From Day 0 to Production SLAs: Serving GLM-5.2 on 24 NVIDIA B300 GPUs with vLLM
·18 min read
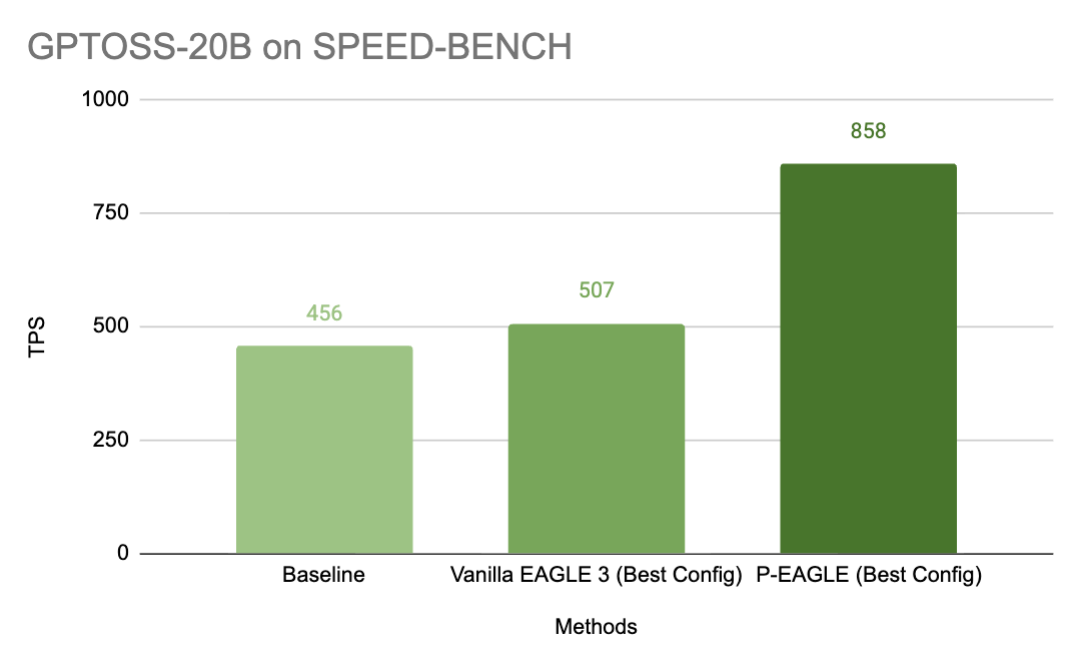
How we took GLM-5.2-NVFP4 from 40 ms to 17 ms mean TPOT on 24 B300 GPUs with vLLM: P/D disaggregation, MTP speculative decoding, Model Runner V2, and the SLA-first trade-offs behind the final configuration.