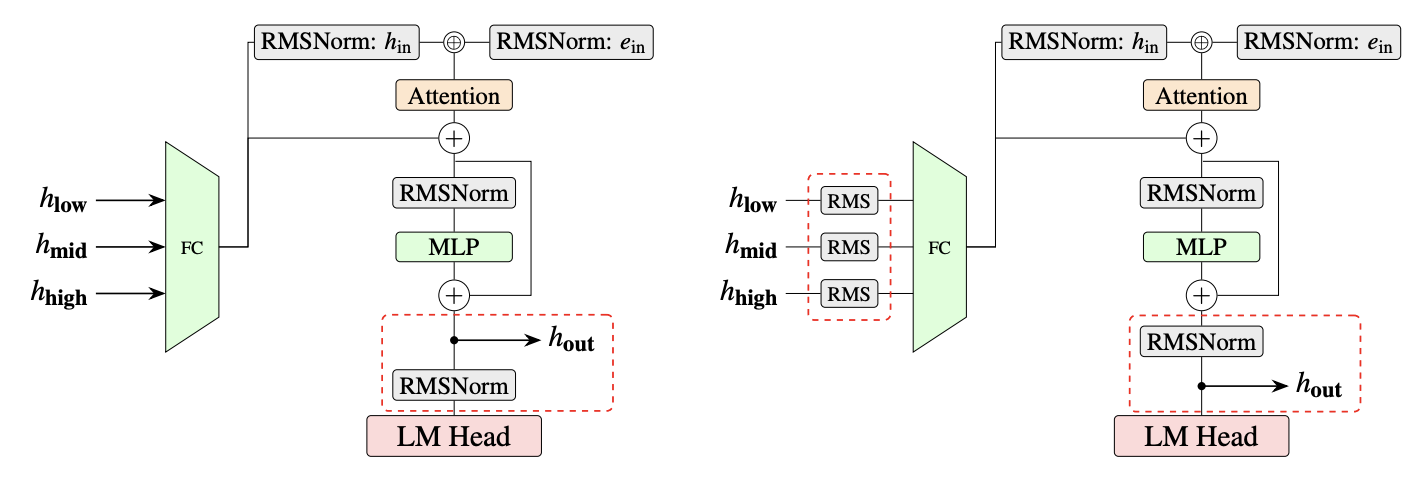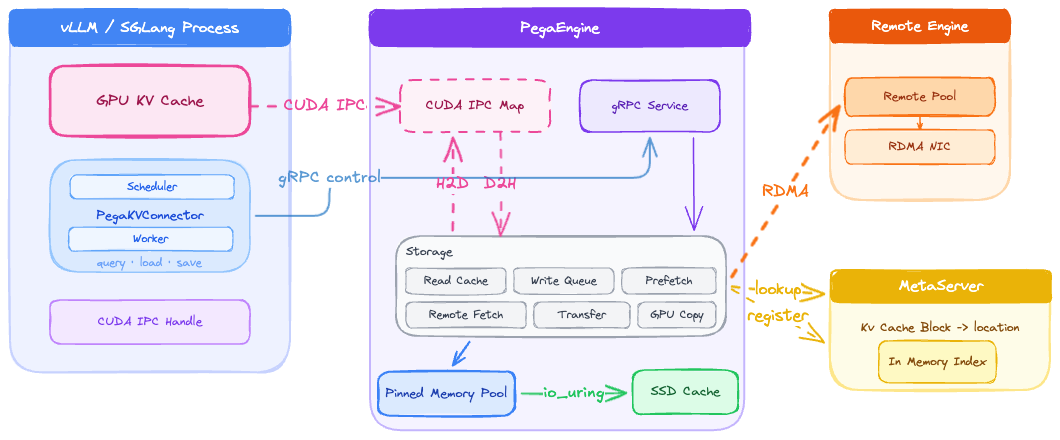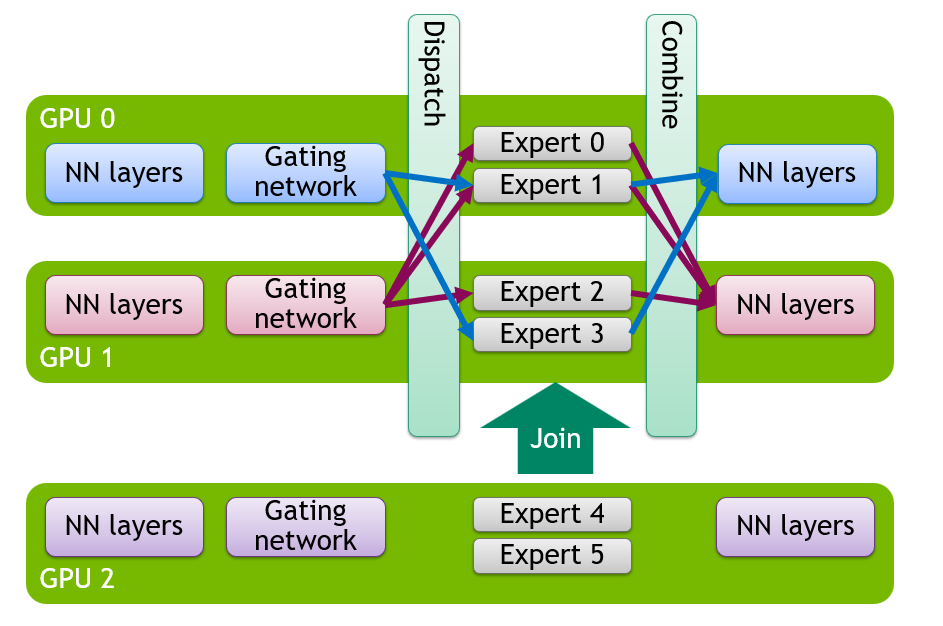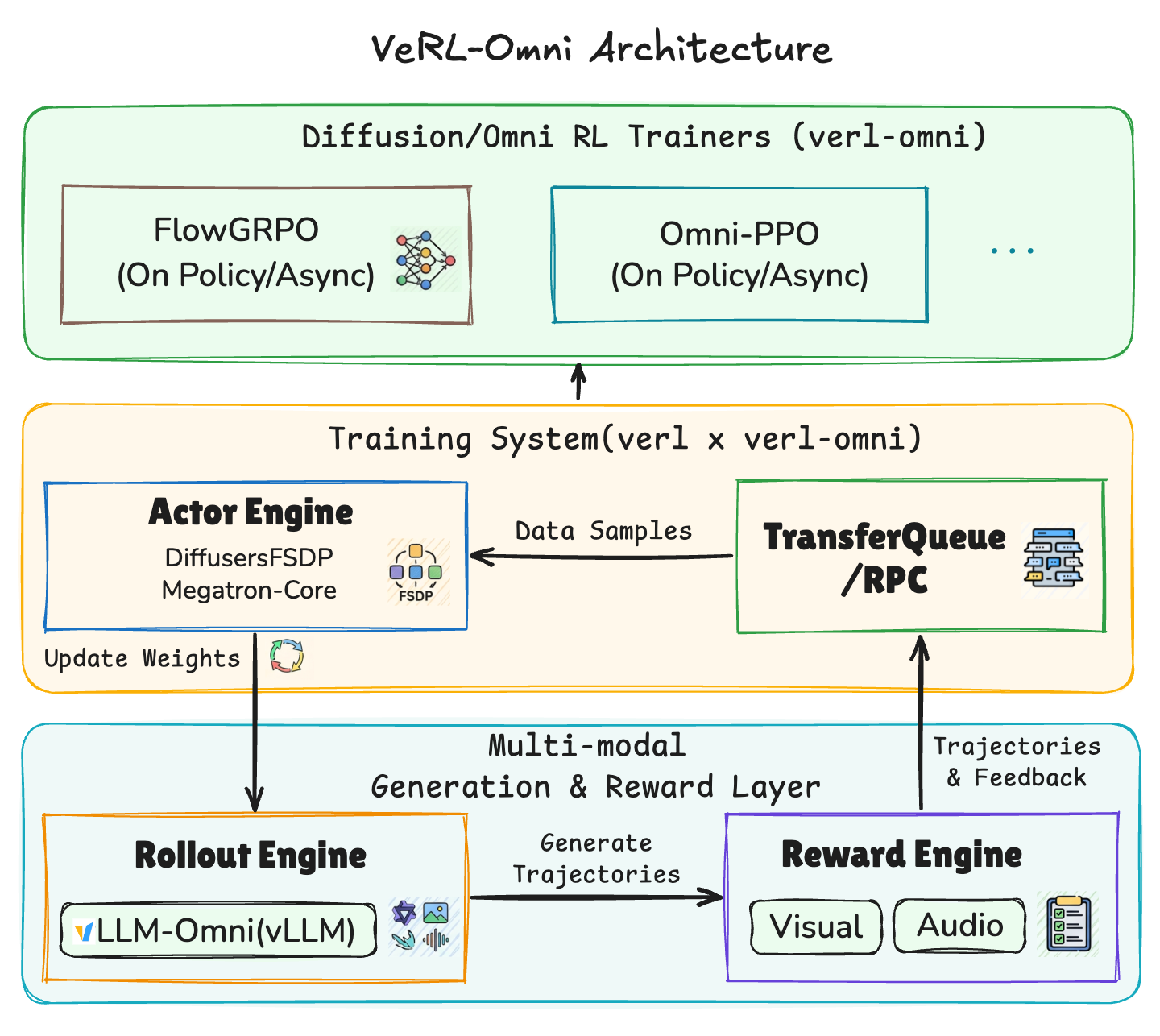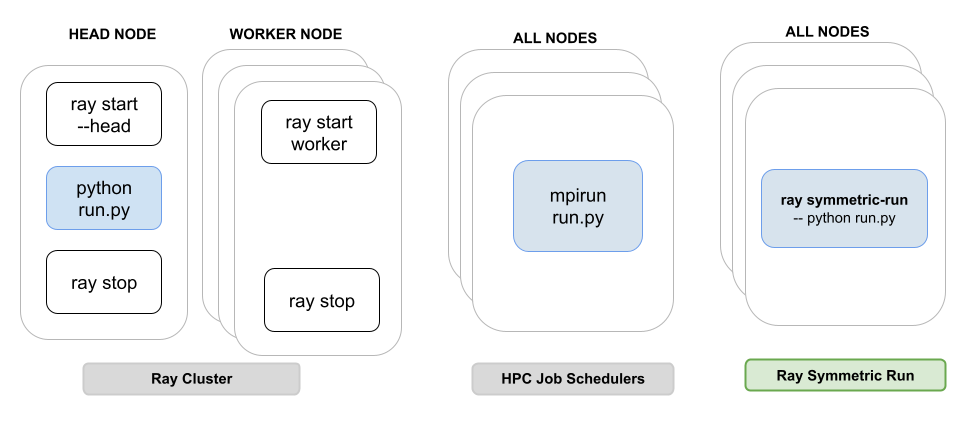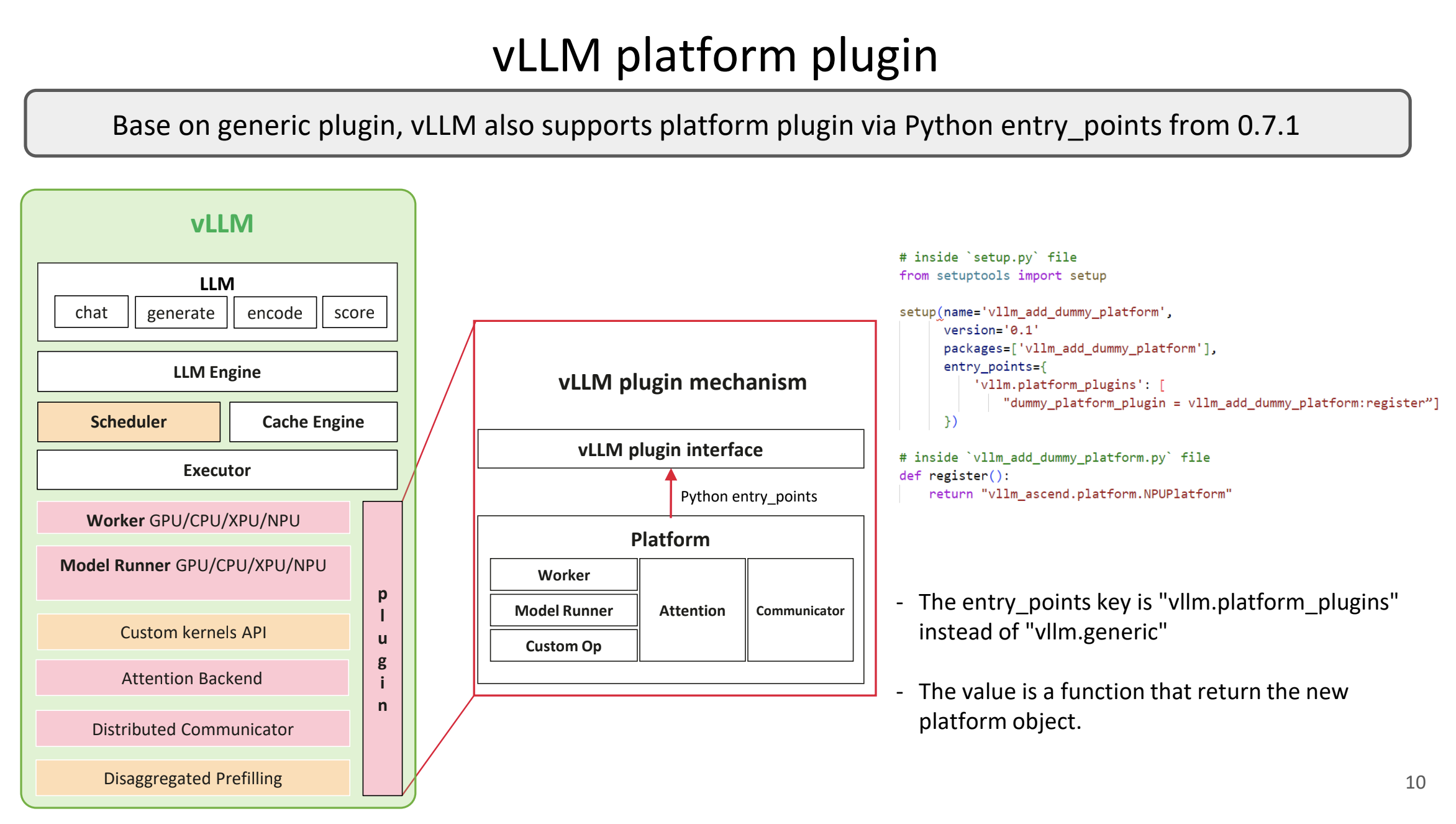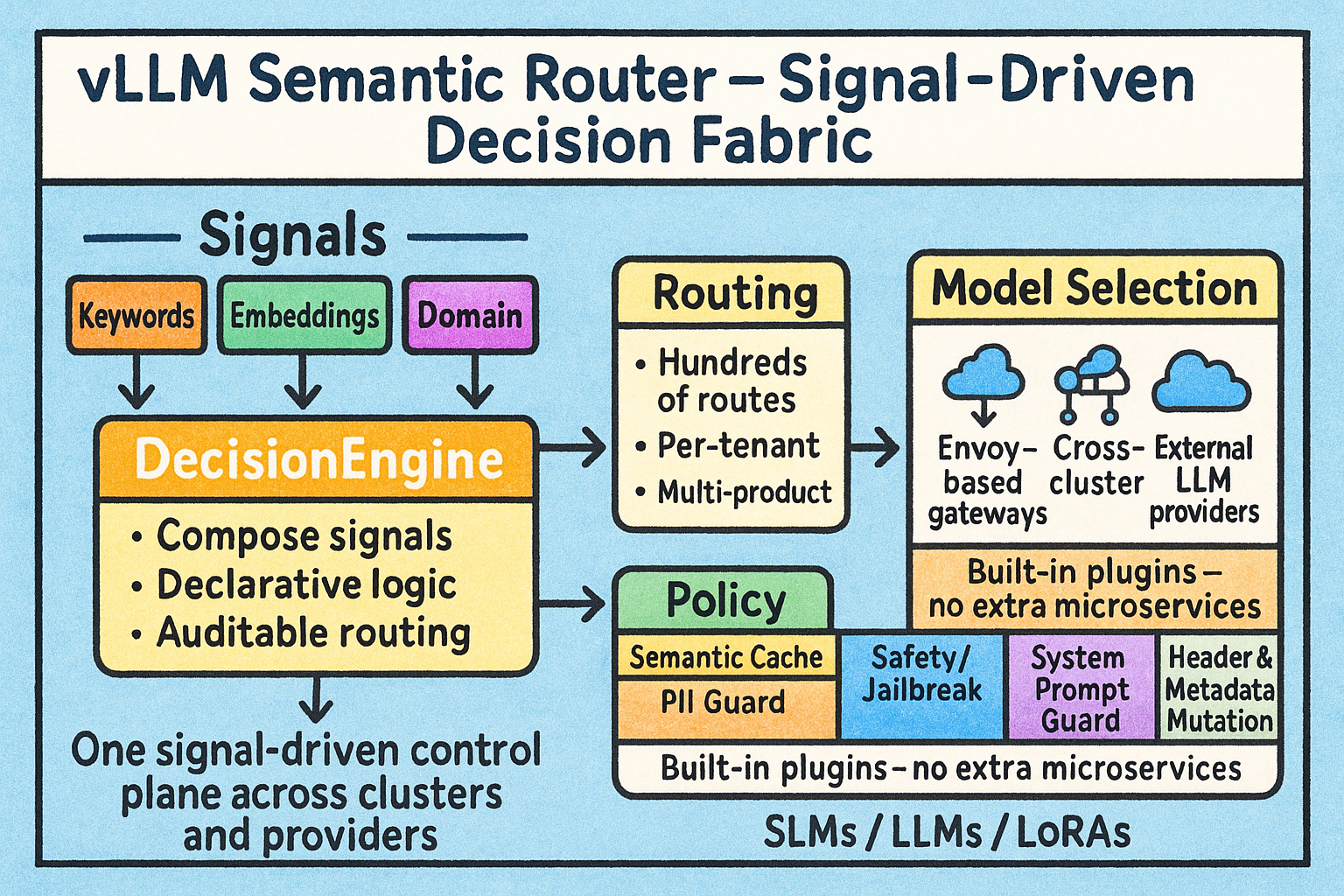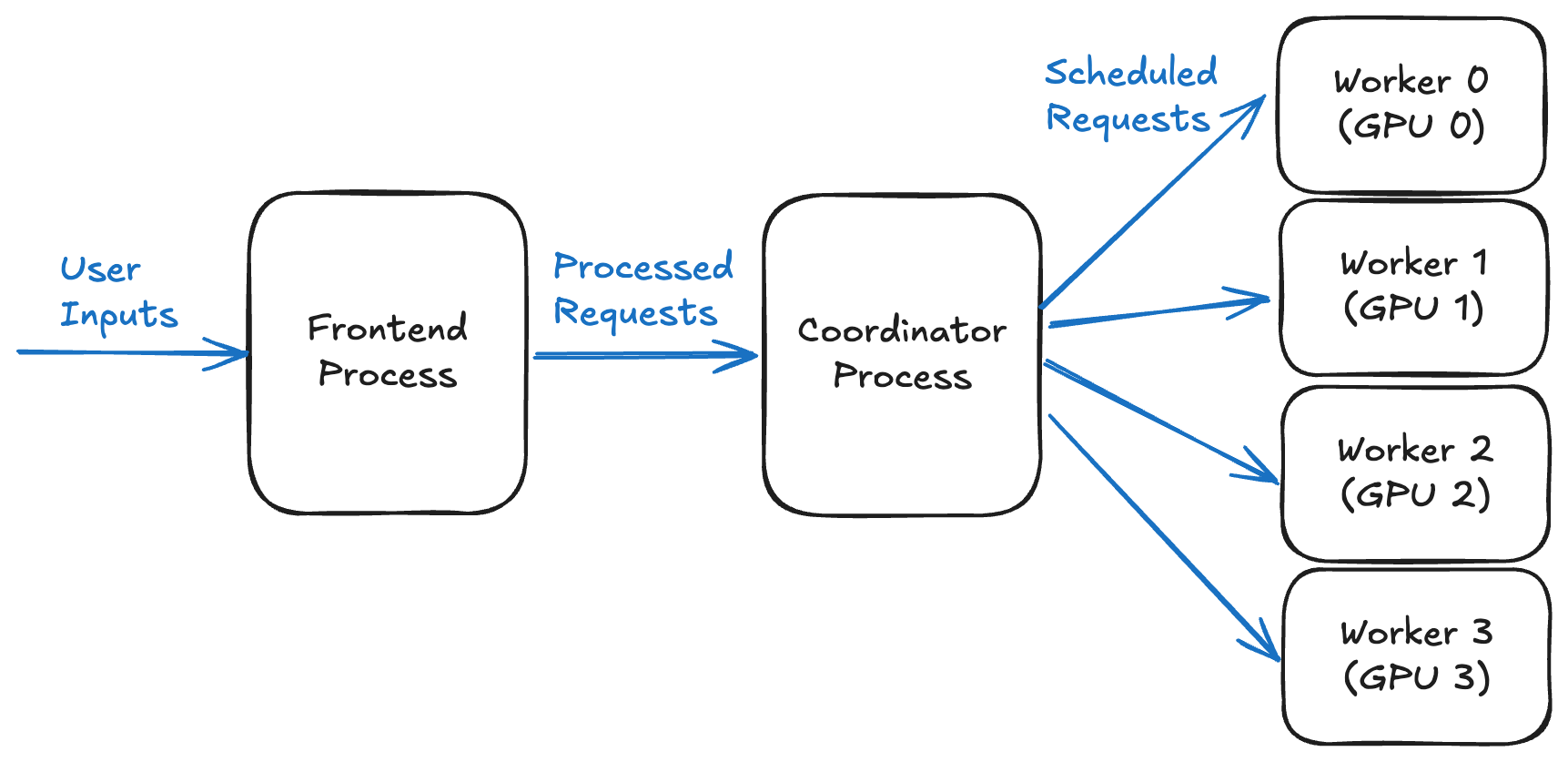
Featured
Inside vLLM: Anatomy of a High-Throughput LLM Inference System
·41 min read
How vLLM's inference engine works, covering PagedAttention, continuous batching, prefix caching, speculative decoding, multi-GPU serving, scheduling, and benchmarking for high-throughput LLM workloads.