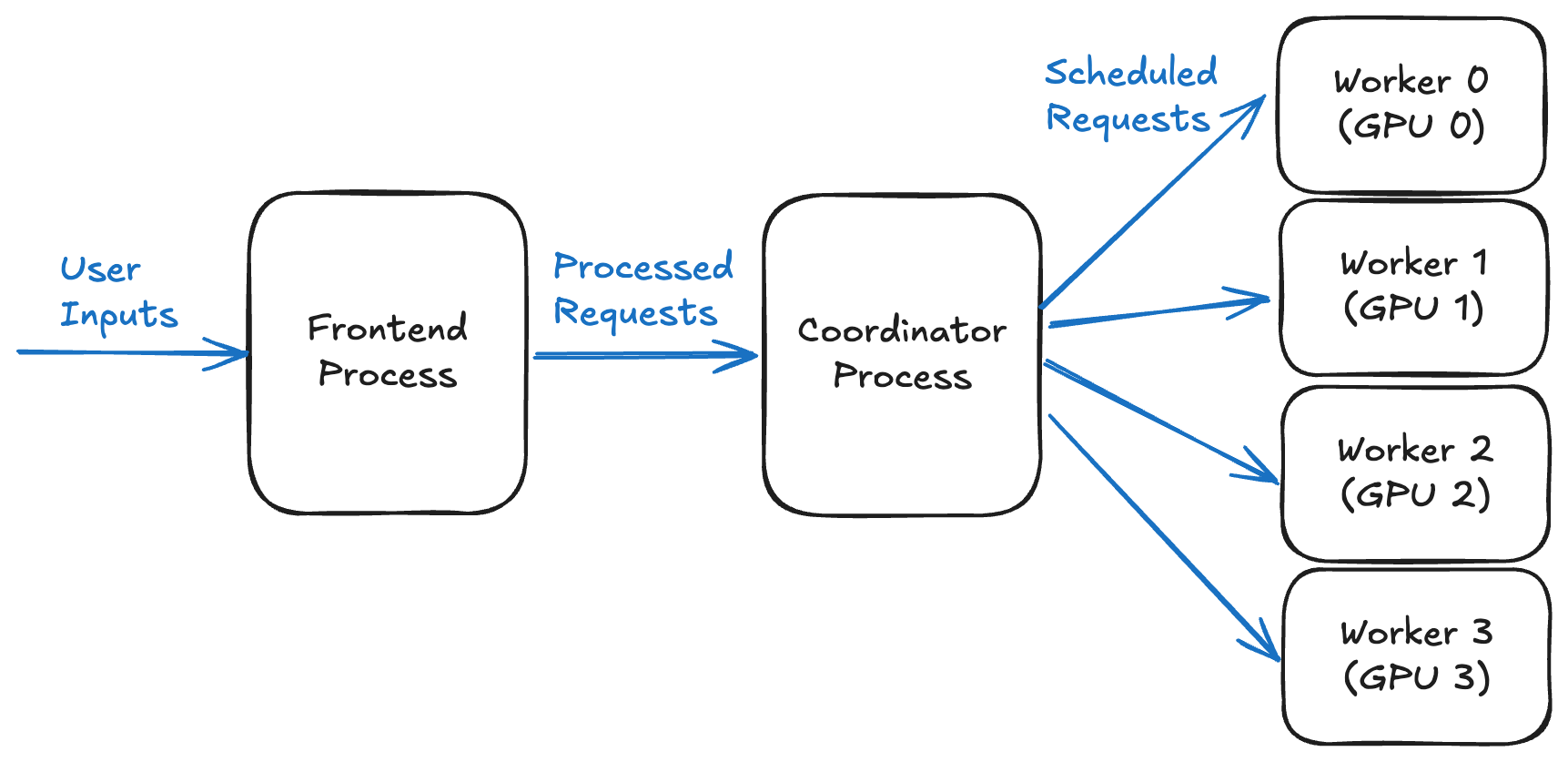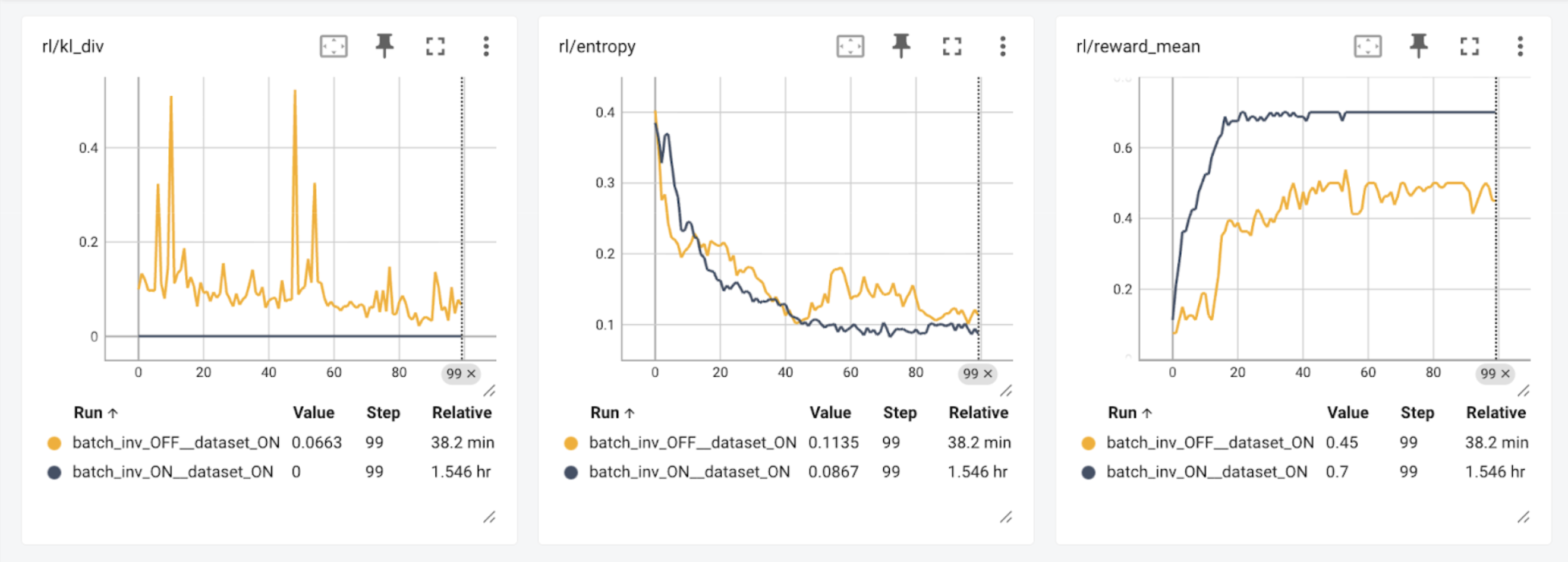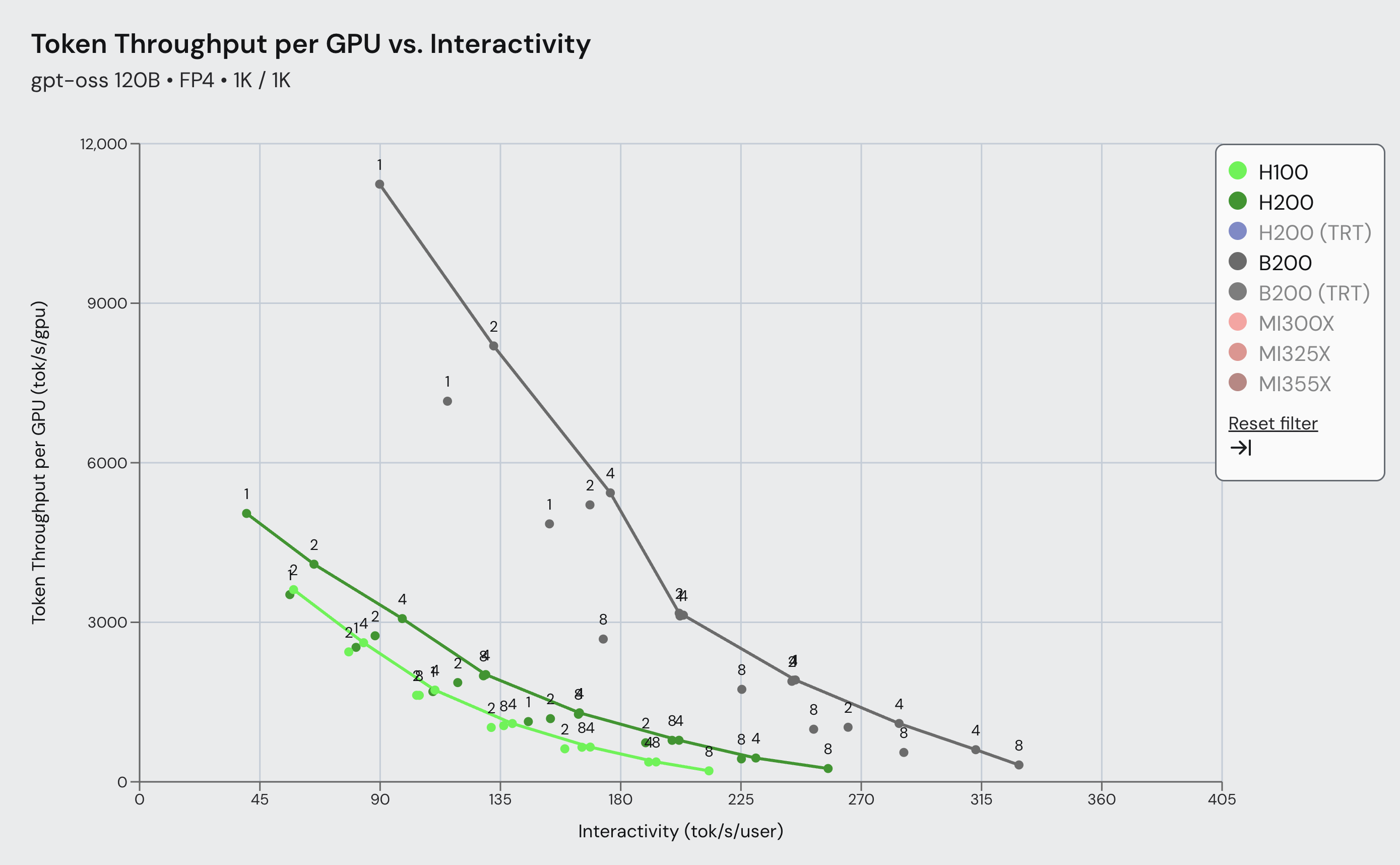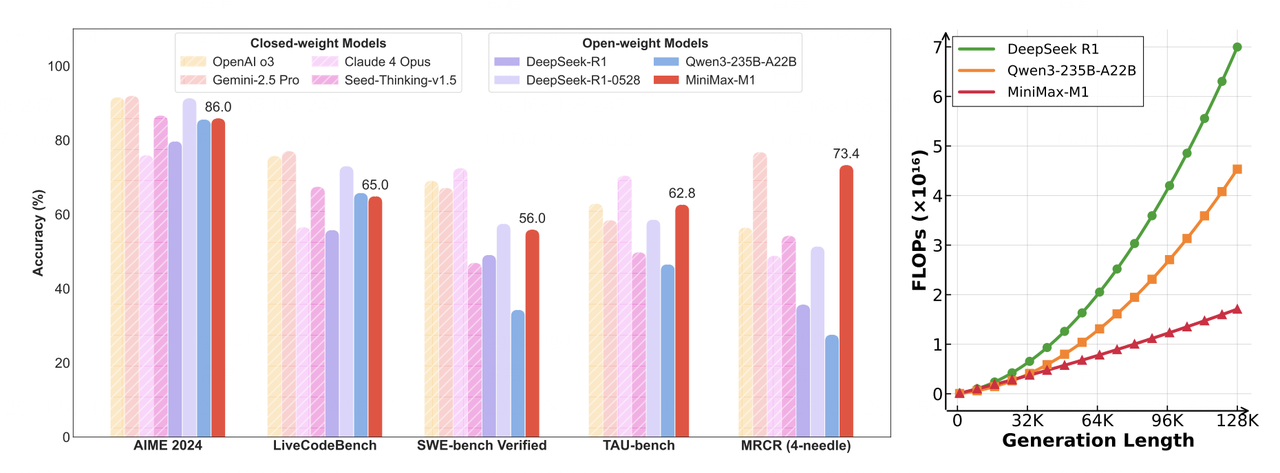
A Preview of Production-Scale Kimi K3 Support on vLLM
·13 min read
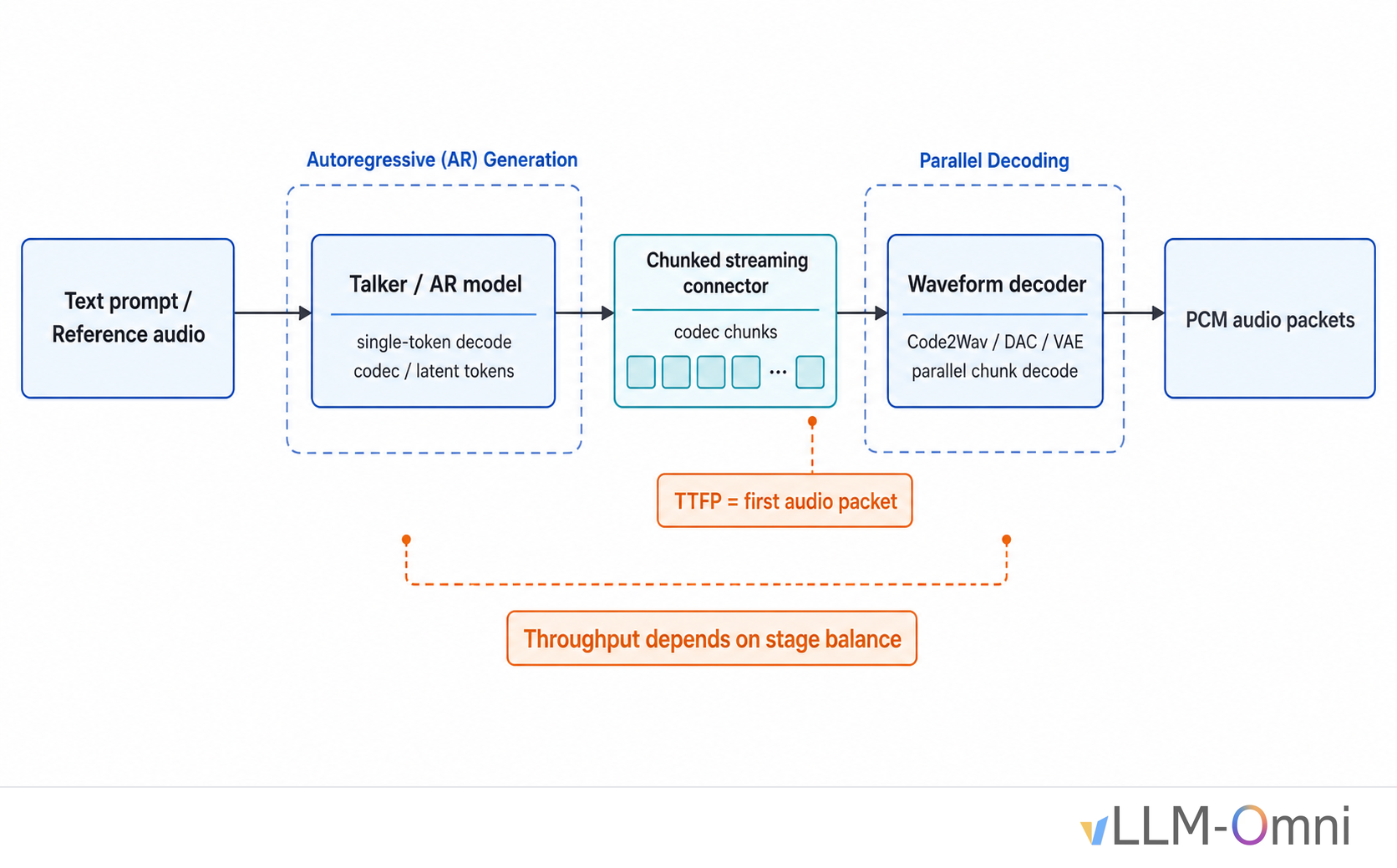
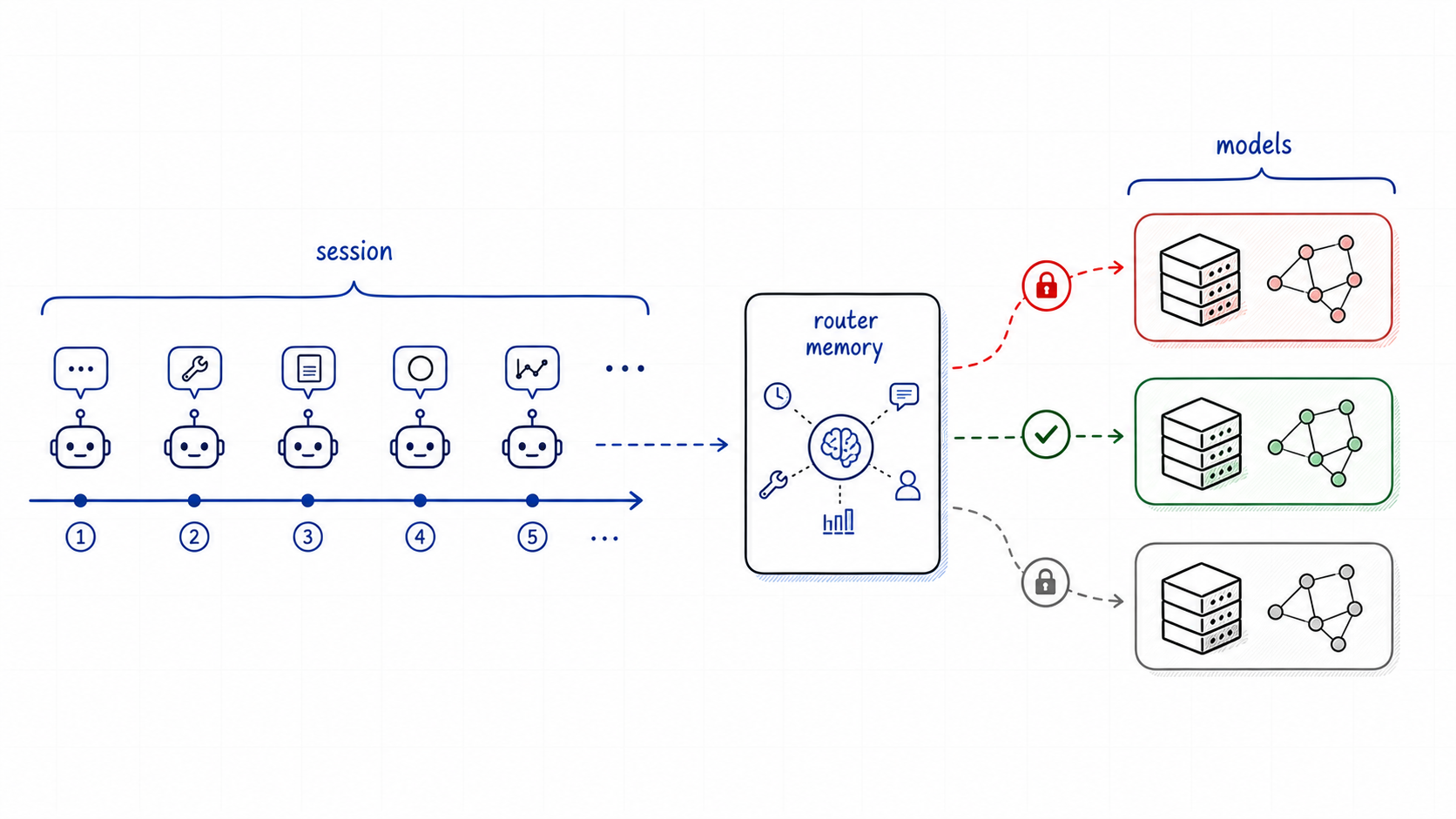
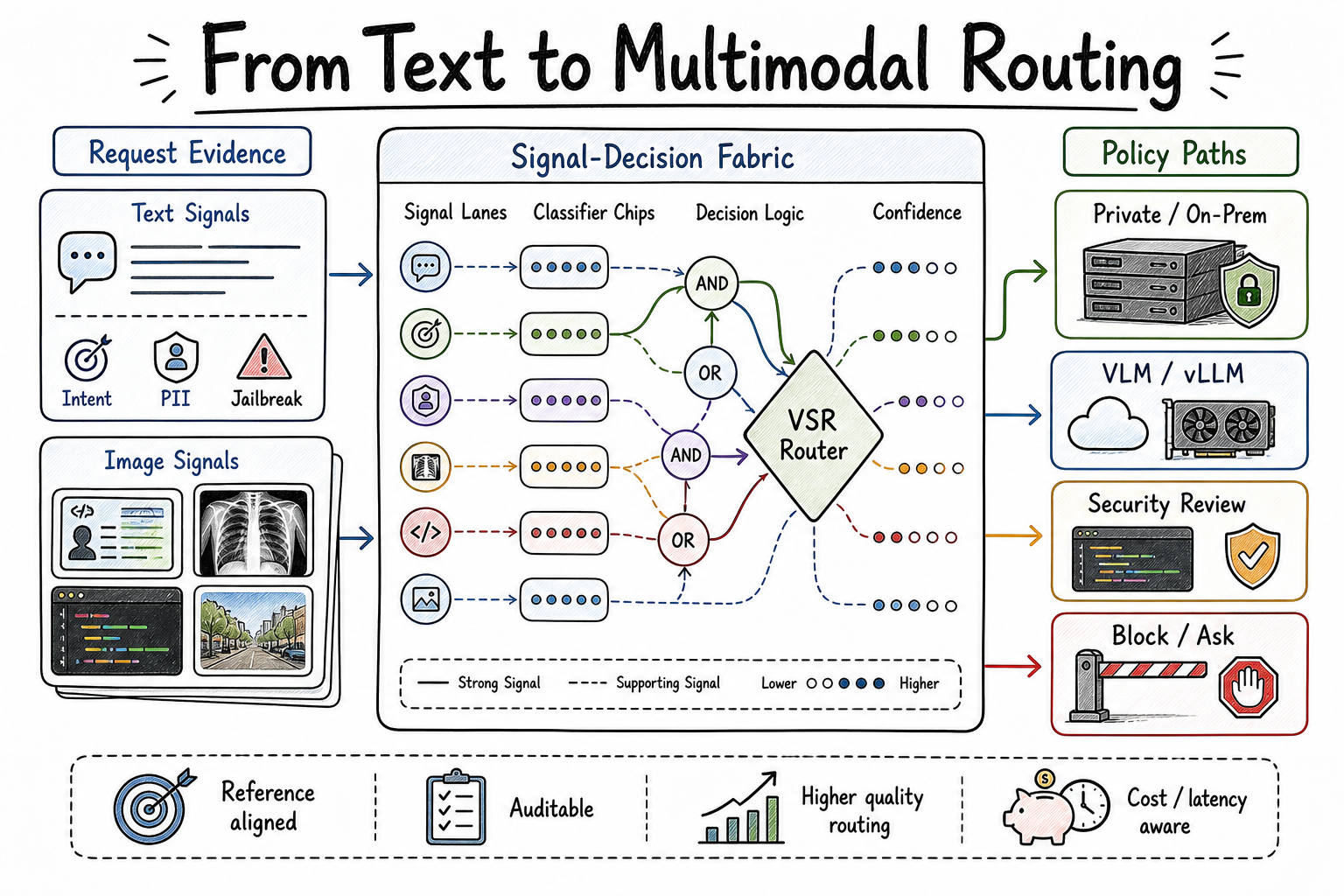
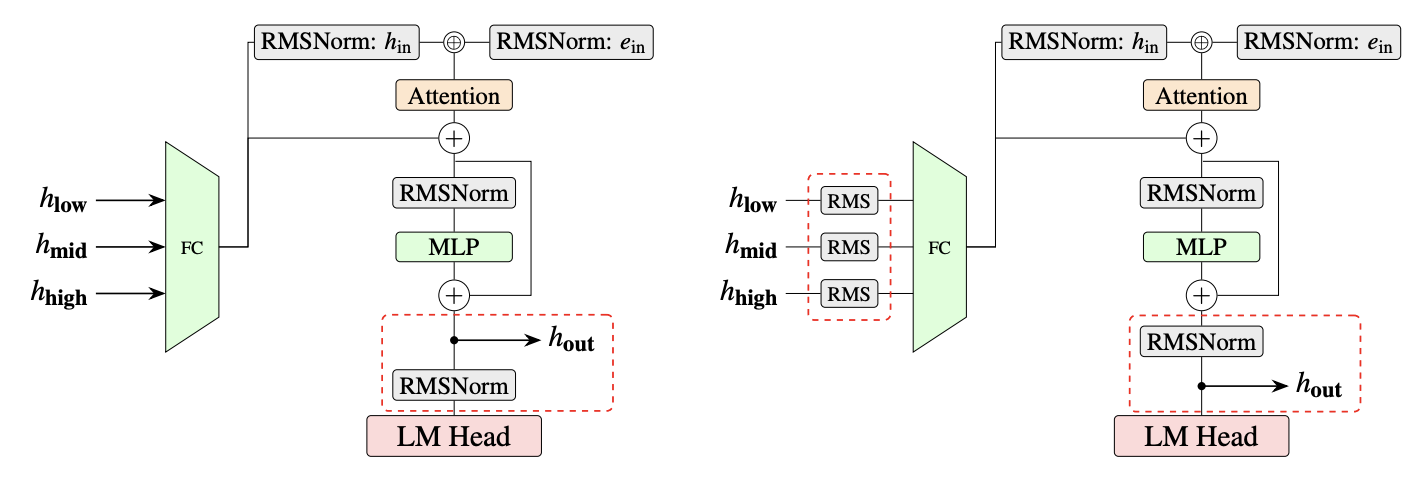
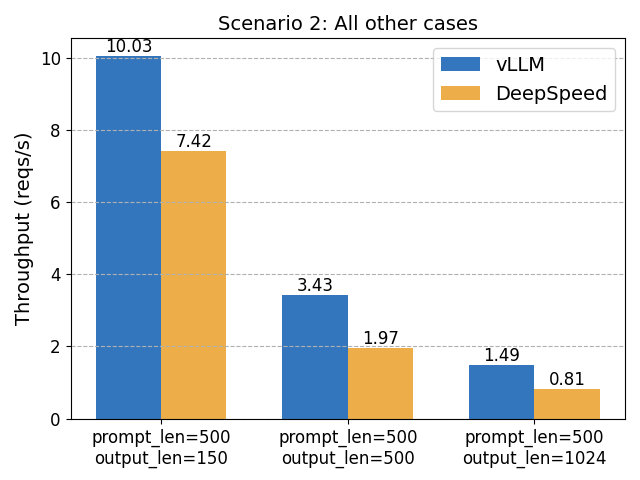
A preview of production-scale Kimi K3 support in vLLM, including KDA-aware prefix caching, fused kernels, optimized MXFP4 MoE, multimodal integration, and initial NVIDIA and AMD paths.