EAGLE 3.1: Advancing Speculative Decoding Through Collaboration Between the EAGLE Team, vLLM, and TorchSpec
The EAGLE series — including EAGLE 1, EAGLE 2, and EAGLE 3 — has become one of the most widely adopted and practically deployed families of speculative decoding algorithms across both research and production systems.
Today, the EAGLE team, vLLM team, and TorchSpec team are excited to jointly introduce EAGLE 3.1 — a major step forward in speculative decoding robustness, efficiency, and deployability.
EAGLE 3.1 Innovations
While speculative decoding performs well in controlled settings, performance often degrades under different chat templates, long-context inputs, or out-of-distribution system prompts.
The EAGLE team traced this fragility to a phenomenon we call attention drift — as speculation depth increases, the drafter gradually shifts attention away from sink tokens and toward its own generated tokens.
We identified two underlying issues. First, the fused input representation becomes increasingly imbalanced as higher-layer hidden states dominate the drafter input. Second, hidden-state magnitude grows across speculation steps due to the unnormalized residual path. Together, these effects make the drafter progressively less stable at deeper speculation depths.
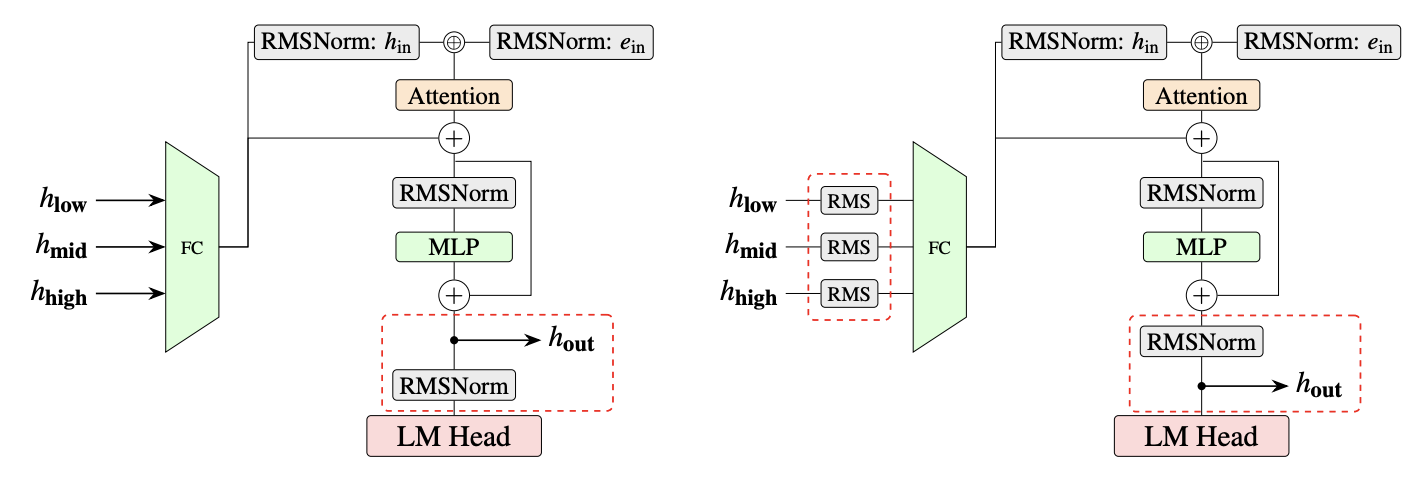
To address this issue, EAGLE 3.1 introduces two key architectural improvements:
- FC normalization after each target hidden state and before the FC layer
- Feeding post-norm hidden states into the next decoding step
Intuitively, the post-norm design makes the method behave more like recursively invoking the drafter across decoding steps, rather than simply appending additional layers to the target model.
These changes significantly improve robustness across deployment scenarios. Compared with EAGLE 3, EAGLE 3.1 demonstrates:
- Better training-time to inference-time extrapolation
- Stronger long-context robustness
- Higher resilience to chat template and system prompt variation
- More stable acceptance length across diverse serving environments
In long-context workloads, EAGLE 3.1 achieves up to 2× longer acceptance length compared with EAGLE 3.
EAGLE 3.1 Training with TorchSpec
TorchSpec now provides efficient training support for EAGLE 3.1 and future speculative decoding algorithms.
By lowering training overhead and simplifying experimentation workflows, TorchSpec helps accelerate iteration and exploration for next-generation speculative decoding research and deployment.
Based on TorchSpec and vLLM, we also trained and open-sourced an EAGLE 3.1 draft model for Kimi K2.6:
https://huggingface.co/lightseekorg/kimi-k2.6-eagle3.1-mla
The model serves as an example of deploying EAGLE 3.1 with TorchSpec training and vLLM serving support on a real-world serving model.
EAGLE 3.1 Integration with vLLM
EAGLE 3.1 lands in vLLM as a config-driven extension of the existing EAGLE 3 implementation.
The integration includes:
- FC normalization support
- Post-norm hidden-state feedback
- Removal of hardcoded assumptions around target hidden states
At the same time, backward compatibility with existing EAGLE 3 checkpoints is fully preserved. As a result, EAGLE 3.1 draft models can be plugged directly through the same speculative-decoding code path, for example:
vllm serve nvidia/Kimi-K2.6-NVFP4 \
--trust-remote-code \
--tensor-parallel-size 4 \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2 \
--attention-backend tokenspeed_mla \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}' \
--language-model-onlyThis makes draft-model upgrades in production vLLM serving smooth and easy.
The support has already been merged into the current main branch of vLLM and will be available via vLLM's nightly release as well as the upcoming v0.22.0 release.
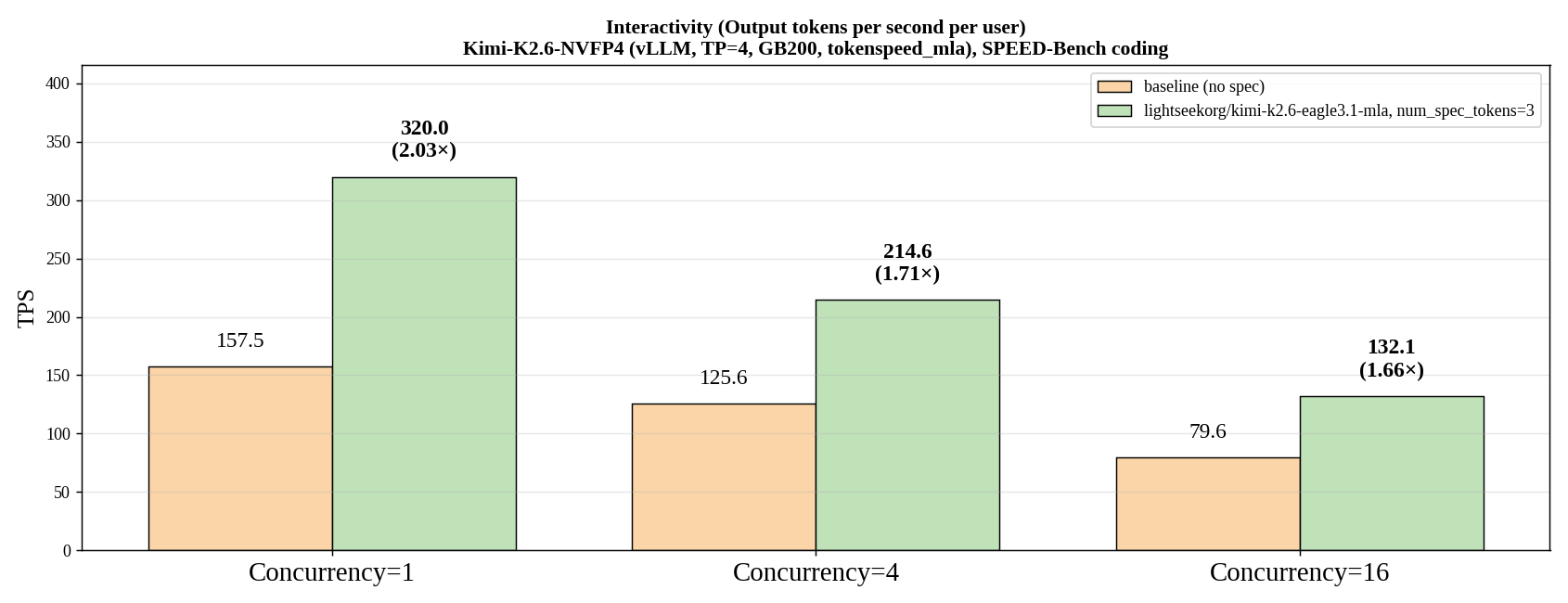
As an early data point, we benchmarked the Kimi K2.6 EAGLE 3.1 draft model on Kimi-K2.6-NVFP4 with vLLM (TP=4, GB200, non-disagg) on the SPEED-Bench coding dataset. EAGLE 3.1 delivers 2.03× higher per-user output throughput at concurrency 1, and the speedup stays meaningful as concurrency scales (1.71× at C=4, 1.66× at C=16).
Open-Source Collaboration Across the Ecosystem
This collaboration between the EAGLE team, vLLM team, TorchSpec team represents a strong example of open-source collaboration across algorithm research, system optimization, and training infrastructure.
The EAGLE team continues advancing speculative decoding algorithms, vLLM helps bring these innovations into production inference systems at scale, and TorchSpec enables efficient training and rapid experimentation for future speculative decoding algorithms.
We are also grateful to NVIDIA for their GPU support and continued partnership. This support has played an important role in enabling the development, validation, and benchmarking efforts required to bring EAGLE 3.1 from algorithmic innovation to practical deployment.
Together, we hope to continue raising the overall baseline for speculative decoding and driving further improvements in token efficiency across the broader LLM ecosystem.