From Text to Multimodal Routing: Hardening Vision Signals in vLLM Semantic Router
Most routing systems start with a prompt and choose a model endpoint. vLLM Semantic Router (VSR) makes a different bet: before a request reaches the serving model, the system should extract signals, compose those signals into decisions, and make the chosen path observable, auditable, and programmable.
That idea started with text. Iris introduced the Signal-Decision architecture, moving VSR beyond a fixed domain classifier and into a richer system where intent, keywords, embeddings, safety, PII, semantic cache, and plugins can all participate in routing. Athena pushed the same idea further: Semantic Router is not only a fast classifier in front of vLLM, but a system-level intelligence layer for mixture-of-models and agentic deployments.
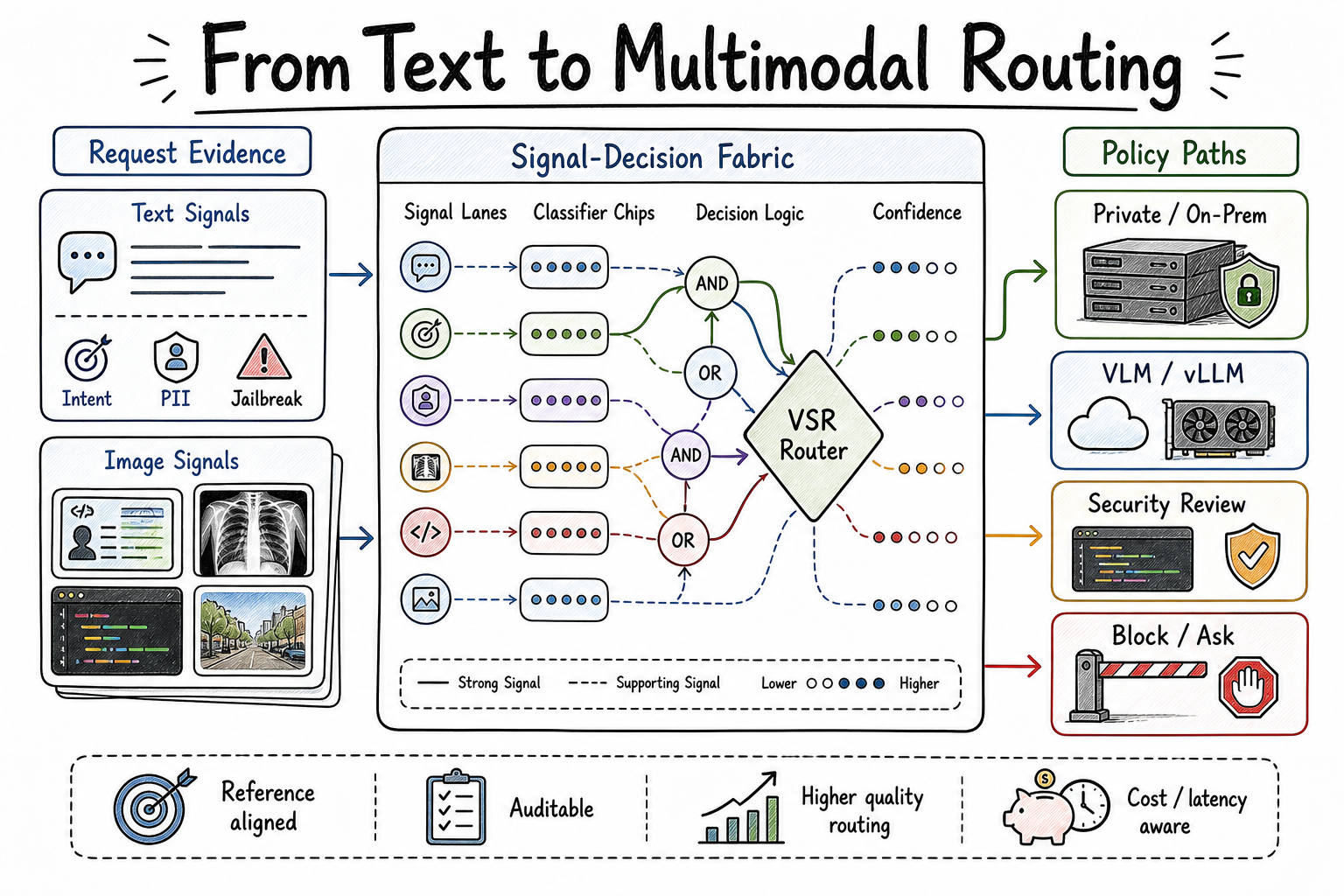
The next boundary is multimodal routing. Once an image, screenshot, scan, or document page enters the request, the router is no longer reasoning over a prompt alone. It is reasoning over request evidence. The image may be the part that makes the request clinical, regulated, security-sensitive, out of domain, or worth routing to a stronger vision-language model. A router that only sees text is routing a partial request.
This post is about crossing that boundary. The important step is not simply adding an image encoder. The important step is turning visual evidence into a trustworthy VSR signal that can be composed with text signals inside the same decision fabric.
The hardening story below explains why that distinction matters. A deployed multimodal path around multi-modal-embed-small looked confidently wrong. The first explanation seemed obvious: maybe the compact vision encoder was not strong enough. The actual issue was more useful to find and more important for production systems: the Rust/Candle path used by VSR did not match the PyTorch reference path for the same model.
Multimodal routing is not image classification
Text-only routing already handles more than topic matching. In the Signal-Decision model, signals are independent observations, decisions compose those observations with priority and boolean logic, and plugins or model references define what should happen next. That separation is what lets VSR express policies like "security-sensitive code review gets a stronger reasoning model and jailbreak checks" instead of "computer science goes to the coding model."
Multimodal routing keeps that same shape, but changes the unit of analysis from a text prompt to a full request. The text can be generic while the image carries the decisive evidence:
| Request evidence | Text-only router sees | Multimodal router should see |
|---|---|---|
| "Summarize this" + passport image | Generic summarization | Identifier document, PII risk, restricted handling |
| "What does this show?" + chest X-ray | Vague visual question | Clinical image, medical-domain policy, capable VLM target |
| "Find the bug" + code screenshot | Coding request | Code artifact, possible secret leakage, security review path |
| Medical prompt + unrelated car image | Medical text | Out-of-domain visual evidence, clarification or rejection path |
The innovation is not that VSR can compute an image embedding. The innovation is that the image embedding becomes a typed signal in the same fabric as text intent, PII, jailbreak, domain, semantic similarity, plugins, and model selection. In other words, multimodal support turns VSR from prompt-level routing into request-level policy.
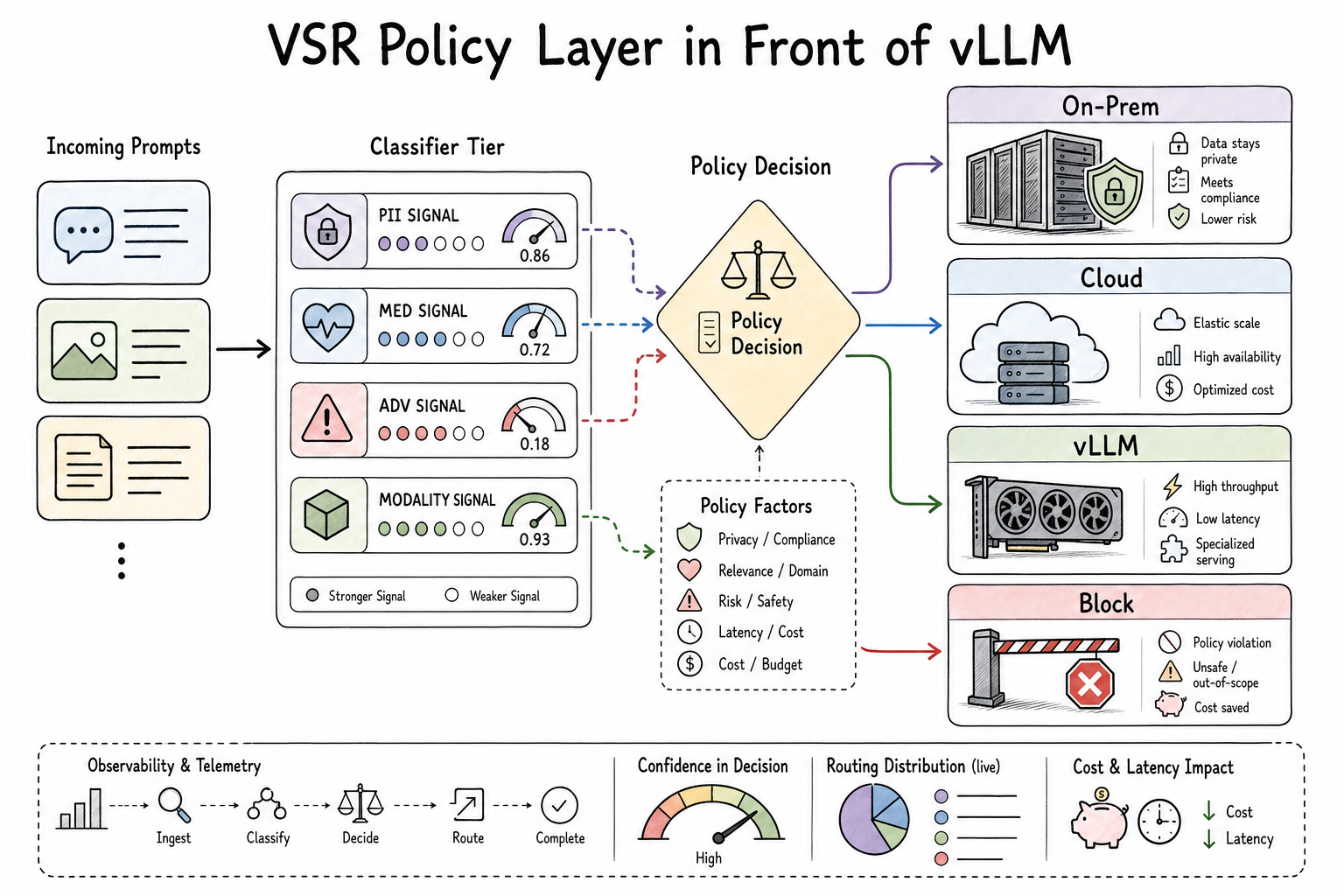
That is also why signal correctness becomes a control-plane requirement. If a text signal is wrong, a policy can route to the wrong model or skip the wrong plugin. If a vision signal is anti-correlated, the problem is worse: the router can become confidently wrong while still leaving a clean, repeatable audit trail for the wrong decision.
Reference parity is therefore not just model-quality hygiene. For VSR, it is a control-plane invariant. The deployed signal path must mean the same thing as the reference model path, or the decision layer is composing the wrong evidence.
When the vision signal was confidently wrong
The first symptom was not a small accuracy drop. On an 11-image probe across three verticals and 21 candidate labels, the deployed multi-modal-embed-small (mmes) path ranked the wrong vertical highest on 9 of 11 images. Medical X-rays scored closer to semiconductor candidates than to medical candidates. Identifier documents did not reliably land near identifier anchors.
That is an 82% inversion rate. The signal was anti-correlated, not merely noisy.
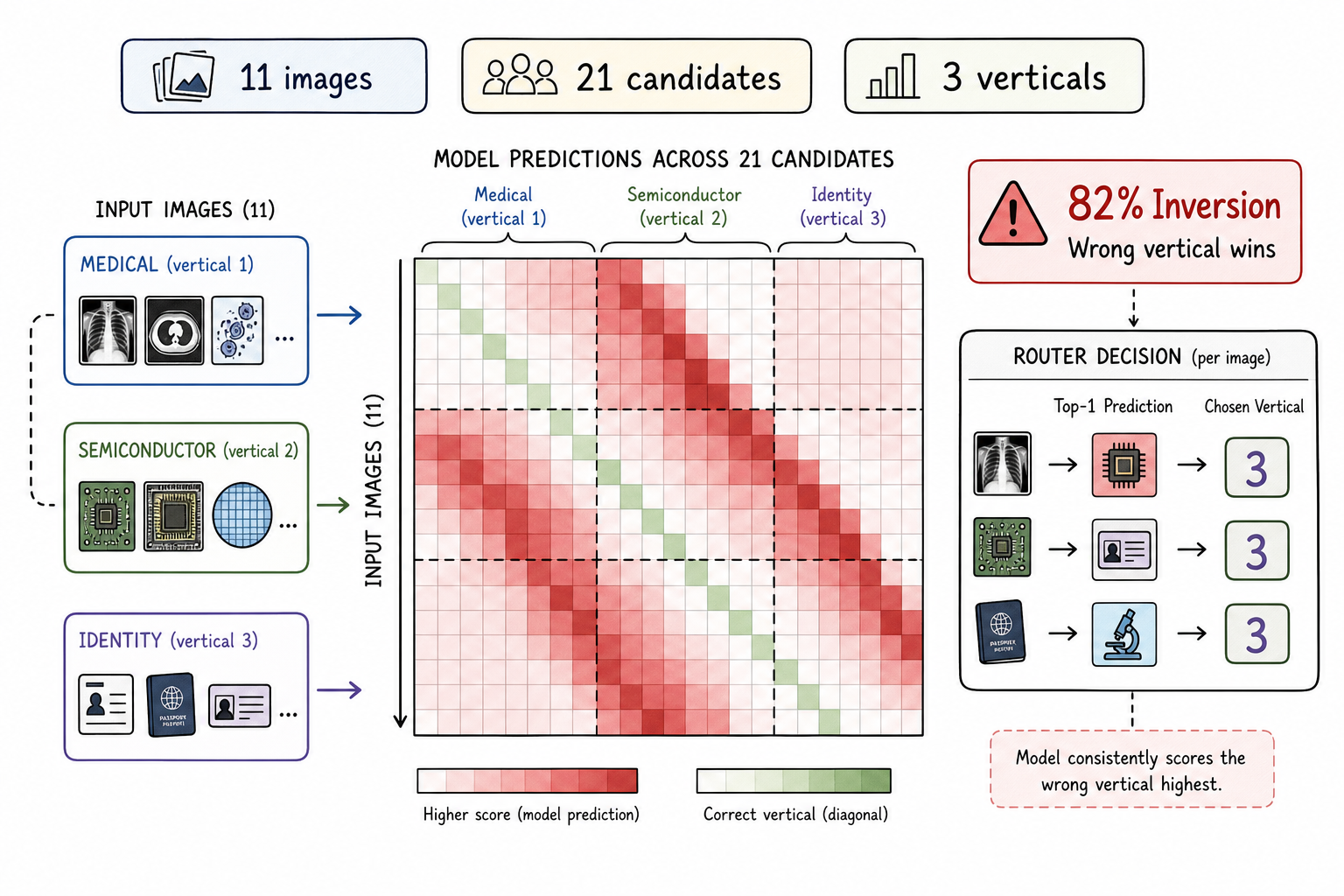
For a router, this failure mode matters more than a benchmark score. A classifier that is weak usually produces uncertainty. A classifier that is inverted produces confidence in the wrong direction. In a multimodal policy layer, that can be worse than having no image signal at all.
The production surface that exposed the issue was the image-modality routing work around multi-modal-embed-small, including the E2E routing profile introduced in vllm-project/semantic-router PR #1881. Once real images flowed through the Candle binding path, the gap became visible.
The tempting explanation: upgrade the encoder
The first hypothesis was natural: perhaps the compact encoder was not strong enough for the routing task. Around the same time, the team was already exploring the SigLIP2 family and the larger multi-modal-embed-large (mmEL) direction. That made an encoder upgrade feel like the obvious fix.
We tested that hypothesis directly:
- SigLIP2-base scored 10/10 on the same 21-candidate probe.
- SigLIP-base through Hugging Face Transformers also scored 10/10.
- mmEL, whose vision tower is based on SigLIP2, scored 10/10.
- The mmes model card loaded directly through the PyTorch reference path also scored 10/10.
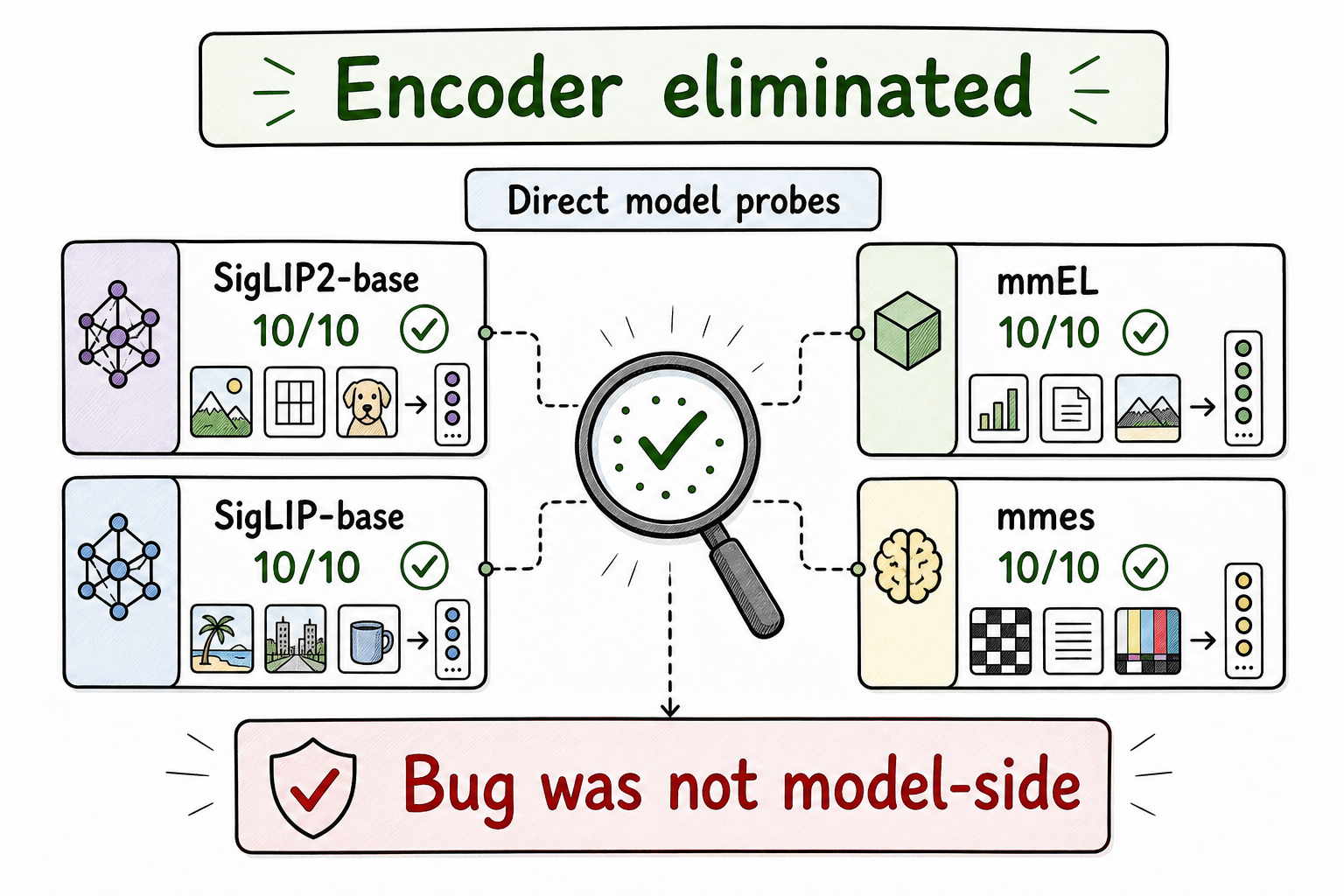
That result changed the shape of the investigation. The encoder family was not the root problem. Even the supposedly failing mmes model behaved correctly when loaded through the reference path.
There was still useful learning from the encoder chase. The larger SigLIP2-so400m variant showed stronger out-of-distribution rejection in this probe, suppressing an accidentally included car-engine image more aggressively than smaller variants. That may matter for future defensive routing when memory headroom allows a larger vision tower. But it was not the bug behind the inverted production signal.
The reference check that changed the investigation
The decisive test was simple: run the same mmes model on the same passport fixture through two paths and compare the embedding behavior.
The PyTorch reference path returned cosine 0.7204 against the relevant passport anchor. The deployed Candle-binding path returned 0.1576 on the same image and conceptual pipeline. That is a 5-8x magnitude gap on the same model and fixture.
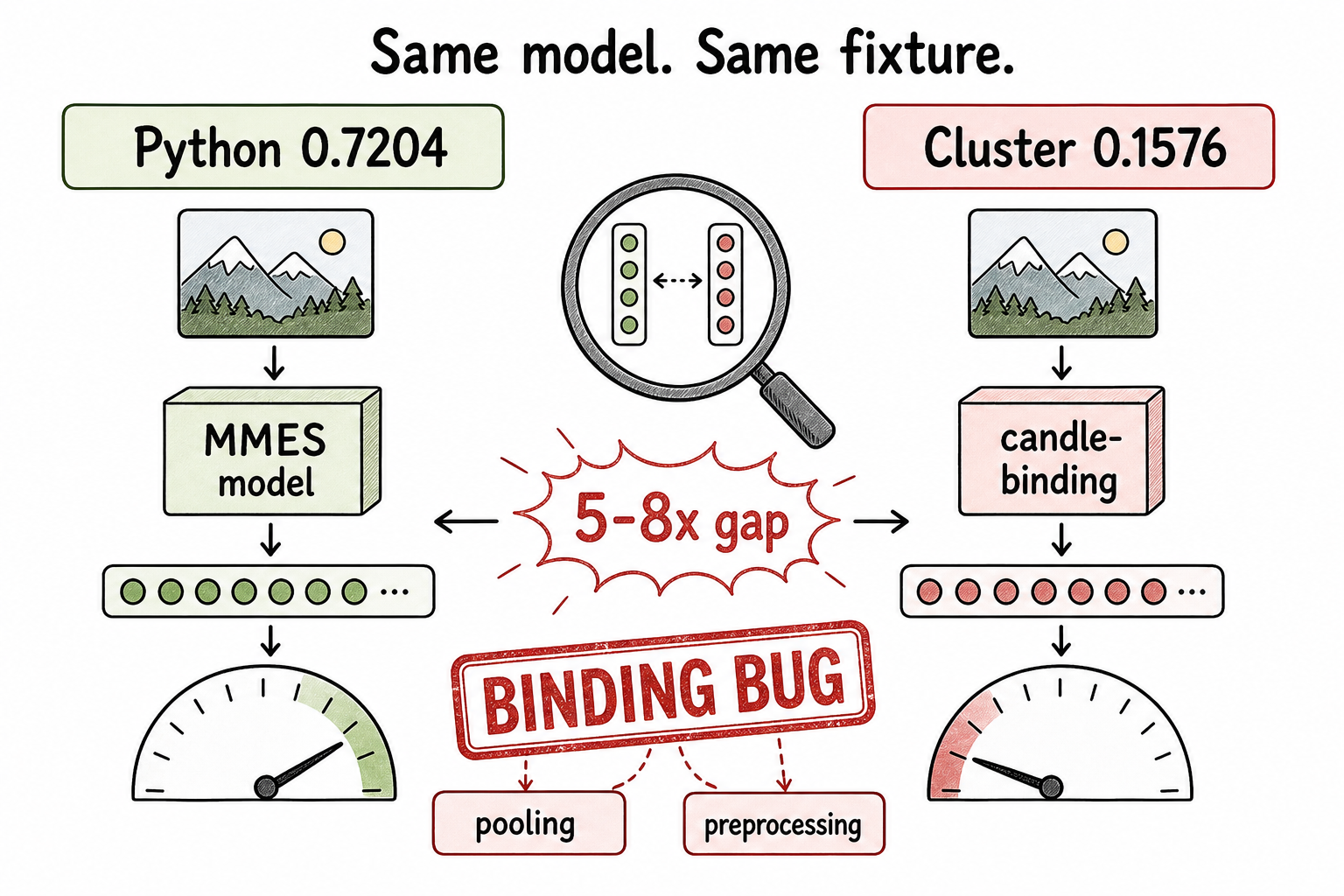
At that point, the investigation stopped being a model-selection question. The useful question became: where does the production path diverge from the reference path?
The lesson is straightforward: for multimodal routing, reference comparison should be the first diagnostic, not the last. When a production embedding path behaves strangely, compare it against the model card's reference loader before assuming the model itself is too weak.
This is especially important in VSR because the embedding is not only a retrieval primitive. It can become policy evidence. If that evidence has the opposite orientation from the reference model, every downstream layer can be logically correct and operationally wrong.
What was actually broken
The drift came from implementation details in the Candle path, not from the model weights. Three fixes isolate the problem into concrete layers.
First, the pooling head was wrong. SigLIPVisionEncoder::forward in candle-binding/src/model_architectures/embedding/multimodal_embedding.rs was effectively doing BERT-style mean + Linear + tanh pooling, while SigLIP uses an attentional probe pooling head. PR #1927 mirrors the SigLIP multi-head attention pooling behavior in Candle binding.
Second, the image normalization path was incomplete. The Go image loader produced CHW float32 pixels in [0, 1], while SigLIP expects per-channel normalization equivalent to (x - 0.5) / 0.5. PR #1928 applies that normalization in the Rust encoder path.
Third, preprocessing still carried residual drift after the pooling and normalization fixes. The old Go-side resize path used a 4-tap bilinear implementation. The PyTorch reference path uses PIL-style image preprocessing through SiglipProcessor. PR #1943 moves image decode, resize, and CHW float32 conversion into Rust using the image crate with Catmull-Rom filtering to approximate the PIL bicubic + antialias behavior.
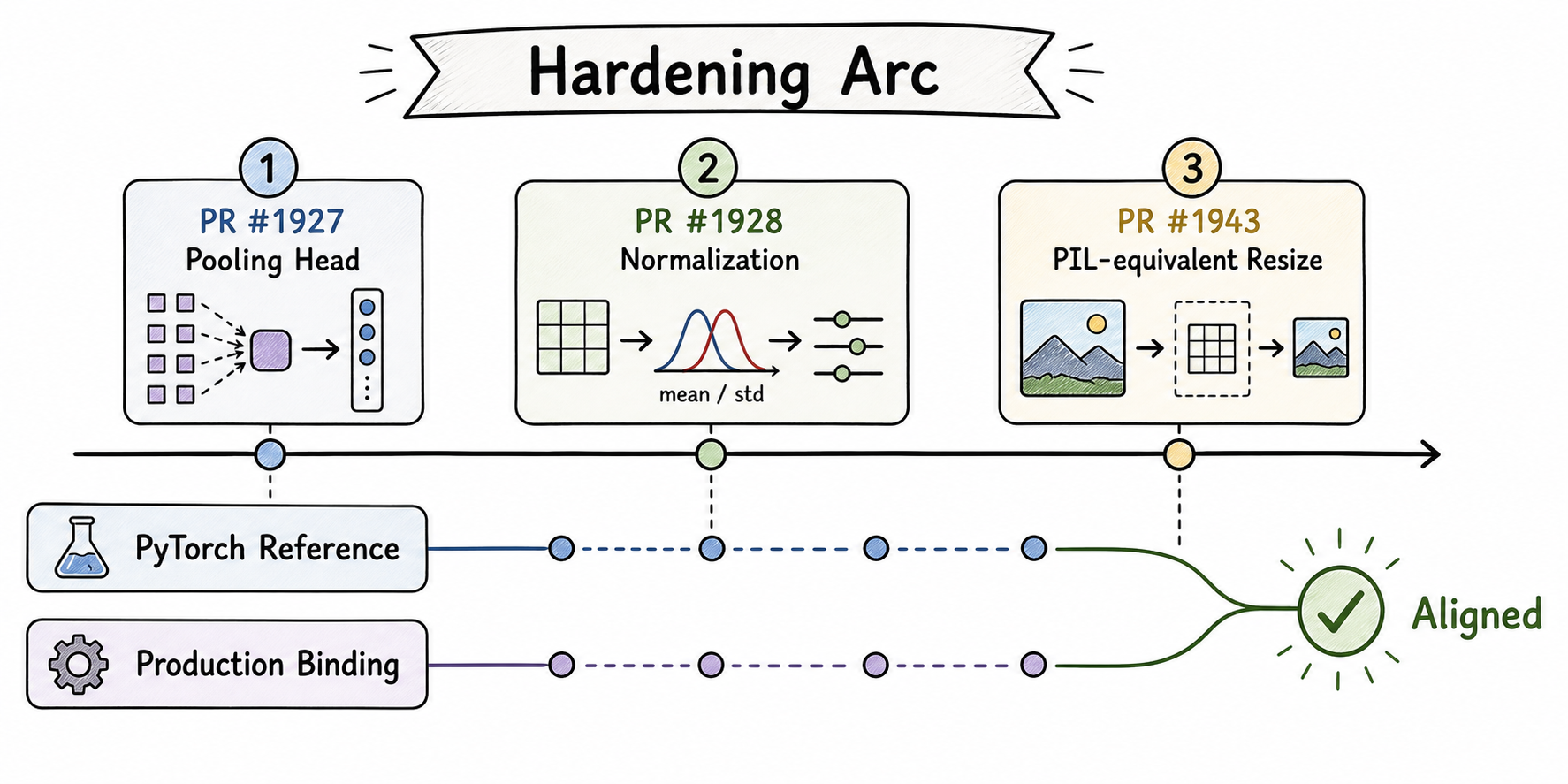
This is the class of bug that is easy to miss in a cross-language serving stack. The Go layer, Rust FFI layer, Candle model implementation, and PyTorch reference can all appear individually reasonable while still producing a route-breaking mismatch end to end.
Validation status
The numbers below are measurements from the PR branch stack for #1927, #1928, and #1943. They are included as the validation trail for the proposed hardening path. Until all three PRs merge, these numbers should be read as branch-stack validation rather than released production behavior.
A three-vector isolation experiment on the canonical passport fixture (inrule_identifier_passport.jpg) separates model-forward drift from preprocessing drift:
| Comparison | Cosine | Max abs diff | What it isolates |
|---|---|---|---|
| Python vs Candle-PIL | 0.999989 | 0.000911 | Model-forward only |
| Candle-PIL vs Candle-Go | 0.999916 | 0.001992 | Preprocessing only |
| Python vs Candle-Go | 0.999902 | 0.002120 | Full branch-stack pipeline |
The first row shows that the Rust model-forward path can match the PyTorch reference at fp32-level noise. The remaining drift after the first two fixes lived in preprocessing, which is why moving preprocessing across the FFI boundary matters.
Across a 20-image corpus covering identifier, ambient, code, adversarial, and out-of-distribution examples, the branch-stack measurements are:
- Cosine: min 0.999557, mean 0.999919, max 0.999978
- 20 / 20 images at cosine >= 0.999 vs PyTorch reference
- Pre-fix preprocessing cosine on the canonical fixture was 0.990145
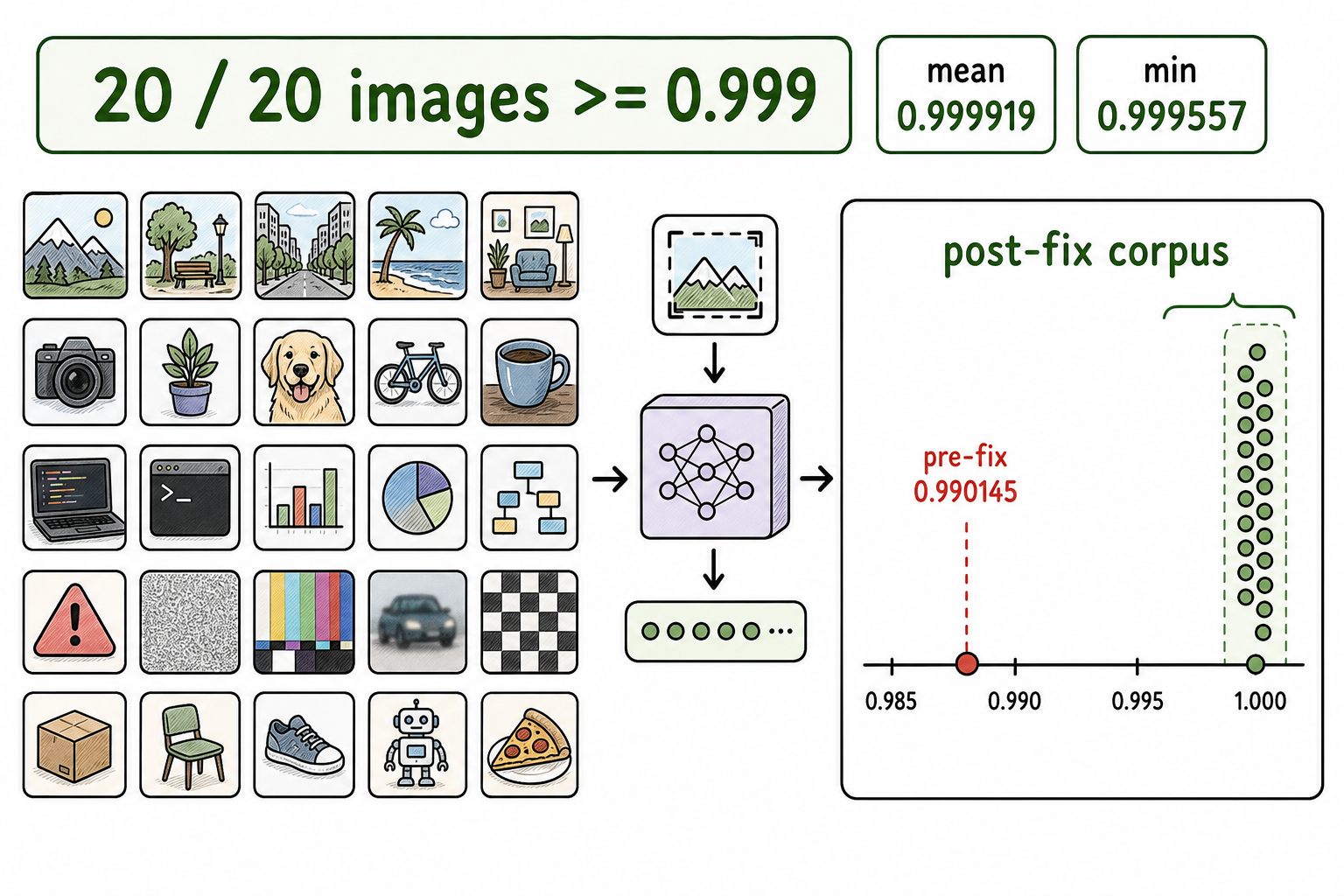
The important result is not just the final cosine number. It is the isolation method: compare the production path against the reference path, split model-forward drift from preprocessing drift, then make the production path use the same preprocessing semantics in tests and serving.
What this unlocks for VSR
Once the vision path is trustworthy, VSR can treat images as first-class evidence rather than side-channel metadata. That unlock is larger than "route image requests to an image model." It lets text and image evidence participate in the same Signal-Decision fabric:
| Combined signal pattern | Example decision |
|---|---|
| Clinical text + clinical image + PHI/PII signal | Route to a protected medical VLM path with privacy plugins enabled |
| Generic text + identifier image | Block, redact, or route to an identity-document handling policy before model invocation |
| Code/security prompt + code screenshot | Route to a security-specialized model and keep jailbreak checks on the original request |
| In-domain text + out-of-domain image | Ask for clarification or reject the image evidence instead of forcing a bad route |
This is the natural continuation of the Iris and Athena direction. Iris made routing decisions composable. Athena made the router more strategic by adding a stronger model stack, model selection, memory, replay, and richer signal handling. Multimodal routing extends that same architecture from language-only control to request-level control.
The public demo associated with this work is shrader.dev. Today it demonstrates the text-routing version of the policy pattern: domain relevance checks, privacy-sensitive routing, and blocked outcomes before model invocation. That demo is important because it shows the policy shape before images are added.
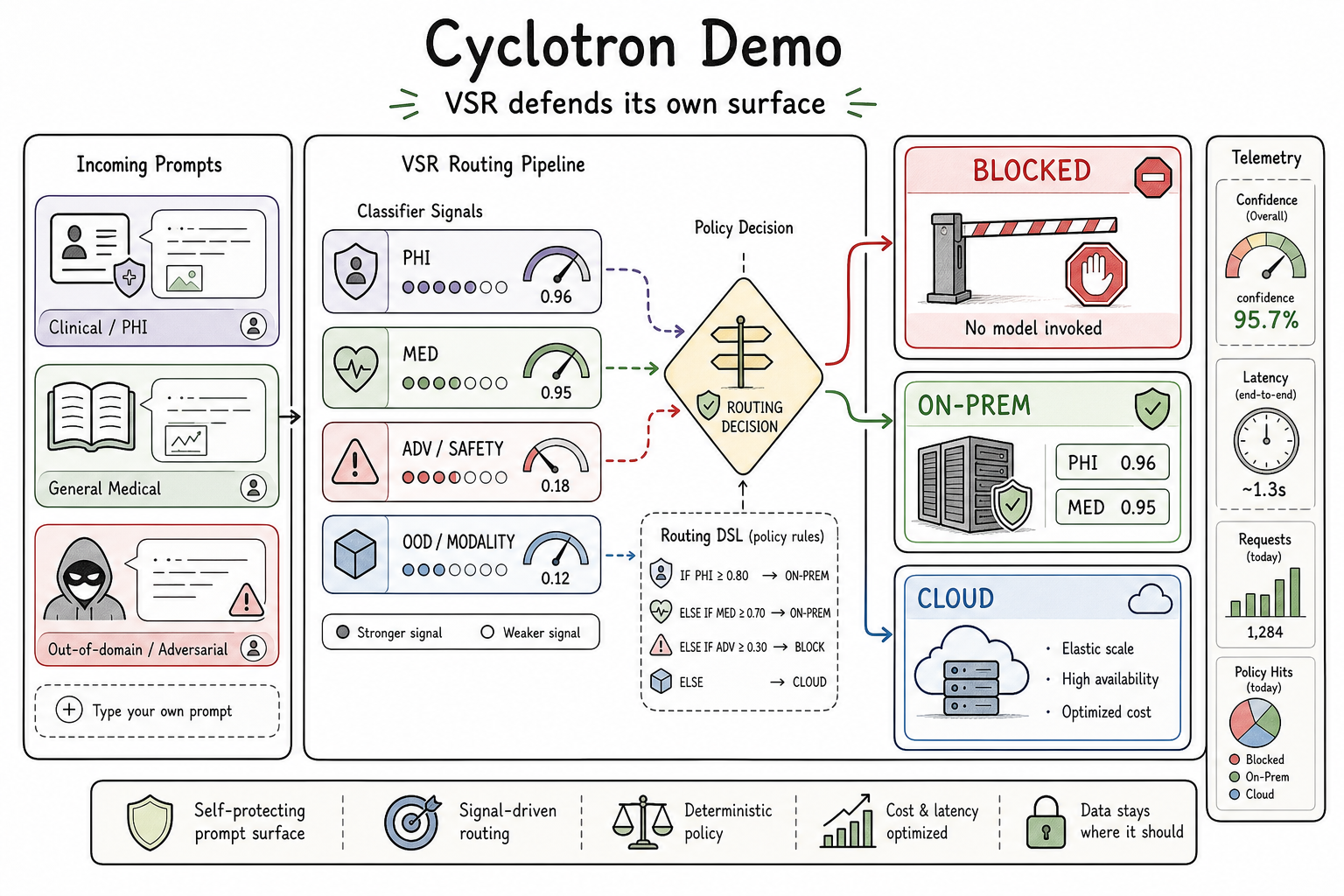
The text-routing path also illustrates a performance property that matters for multimodal production. Classifier signals can run concurrently through runSignalDispatchers, so wall-clock latency is bounded by the slowest enabled classifier rather than the sum of all classifiers. In a representative trace, the full classification decision completes in roughly 1.3 seconds on CPU.
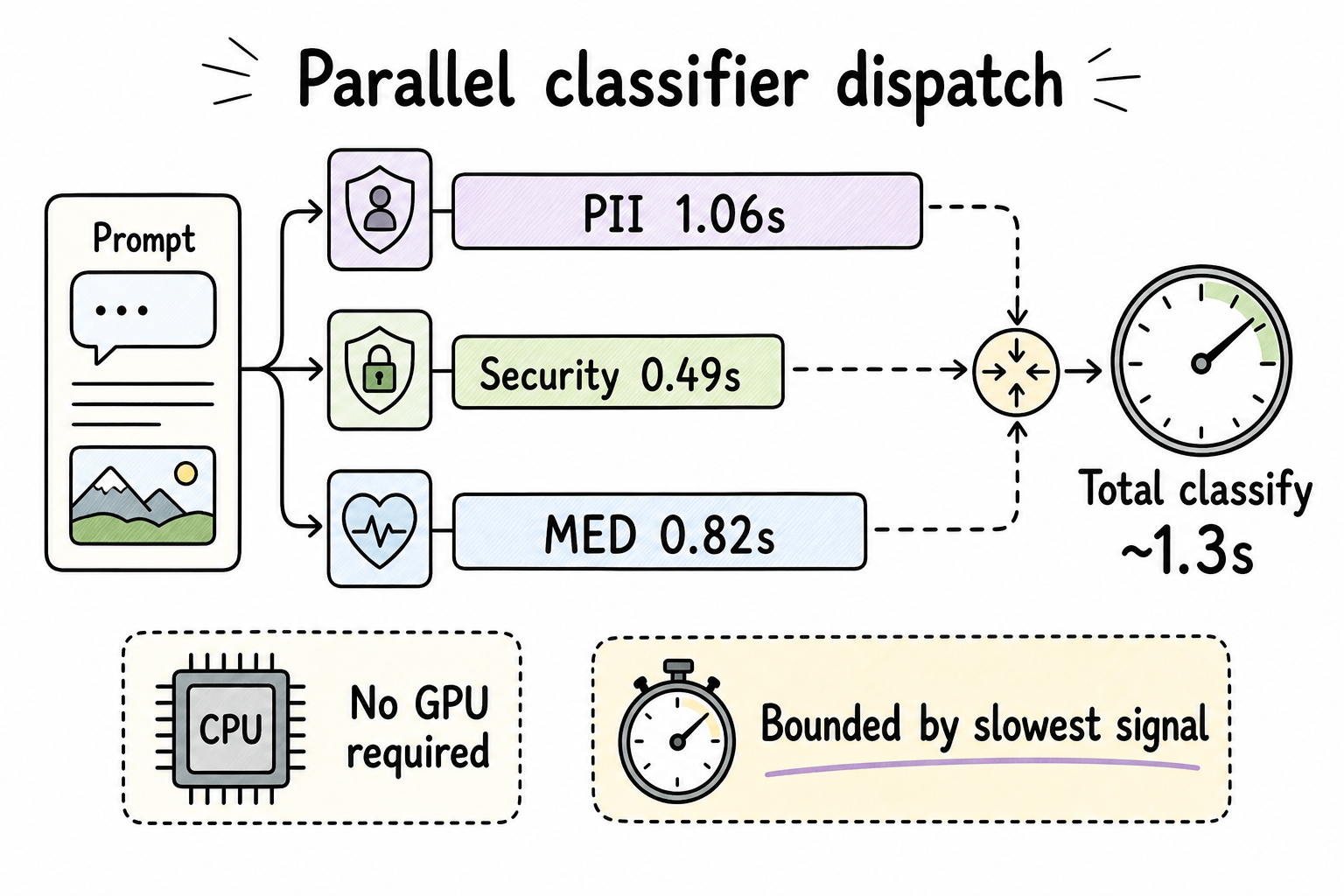
The multimodal version of that story is not a separate product path. It is the same policy engine with a larger evidence surface. Image and text signals should be extracted, validated, composed, replayed, and audited through the same routing semantics.
That is why the hardening work matters. If VSR is going to route on visual evidence, the vision signal path has to be boringly reliable. It must match the reference model, survive cross-language serving boundaries, and remain testable as policies become more expressive.
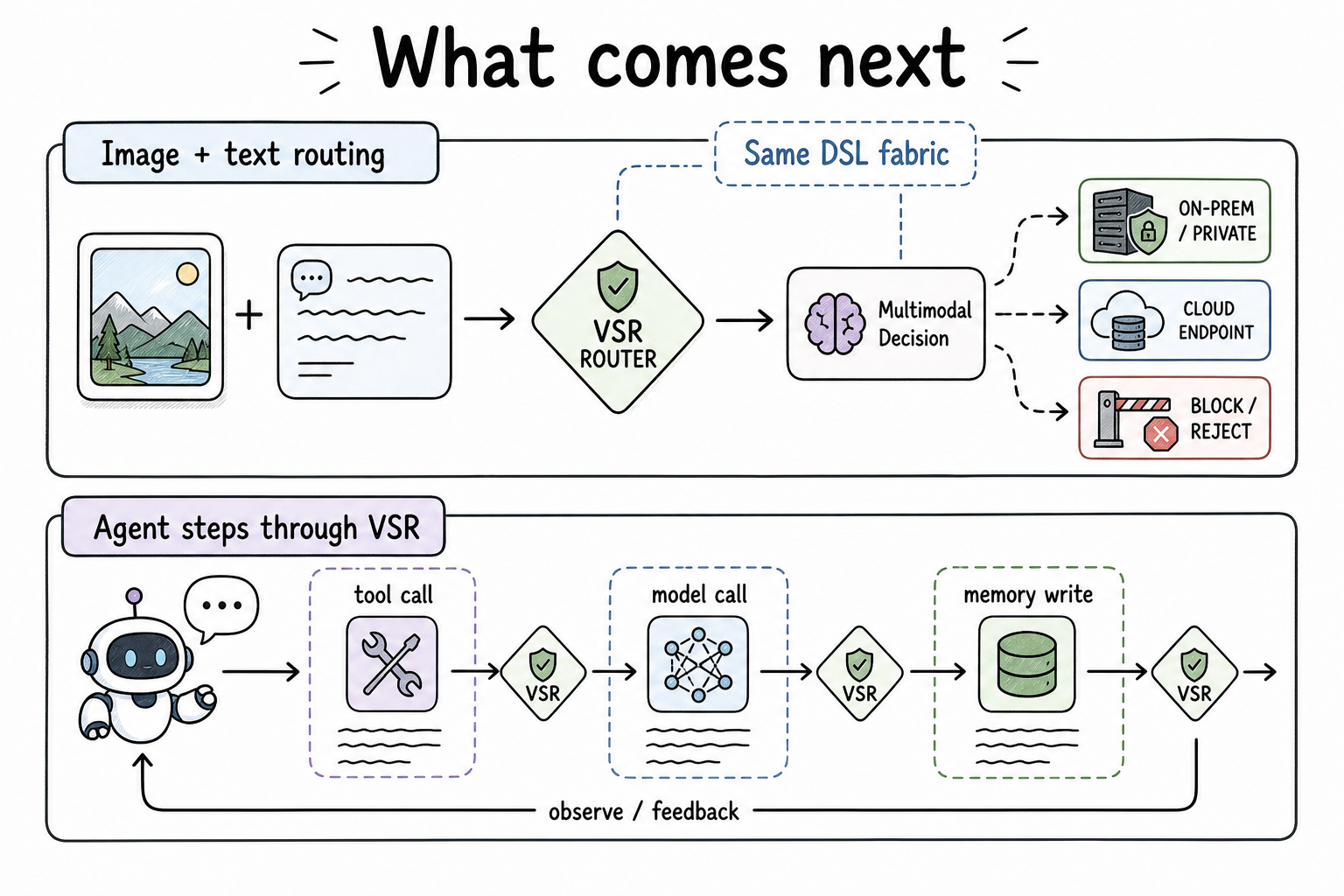
What comes next
The immediate work is to land and review the hardening PRs, then keep the validation corpus in the loop as multimodal routing evolves. The larger direction is to make reference-driven checks a normal part of VSR's multimodal serving story.
From there, the next steps are architectural:
- expose image-derived signals in the same decision layer as text-derived signals;
- keep multimodal decisions visible in replay, metrics, and debugging tools;
- make model selection aware of both policy fit and modality capability;
- preserve high-fidelity inspection for safety-critical signals such as PII and jailbreak;
- extend the same fabric toward agentic workflows, where tool calls, memory writes, and model invocations are routed through one decision layer.
Text routing was the first control surface. Multimodal routing is the next one. The goal is not to build a one-off visual classifier beside the router, but to make every meaningful part of a request available to the same programmable routing brain.
Getting started:
- Project repository: vllm-project/semantic-router
- Live demo: shrader.dev
Acknowledgments
Thanks to Huamin Chen for the mmEL pointer that helped break the encoder-upgrade misdiagnosis, the maintainer reviews across #1927, #1928, and #1943, and the invitation to write this up. Thanks also to the broader maintainer team for the multi-modal classifier work this arc plugs into, the multi-modal-embed-small model card, and the Candle-binding integration this all builds on.